データ活用の進め方。AI導入前に必須の「社内データ棚卸し」5ステップ

「AIツールは導入したのに、社内のデータ活用が思うように進まない」という方も多いでしょう。生成AIへの期待が高まる一方で、いざ自社の業務に当てはめようとすると「そもそも使えるデータがどこにあるのかわからない」という壁に突き当たるケースは少なくありません。
データ活用が進まない原因の多くは、AIの性能や技術選定ではなく、データそのものの所在・品質・アクセスのしやすさにあります。ここを整理しないままツールだけを導入すると、PoC(概念実証)で止まってしまい、本番運用までたどり着けません。
そこで本記事では、
- データ活用が社内で進まない構造的な理由
- 「データが存在する」と「AIで活用できる」の違い
- AI導入前に行う「社内データ棚卸し」の5ステップ
- 構造化・非構造化データの分類とAI活用難易度
- 社内データマップの作り方と、製造業での事例
についてわかりやすく解説します。AI・DXの推進を担当されている方は、ぜひ最後までご覧ください。
自社のデータ活用を何から始めればよいか整理したい方は、リベルクラフトへご相談ください。
⇨リベルクラフトへの無料相談はこちら
データ活用とは|データ分析との違いとメリット
本題の棚卸しに入る前に、「データ活用」という言葉の意味を整理しておきます。データ活用とは、社内外にあるデータを業務改善や意思決定、新しい価値の創出に役立てることを指します。データを集めて眺めるだけでなく、実際の業務や経営の判断につなげるところまでを含むのが特徴です。
データ分析とデータ活用の違い
混同されやすいのが「データ分析」との違いです。データ分析は、データから傾向や関係性を読み取る工程そのものを指します。一方、データ活用はそれを含めて、「目的を決める→データを集める→分析する→施策に反映する→効果を検証する」という一連の流れ全体を指します。つまり、データ分析はデータ活用の一部です。分析しただけで施策に結びついていなければ、データ活用ができているとは言えません。
データ活用で得られるもの
データ活用が定着すると、主に次のような効果が期待できます。
- 意思決定の精度とスピードが上がる:勘や経験だけに頼らず、事実に基づいて判断できます
- 業務の効率化・コスト削減が進む:どこに無駄があるかを数値で把握し、改善に回せます
- 新しい打ち手が見つかる:顧客の行動や現場の記録から、これまで気づかなかった課題や機会が見えてきます
ここまでは多くの企業がすでに理解している内容です。問題は、その「データ活用」がなぜ社内で動き出さないのか、という点にあります。次から、その本当の理由を見ていきます。
データ活用が社内で進まない本当の理由
データ活用に取り組む企業が増える一方で、「AIを入れたのに動かない」「分析基盤を整えたのに使われない」という相談が後を絶ちません。その背景には、技術以前の問題が隠れています。
原因は技術ではなく「データが使える状態か」
AI活用が止まる原因の多くは、モデルの精度やツールの選定ではなく、「AIが参照できるデータが整っていない」ことにあります。Gartnerは、30%以上の生成AIプロジェクトがPoC(概念実証)の後に断念されると予測しており、その要因としてデータ品質の低さ、リスク管理の不備、コスト、事業価値の不明確さを挙げています(Gartner 2024年7月予測)。
どれだけ優秀なAIを用意しても、参照するデータが古かったり、必要な情報がどこにあるかわからなかったりすれば、期待した成果は出ません。データ活用の出発点は、ツール選びの前に「自社のデータが使える状態にあるか」を確かめることです。
分散・属人化が「データ活用の課題」を生む
もう1つの理由が、データの分散と属人化です。社内のデータは、基幹システムのデータベース、ファイルサーバー、各種クラウドサービス、個人のメールやチャット、Excelファイルなど、さまざまな場所に散らばっています。
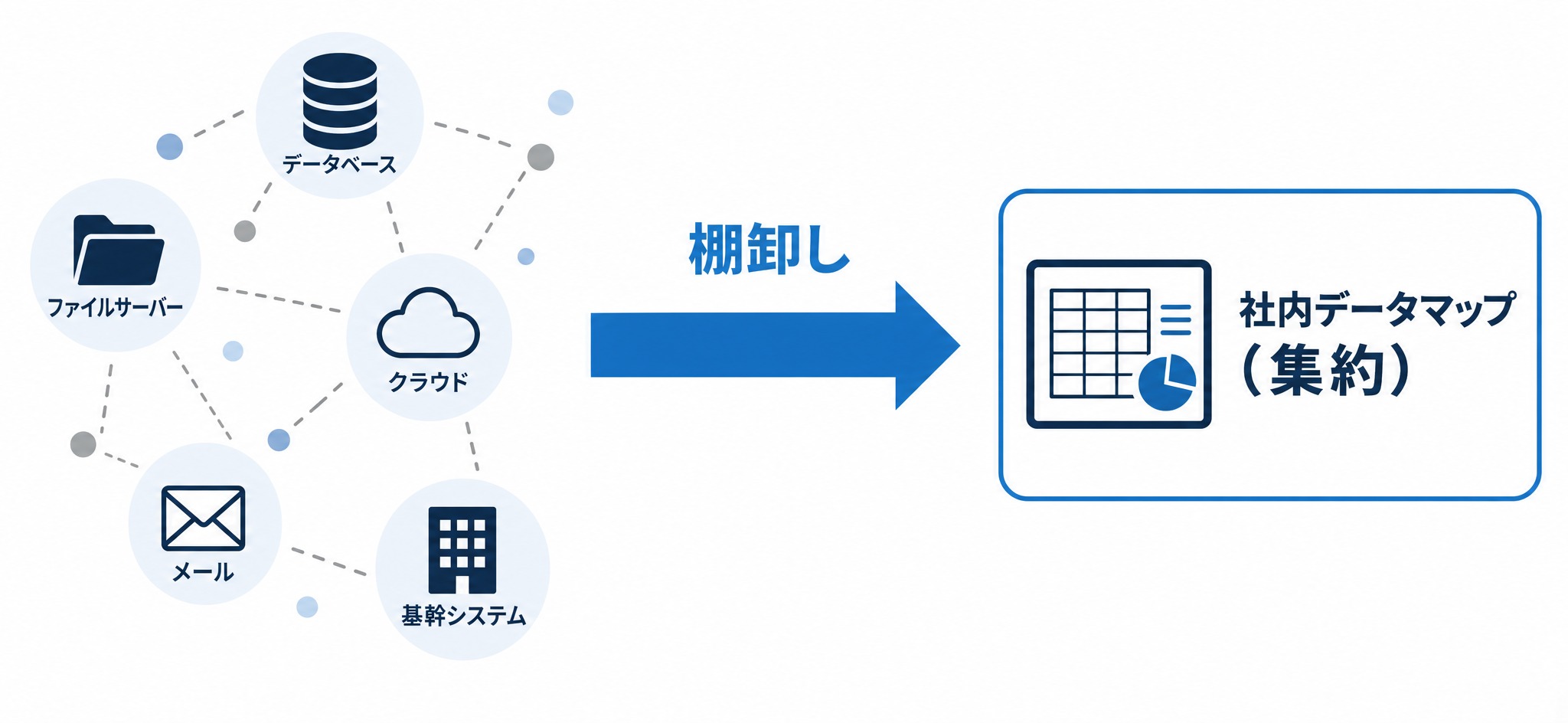
さらに、担当者の異動や退職をきっかけに「あのデータがどこにあるのか誰も把握していない」という状態に陥りがちです。データ活用の課題は、技術力の不足というより、こうした「所在の見えなさ」と「属人化」に起因していることが多いのです。
「データが存在する」と「AIで活用できる」は別物
「データならたくさんある」という企業は多くあります。しかし、データが社内に存在することと、AIで活用できることは別の問題です。
活用可否を分ける7つの観点
あるデータがAIで活用できるかどうかは、次の7つの観点で決まります。
| 観点 | 確認すること |
|---|---|
| 所在 | データがどこに保存されているか把握できているか |
| 管理責任者 | 誰が管理・更新しているか明確か |
| 形式 | データベース・Excel・PDF・画像など、どんな形式か |
| 量 | AIが学習・参照するのに足りる量があるか |
| 質 | 入力ミス・重複・欠損がなく信頼できるか |
| アクセス性 | 必要なときに取り出せる権限・仕組みがあるか |
| 整形・標準化 | 表記ゆれや単位の不統一が整理されているか |
これらが揃っていないデータは、たとえ大量にあってもそのままではAIに使えません。データ活用を進めるうえでは、まずこの7観点で自社データを見直すことが、データ整備の第一歩になります。
古い・低品質なデータが招くリスク
データの「質」と「鮮度」は、特に注意が必要な観点です。AIの世界には「ガベージイン・ガベージアウト」という言葉があります。質の低いデータを入れれば、出てくる答えも質の低いものになる、という意味です。
例えば、何年も更新されていない古いマニュアルをAIに参照させると、現状と異なる回答(ハルシネーション)を生んだり、すでに廃止された手順を案内してしまったりするリスクがあります。データ活用では「多ければよい」ではなく、「使える質と鮮度があるか」を見極めることが重要です。
AI活用前の「社内データ棚卸し」5ステップ
分散・属人化したデータを使える状態にするために、リベルクラフトがおすすめしているのが「社内データ棚卸し」です。データ棚卸しとは、自社にどんなデータがどこにあり、どれがAI活用に使えるかを洗い出して整理する作業を指します。
ここで大切なのは、最初から完璧な目録を作ろうとしないことです。棚卸しの目的は、すべてのデータを網羅することではなく、「AIプロジェクトを1つ起案できる状態」をつくることにあります。全体の6〜8割が見えれば動き出せます。整備をする前に、まず棚卸しから始めましょう。
棚卸しは次の5ステップで進めます。
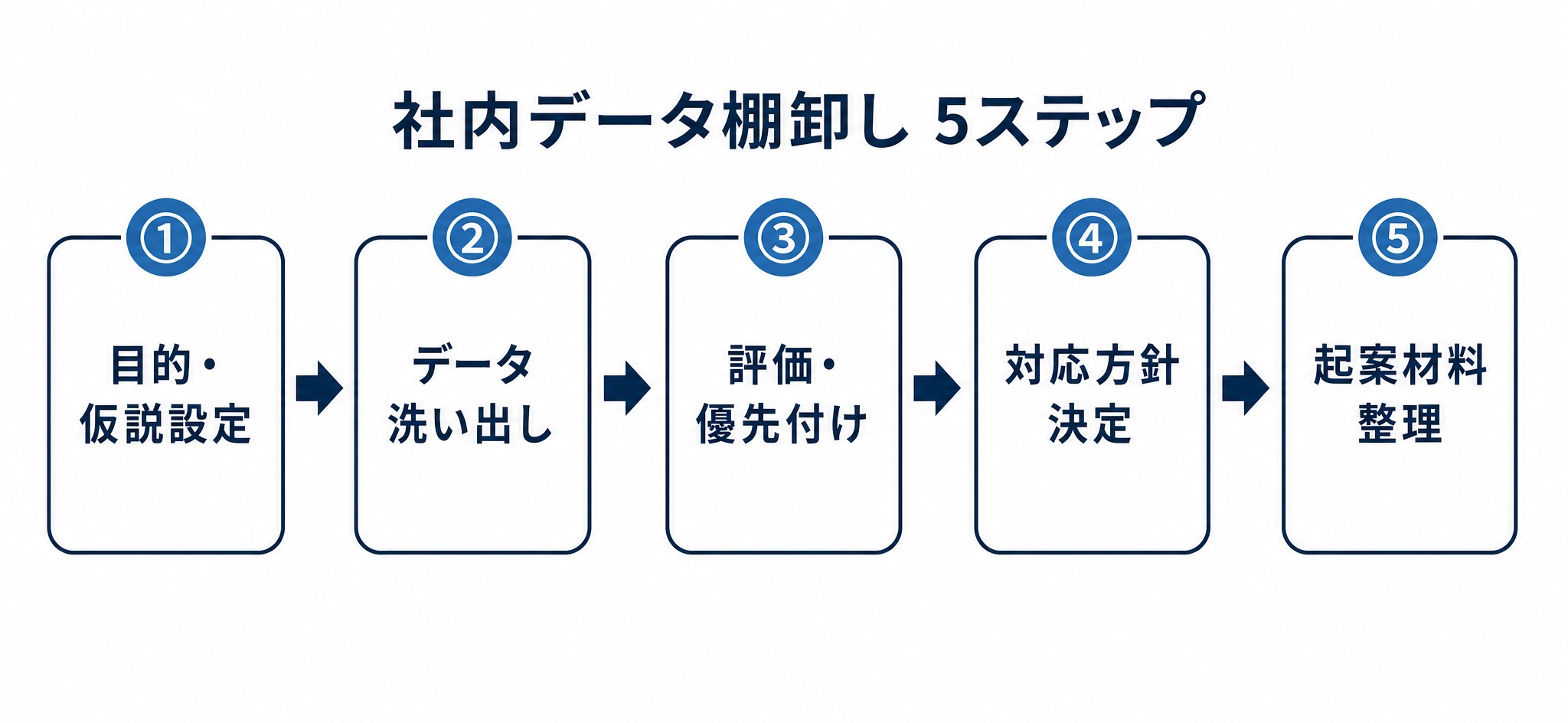
STEP1 目的・仮説を決める
最初に「何のためにデータを棚卸しするのか」を決めます。「問い合わせ対応を効率化したい」「設計ノウハウを引き継ぎたい」など、解決したい業務課題を仮説として置くと、洗い出すデータの範囲が絞れます。やみくもに全データを対象にすると、棚卸し自体が終わらなくなります。
STEP2 データを洗い出す
次に、対象とする業務で「どんなデータを、どこで、どう使っているか」を洗い出します。全社一括ではなく、業務単位で進めるのがコツです。例えば「受注処理」「クレーム対応」のように業務を起点にすると、関連するデータが自然に紐づいてきます。
STEP3 評価・優先順位をつける
洗い出したデータを、業務インパクト・品質・鮮度・アクセス性といった観点で評価し、優先順位をつけます。理想はスコアリングして数値で比較することです。「使いやすく、効果も大きい」データから着手すると、早期に成果を出しやすくなります。
STEP4 対応方針を決める
優先度の高いデータについて、「そのまま使えるか」「前処理(整形・標準化)が必要か」「権限やアクセスの整備が必要か」といった対応方針を決めます。ここで初めて、データ整備の具体的な作業が見えてきます。
STEP5 起案材料に整理する
最後に、ここまでの結果を「どのデータで、どんな課題を、どのAIアプローチで解決するか」という起案材料に整理します。この材料が、後述するAIプロジェクトの企画書の骨格になります。
繰り返しになりますが、棚卸しはスモールスタートで構いません。完璧を目指して止まるより、6〜8割の精度で動き出し、進めながら精度を上げていく進め方が現実的です。
構造化・半構造化・非構造化の分類とAI活用難易度
データ棚卸しを進めるうえで役立つのが、データを「構造化・半構造化・非構造化」の3つに分類する視点です。形式によってAIでの活用しやすさが大きく変わります。
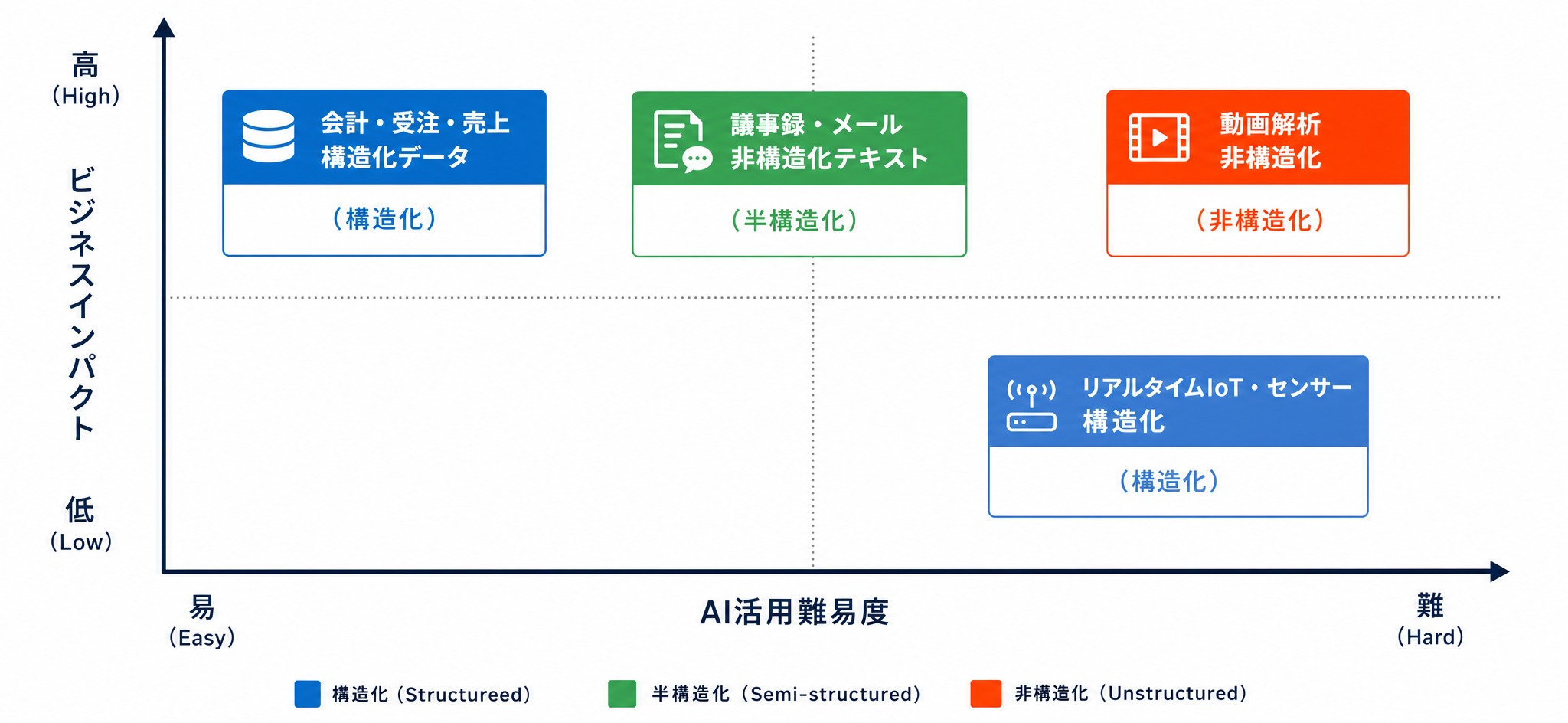
3分類の違い
| 分類 | 代表例 | 特徴 |
|---|---|---|
| 構造化データ | 基幹システムのDB・会計・受注・売上 | 表形式で整理済み。所在も把握されやすく活用しやすい |
| 半構造化データ | Excel・PDF・帳票 | ある程度の形はあるが前処理が必要。見逃されやすい |
| 非構造化データ | 議事録・メール・チャット・音声・手書きメモ・動画 | 最も認識されにくいが量が多く、ノウハウが眠っている |
構造化データは整理済みで扱いやすい一方、半構造化・非構造化データは前処理が必要なため、棚卸しの段階で見落とされがちです。
AI活用難易度はデータの中でもグラデーションがある
同じ分類の中でも、AIで活用する難易度には差があります。
- 構造化データでも、会計・受注・売上のような静的なデータは扱いやすい一方、リアルタイムのセンサーデータやIoTデータは扱いが難しくなります。
- 非構造化データでも、議事録やメールといったテキストは、RAG(検索拡張生成)で比較的取り込みやすい一方、動画解析などは難易度が高くなります。
このように、投資対効果(ビジネスインパクト)とAI活用の難易度を二軸で整理すると、「効果が大きく、かつ取り組みやすい」領域が見えてきます。データ活用は、ここから着手するのが定石です。
非構造化データは「暗黙知の宝庫」
特に注目したいのが非構造化データです。個人のPCや共有フォルダに点在するメール・議事録・手書きメモなどには、業務の判断基準やノウハウといった暗黙知が数多く眠っています。
これらは属人化の温床であると同時に、組織にとっての本当のナレッジでもあります。担当者の多忙や記録習慣の不足によって、こうした暗黙知は日々失われています。放置すれば、担当者の離脱とともにオペレーションが維持できなくなるリスクもあります。逆に、棚卸しを通じてうまく取り込めれば、競争優位の源泉になります。非構造化データに眠るノウハウをAIで形式知化する具体的な進め方は、ChatGPT×RAGで社内データを活用する手順もあわせてご覧ください。
自社のデータをどう分類し、どこから手をつけるべきか相談したい方は、リベルクラフトへご相談ください。
⇨リベルクラフトへの無料相談はこちら
社内データマップの作り方とスコアリング
棚卸しの結果を整理する具体的なツールが「社内データマップ」です。社内データマップとは、自社のデータと業務の関係を一覧化した地図のことを指します。これを作ると、どこに何があり、どれが優先かが一目でわかります。
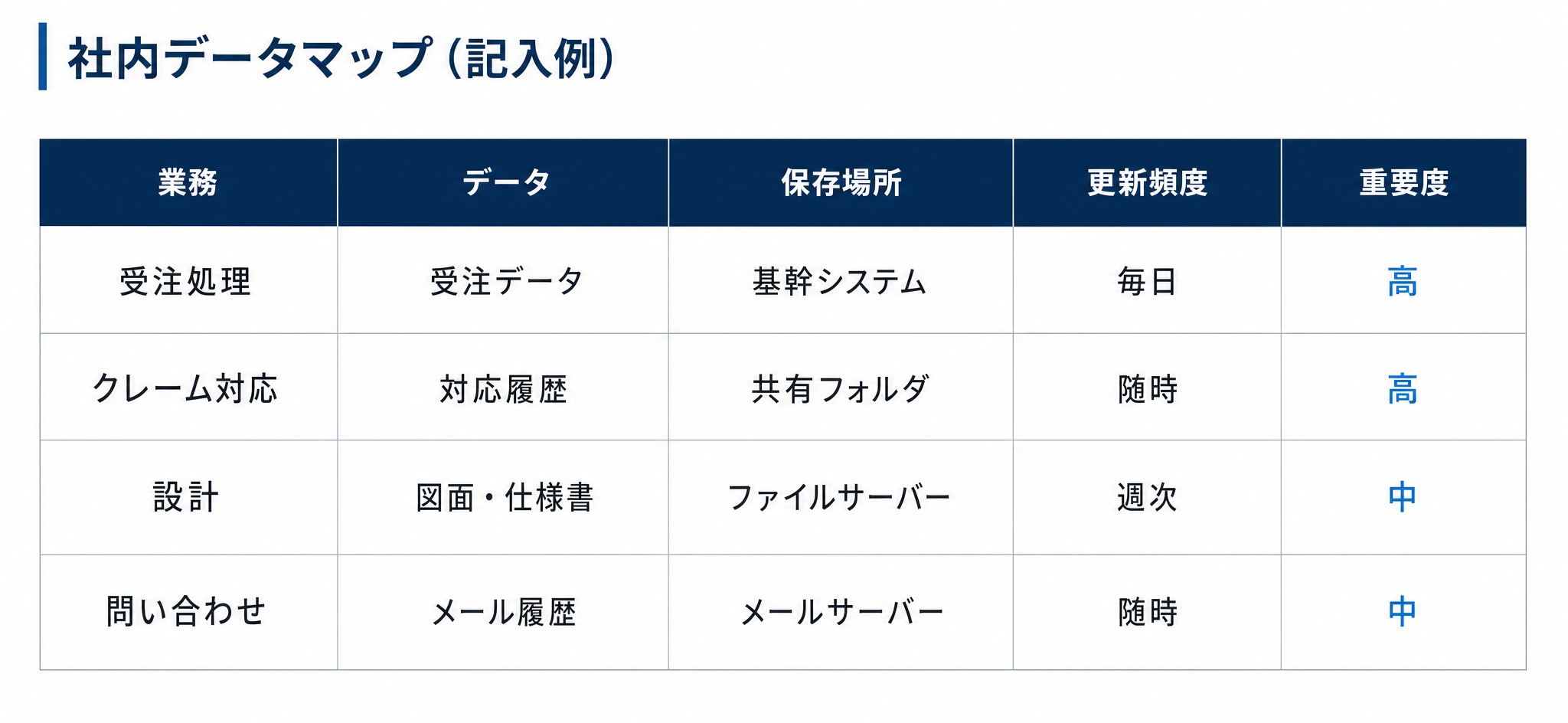
社内データマップに書く5項目
社内データマップには、最低限、次の5項目を整理します。
| 項目 | 記入する内容 |
|---|---|
| 業務 | どの業務で使うデータか |
| データ | 具体的なデータ名・種類 |
| 所在 | 保存場所(システム・サーバー・クラウド等) |
| 更新頻度 | どのくらいの頻度で更新されるか |
| 重要度 | 業務における重要度 |
業務を起点に、それに紐づくデータを書き出していくと、抜け漏れを抑えられます。
4軸でスコアリングして優先領域を決める
一覧化したデータは、次の4軸でスコアリングして優先順位を決めます。
- 業務インパクト:そのデータを活用したときの業務効果の大きさ
- 品質:入力精度・重複・欠損の少なさ
- 鮮度:データがどれだけ最新か
- アクセス性:必要なときに取り出せるか
スコアの高いデータから着手することで、限られたリソースを効果の大きい領域に集中できます。
リベルクラフトでは、この社内データマップのテンプレートをお役立ち資料として用意しています。自社の棚卸しにそのまま使える形式ですので、ぜひご活用ください。
1人で抱えず部門と分業する組織体制
社内データの全体像を1人で把握するのは現実的ではありません。IT・AI担当者が旗振り役となり、各部門に担当者を置いて分業する体制が有効です。現場の業務を知る人がデータの所在や重要度を判断することで、棚卸しの精度とスピードが上がります。
棚卸し後のAIプロジェクト起案(データ×課題×AIアプローチ)
データ棚卸しと社内データマップが整ったら、いよいよAIプロジェクトの起案に進みます。
起案は「データ×課題×AIアプローチ」の3点セット
AIプロジェクトの企画書は、次の3点を組み合わせて骨格をつくります。
- データ:スコアの高い、使いやすいデータ
- 課題:解決したい業務課題(各社のビジネスで定義する)
- AIアプローチ:課題に合った技術。社内ナレッジ検索ならRAG・ナレッジ基盤、業務自動化ならAIエージェント、需要予測なら予測モデル、文書処理なら要約・抽出
このうち、課題はビジネス側で定義でき、AIアプローチは学べばわかります。一方、データだけは棚卸ししなければわかりません。だからこそ、棚卸しが起案の前提になります。棚卸し後のデータをRAGで活用する具体的な進め方は、RAGの活用事例17選で詳しく紹介しています。
ここからは、製造業でのデータ活用の事例を2つ紹介します(いずれも内容を一般化しています)。
事例1 ある重工メーカーの暗黙知ナレッジ化
ある重工メーカーでは、熟練設計者のノウハウが口伝でしか共有されておらず、退職によって失われるリスクを抱えていました。
- Before:設計ノウハウが特定のベテランの頭の中にしかなく、若手や他部門がアクセスできない
- After:棚卸しで暗黙知を特定し、インタビューを通じて言語化・構造化。RAGによるナレッジ基盤に登録し、全社で参照できる状態に
ポイントは、いきなりAIに任せるのではなく、暗黙知を収集する棚卸しと、丁寧に言語化・構造化する工程を踏んだことです。「暗黙知の収集(棚卸し)→インタビューで言語化・構造化→RAGナレッジベースへの登録→全社展開」という順序が、この取り組みを成立させました。
事例2 ある電機メーカーのQA自動化
ある電機メーカーでは、トラブル対応の記録が各所に分散し、「どこに何があるかわからない」状態でした。
- Before:過去のトラブル対応記録が分散し、対応のたびにベテランへ問い合わせが集中
- After:棚卸しで記録を集約・整理し、AIで「事象→対処」のQAフォーマットに変換。技術者がAIに問い合わせると過去のQAを参照して診断を支援する仕組みに
非構造化データは前処理が必要ですが、棚卸しさえできれば、フォーマットへの変換はAIが担えます。結果として診断時間が短縮され、技術伝承も進みました。
要件定義できるPMスキルが社内外の協働を左右する
これらの事例に共通するのは、「データ・課題・AIアプローチ」を言語化し、要件として整理するプロジェクトマネジメント(PM)のスキルです。「なんとなくAIをやりたい」という状態から一歩進み、ビジネス要件とAI技術要件を翻訳できる人材がいると、社内エンジニア・情シス・外部ベンダーとの協働がスムーズになります。データ活用を内製化するうえで、このPMスキルの有無が成否を大きく左右します。
まとめ
データ活用を阻む最大の壁は、技術ではなくデータ側にあります。本記事の要点を整理します。
- AI活用が進まない原因の多くは、データの所在・品質・アクセス性にある
- 「データが存在する」ことと「AIで活用できる」ことは別物
- まずは社内データ棚卸しの5ステップ(目的→洗い出し→評価・優先→対応方針→起案材料)で6〜8割を可視化する
- 構造化・非構造化の分類とAI活用難易度で、着手すべき領域を見極める
- 社内データマップでスコアリングし、「データ×課題×AIアプローチ」で起案する
完璧な目録を目指す必要はありません。まずは1つの業務に絞ってデータ棚卸しを行い、AIプロジェクトを1つ起案できる状態を目指してみてください。
ウェビナー資料(ホワイトペーパー)のダウンロード
本記事のテーマ「AI活用前のデータ棚卸し」は、ウェビナーでも詳しく解説しています。社内データマップのテンプレートなど、自社の棚卸しにそのまま使えるスライド資料を無料でダウンロードいただけます。
⇨ウェビナー資料のダウンロードはこちら
データ活用・AI内製化の相談は「リベルクラフト」
リベルクラフトは、戦略・構想の立案から、AIシステムのものづくり、社内人材を育てる教育・スクールまでの3軸で、企業のAI・データ活用の内製化を支援しています。データ棚卸しや社内データマップづくりといった最初の一歩から、RAG・ナレッジ基盤の構築、社内への定着までを一貫してサポートします。社内ナレッジ活用のためのRAG SaaS「ソクラグ」もご提案できます。
「自社データはどこにあり、何がAIに使えるのか整理したい」という方は、まず現状の課題をお気軽にお聞かせください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



