ChatGPT×RAGで社内データを活用する5つの手順。精度を向上させる施策も解説

「社内の情報をChatGPTで検索・活用したいが、何から始めればよいかわからない」「RAGという言葉は耳にするけれど、実際の仕組みや自社への活かし方がイメージできない」という方も多いのではないでしょうか。
ChatGPTをそのまま使うだけでは、自社独自のマニュアルや規程、過去の問い合わせ履歴といった情報には対応できません。そこで注目されているのが「RAG」という技術です。
RAGを組み合わせることで、社内文書やFAQを検索・参照しながら、自社に合った回答をChatGPTが自動生成できるようになります。
そこで本記事では、
- RAGとは何か、どのような仕組みで動くのか
- ChatGPT×RAGで社内データを使ってできること
- 導入の具体的なステップ
- 精度を高める施策と導入時の注意点
をわかりやすく解説します。
社内データへ生成AI活用を検討している方は、ぜひ最後までご覧ください。
「社内データをRAGで活用したいが、自社での構築に不安がある」という方は、リベルクラフトへご相談ください。
リベルクラフトでは、社内データの整備・RAGの設計から構築・運用まで一貫してサポートしています。また、業務の流れに合わせた柔軟なカスタマイズにも対応できます。
まずは以下のリンクからお気軽にお問い合わせください。
⇨リベルクラフトへの無料相談はこちら
RAGとは?
RAGとは「Retrieval-Augmented Generation(検索拡張生成)」の略で、生成AIが回答を生成する前に外部のデータベースから関連情報を検索し、その内容を参照しながら答えを出す技術です。
ChatGPTなどの生成AIは、あらかじめ学習した大量のデータをもとに回答を生成するため、
- 社内規程
- 業務マニュアル
- 過去の問い合わせ履歴
などの自社独自の情報は、参照できません。
RAGを組み合わせることで、このような社内固有のデータを生成AIが検索して使える情報として扱えるようになります。
単に生成AIを使うのではなく、自社のデータを根拠に回答させることができるという点が特徴です。
情報の出どころが明確になる分、ハルシネーションを出しにくくなり、業務でも活用しやすくなり多くの企業で導入が進んでいます。
RAGの仕組み
RAGは大きく次の3つのステップで動きます。
① 検索(Retrieval) 利用者が質問を入力すると、システムはあらかじめ整備した社内文書・FAQなどのデータベースを検索し、質問に関連する文書を取り出します。
② 拡張(Augmented) 取り出した文書を関連情報として質問に付け加え、生成AIへ渡します。生成AIは自社の実際の情報を参照した状態で回答を生成できるようになります。
③ 生成(Generation) 加えられた関連情報をもとに、生成AIモデル(例:OpenAI)が回答を生成し、利用者に返します。
この流れを図にすると次のようになります。
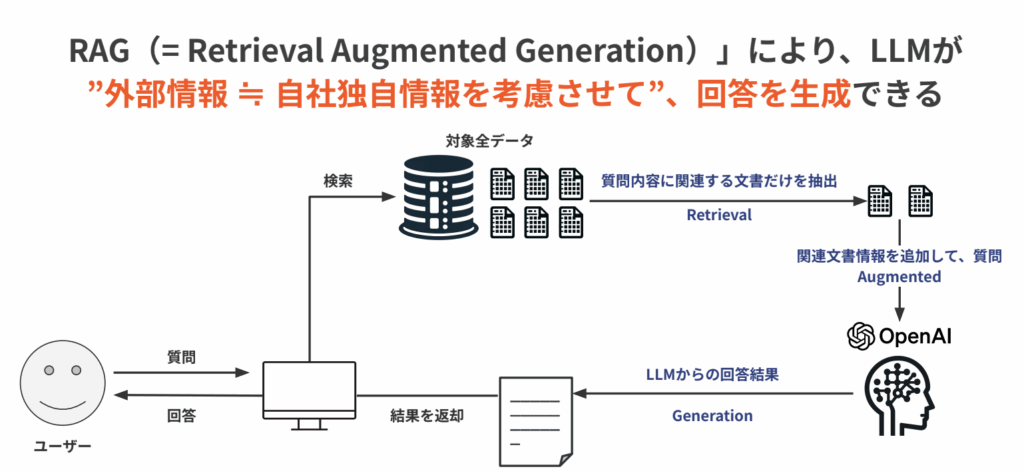
重要なのは、生成AIが学習済みの知識ではなく実際に社内にあるデータをもとに答える点です。
社内文書をデータベースとして整備すれば、一般的なChatGPTでは答えられなかった業務固有の質問にも対応できるようになります。
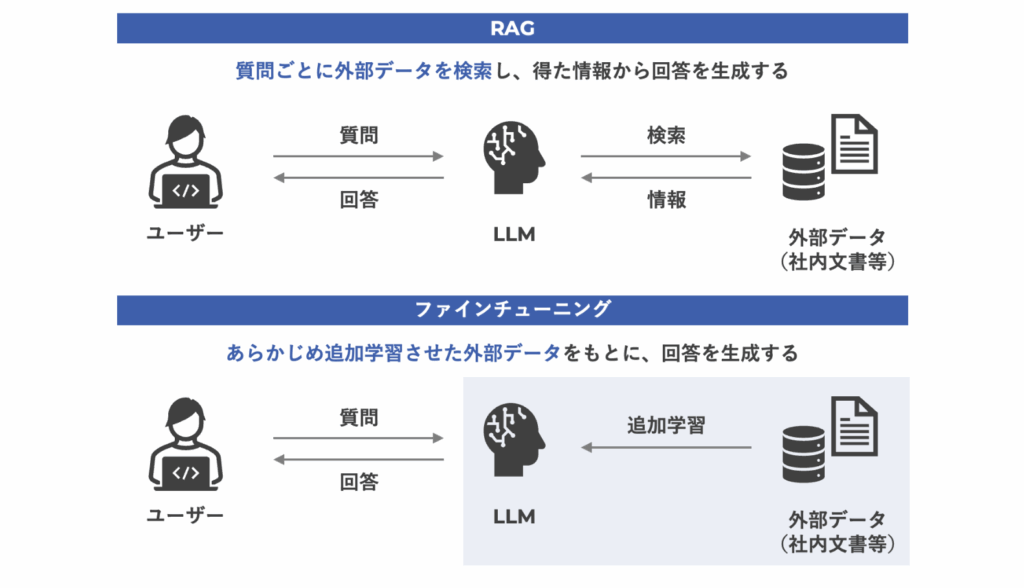
ファインチューニングとの違い
社内データを生成AIで活用する方法として、RAGのほかにファインチューニングがあります。
2つの違いは、自社データをどのように扱うかという点にあります。
| 項目 | RAG | ファインチューニング |
|---|---|---|
| 仕組み | 都度データを検索して参照する | データでモデル自体を再学習させる |
| データ更新 | データベースを更新するだけでよい | 更新のたびに再学習が必要 |
| コスト感 | 比較的抑えやすい | 1回の調整でも高コストになりやすい |
| 向いている用途 | 頻繁に更新される情報の活用 | 特定の出力スタイル・専門性の調整 |
RAGは、社内文書やFAQのように内容が変わりやすい情報の活用に向いています。
規程の改定や製品情報の追加があっても、データベースを更新するだけですぐに最新情報を反映できます。一方、ファインチューニングは生成AIモデルの出力の傾向や専門的なニュアンスを変えたいときに有効ですが、1回の調整にかかるコストと時間が大きく、情報が更新されるたびに対応が必要になります。
社内のノウハウやナレッジを生成AIに参照させたいという目的であれば、更新のしやすさとコストの面からも、RAGの方が活用しやすいといえるでしょう。
RAGで社内データを活用してできること
RAGは、社内に蓄積されたさまざまなデータを検索対象にすることで、業務の幅広い場面で活用できます。
ここでは代表的な4つの用途を紹介します。
- 社内文書検索の効率化
- 社内FAQや問い合わせ対応の自動化
- 社内ナレッジの共有
- 新人教育や業務引き継ぎ
社内文書検索の効率化
RAGを使うと、部署をまたいで散在している社内文書をまとめて検索し、質問に合う情報をすばやく取り出せるようになります。
これまで、社内情報を探すには、どのフォルダに何があるかを把握している担当者に聞くか、大量のファイルを手作業で確認するしかありませんでした。
特に、複数部署にまたがる情報や、数年前に作成された文書は見つけるだけで時間を取られます。
RAGの構築によって、こうした文書を一括でデータベースに登録することで
- ○○製品の仕様変更はいつ行われたか
- △△手続きの承認の流れはどうなっているか
普通の言葉で質問するだけで関連文書をまとめて取り出せるため、情報収集にかかる時間を大幅に短縮できます。
社内FAQや問い合わせ対応の自動化
社内ヘルプデスクや顧客対応窓口では、似たような問い合わせが何度も寄せられます。
たとえば、
- 社内システムの使い方
- 製品仕様の確認
- 申請手続きの流れ
など、回答内容がある程度決まっているにもかかわらず、担当者が毎回資料を探して返信しているケースは少なくありません。
RAGを構築すれば、FAQデータやマニュアル製品ドキュメントなどを検索対象にし、問い合わせ内容に近い情報を自動で参照できます。生成AIが関連文書をもとに回答案を作成するため、担当者はゼロから文章を考える必要がなくなります。
社内ナレッジの共有
社内ナレッジの共有で課題になりやすいのは、「情報がないこと」ではなく、「どこにあるのかわからないこと」です。
議事録や手順書などは存在していても、保管場所が分散していたり、ファイル名だけでは中身を判断できなかったりすると、必要な情報にたどり着くまでに時間がかかります。
このような状況でRAGを活用すると、複数の社内文書を横断的に検索し、質問内容に応じて必要な情報を取り出せるようになります。たとえば、
- 過去に同じトラブルが起きたとき、どう対応したのか
- この業務の判断基準はどの資料に書かれているのか
といった確認がしやすくなります。
また、特定の担当者だけが知っているノウハウも、文書化して検索対象に含めておけば、組織全体で活用しやすくなります。ベテラン社員の経験や過去の判断プロセスを、個人の記憶に頼らず参照できる点はメリットです。
新人教育や業務引き継ぎ
新人や引き継ぎ担当者が必要な情報をすぐに確認できる環境をつくるために、「研修資料」「マニュアル」「過去の議事録」「社内FAQ」などもまとめて検索対象にすることができます。
「何かわからないことがあれば聞いて」という体制では、質問するタイミングを逃したり、担当者が不在で業務が止まったりすることも起こりえます。
RAGを活用すると、社内に蓄積された情報を24時間参照できるため、時間や担当者に縛られずに必要な知識を得られます。
業務引き継ぎの際も、引き継ぎ資料だけでは伝わりにくい背景情報や判断の経緯を、過去の議事録や報告書から探し出して確認できるため、引き継ぎの質も上がります。
RAGに活用しやすい社内データの例
RAGはどんな文書でも使えるわけではなく、文字として整理されており、検索して参照できる状態にある情報が活用しやすいデータです。
ここでは、特に効果を出しやすい4種類の社内データを紹介します。
- 就業規則・社内規程
- 業務マニュアル・手順書
- 社内FAQ・問い合わせ履歴
- 議事録・ナレッジ集・報告書
就業規則・社内規程
就業規則や各種社内規程は、RAGとの相性がよいデータの代表例です。
内容が文書として書かれており、「この場合はどのルールが適用されるか」といった質問に対して、該当する箇所を参照しながら回答を生成しやすい形になっています。
たとえば、人事・総務への問い合わせで多いのが
- 有給休暇の取得ルールはどうなっているか
- 育児休業の申請手続きを知りたい
といった規程に関する内容です。
担当者が毎回同じ説明を繰り返す手間を減らせるだけでなく、従業員自身がいつでも確認できるようになります。
改定をおこなう際も、データベースを更新するだけで最新の内容を反映できるため、古い情報が残ったまま使われるというリスクを抑えることができます。
業務マニュアル・手順書
業務マニュアルや手順書は、業務の進め方や判断の基準が文書としてまとめられているため、RAGの検索対象として扱いやすいデータです。
特に効果が出やすいのは、複数の手順が絡み合う複雑な業務や、例外的な対応が多いフローです。
担当者が「この状況ではどの手順を参照すればよいか」と迷う場面で、RAGを使えばその場で正確な手順を引き出すことができます。
また、部署ごとに別々に管理されているマニュアルをひとつにまとめてRAGに組み込むことで、あの資料はどこにあるかと探す時間そのものをなくすこともできます。
社内FAQ・問い合わせ履歴
過去に蓄積された社内FAQや問い合わせ対応の履歴は、実際の業務で生じた疑問とその答えがセットになっているため、RAGで活用しやすいです。
よく繰り返される質問とその回答が整理されたFAQは、そのままRAGの検索対象として組み込めます。
一方、問い合わせ履歴は整った形になっていないことも多いですが、回答の表現や判断の傾向を活用することで、より実務に近い回答の生成につながります。
新人や異動してきた担当者が「こんなときどう答えればよいか」と迷う場面でも、過去の対応事例をもとにした回答をすぐに参照できるため、対応品質のばらつきも抑えられます。
議事録・ナレッジ集・報告書
議事録、ナレッジ集、定期報告書などは、社内の意思決定の流れや現場で得られた知見が記録されているデータです。
日常的に蓄積される一方、後から参照されることが少なく、活用されずに眠っているケースが多い情報でもあります。
RAGを使うことで、こうした文書をまとめて検索できるようになります。
- この案件の方針はいつ決まったのか
- 過去に同様の問題が起きたときどう対処したか
といった問いに対して、関係する記録を探し出して回答を生成することが可能です。
RAGを通じてこれらを検索・活用できる状態にすることで、ベテラン社員に聞かなければわからなかった情報を、誰でも引き出せるようになります。
ChatGPT×RAGで社内データを活用する5つのステップ
ChatGPT×RAGで社内データに活用するには、データの整備からシステムの構築、動作確認まで段階的に進めることが重要です。
実際に導入を進める際の流れを5つのステップに分けて解説します。
- RAGで活用したい社内データを選定する
- OpenAI APIの取得
- データベースの用意
- ChatGPTと連携する
- 回答の出力と確認
1.RAGで活用したい社内データを選定する
最初に行うのは、RAGに読み込ませる社内データの選定です。
選定の基本的な考え方は、「よく参照されるが探しにくい情報」から始めることであり、全社のデータを一度に整備しようとすると準備の負担が大きくなります。
特定の部署や業務に絞り、効果が出やすいデータの範囲で小さく始めるのが現実的です。
選定時に確認しておきたいポイントは以下のとおりです。
- 文字データとして読み取れる形式か(PDFやWord、スプレッドシートなど)
- 内容が最新の状態に保たれているか
- 情報の機密レベルの確認と、誰に参照させてよいかの整理ができているか
- 内容が重複したり食い違ったりしている文書が混ざっていないか
今回は、以下の経理業務におけるマニュアルを用います。

社内データの整理や分析方法について詳しく知りたい方は、以下の記事もあわせてご覧ください。
2.OpenAI APIの取得
ChatGPTをRAGと連携させるためには、OpenAIが提供するAPIキーの取得が必要です。
APIとは、外部のシステムからOpenAIの生成AIモデルを呼び出すためのものです。
取得の流れは以下のとおりです。
- OpenAIの公式サイトでアカウントを作成する
- 管理画面からAPIキーを発行する
- 利用・料金の上限を設定する
APIの利用は使った量に応じて費用が発生する仕組みで、やり取りしたテキスト量に応じて課金されます。
最初は上限を低めに設定しておくと、想定外のコスト増を防ぎやすくなります。
また、発行したAPIキーは外部に流出しないよう、サーバーの設定ファイルなど外から見えない管理が必要です。
3.データベースの用意
RAGでは、社内文書を「ベクトルデータベース」と呼ばれる形式で格納します。
ベクトルデータベースとは、文章の意味を数値の並びに変換して保存する仕組みで、意味の近い文書を素早く検索するために使われます。
経理業務における一部分のベクトルデータベース例は以下です。
【ベクトルデータベース例】
{
“id”: “keiri_manual_003”, “document_id”: “keiri_manual_v1”, “title”: “経理の簡易マニュアル(サンプル)”, “section”: “4-1.請求書の受領・確認”, “chunk_index”: 3, “text”: “請求書を受領したら、宛名、請求日、支払期日、金額、振込先を確認します。発注書・納品書・契約内容と照合し、問題がなければ支払申請へ回します。不備があれば取引先または社内担当者へ確認します。確認ポイントは、宛名が自社名か、二重請求ではないか、消費税計算に誤りがないか、振込先情報に変更がないかです。”, “keywords”: [“請求書”, “受領”, “確認”, “支払期日”, “振込先”, “二重請求”, “消費税”], “source_type”: “manual”, “department”: “経理”, “language”: “ja”, “embedding_model”: “text-embedding-3-large”, “embedding”: [0.0642, -0.0312, 0.1175, 0.2059, -0.0877, 0.0114, 0.0288, -0.0521]
}
データベースを用意する際の流れは以下のとおりです。
- 社内文書を文字データとして読み込む
- 適切な単位に分割する
- 各チャンクを意味を表す数値データに変換する
- ベクトルデータベースに格納する
分割は細かすぎると前後の文脈が失われ、大きすぎると関係の薄い情報になってしまうため、文書の種類に合わせた調整が必要です。
4.ChatGPTと連携する
データベースの準備ができたら、ChatGPTと連携する仕組みを構築します。
具体的には、利用者の質問をもとにデータベースを検索し、取り出した文書をChatGPTへの指示文に含めて送信する一連の流れを構築します。
連携の仕組みを構築する方法は一から開発する方法やDifyなどのノーコードツールや生成AIプラットフォームを使う方法もあります。
Difyはコードを書かずにRAGの構築・管理ができるため、エンジニアでなくても導入しやすいのが特徴です。
以下は、Difyで構築した時のワークフローになります。
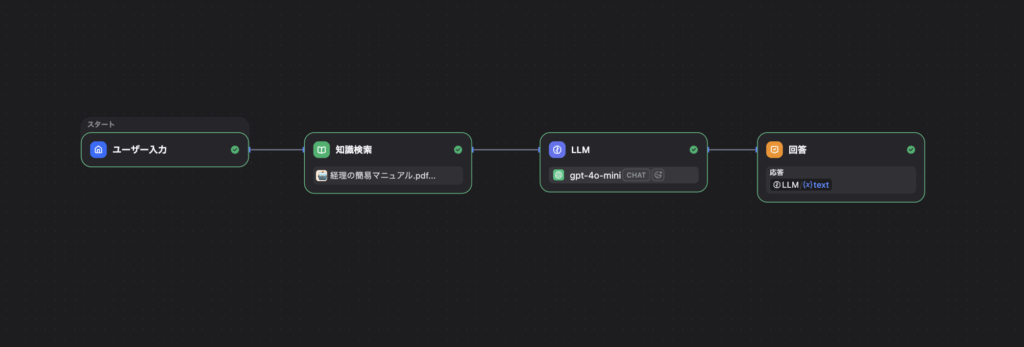
自社の技術的なリソースや運用体制に合わせて、どのアプローチが現実的かを判断することが重要です。
5.回答の出力と確認
システムが構築できたら、実際に質問を入力して回答の精度を確認します。
期待どおりの回答が返ってくるかを確かめ、問題があれば原因を特定して調整を加えていきます。
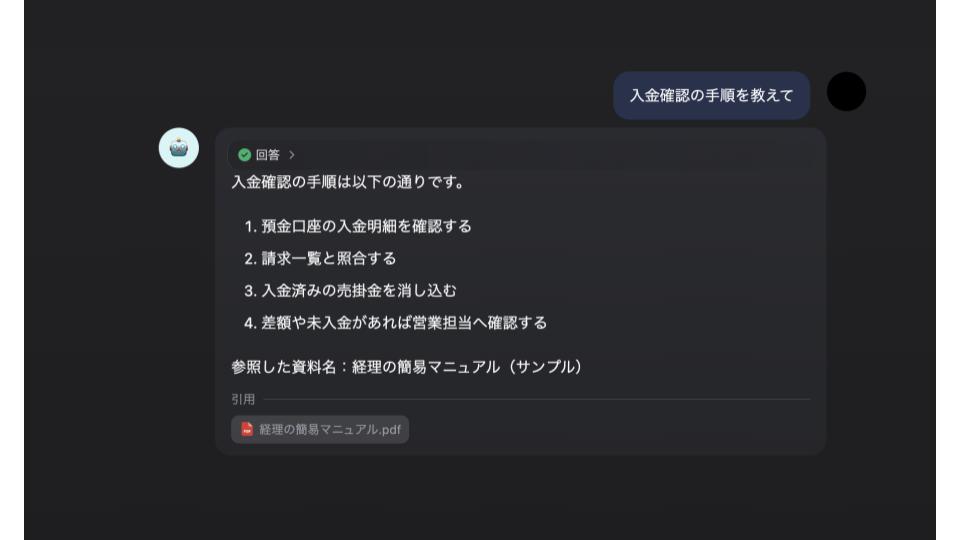
今回は、「入金確認の手順を教えて」という質問に対して、以下のマニュアルの該当部分を生成AIが参照し回答しているため成功です。

確認時に見ておきたいポイントは以下のとおりです。
- 正しい文書が参照されているか(検索精度の確認)
- 回答が根拠のある内容になっているか(誤情報が含まれていないか)
- 回答の内容や文体が業務用途に合っているか
- 想定していない質問に対して適切に「わからない」と返せるか
最初から完璧な精度を目指すより、小さな範囲で動かしながら改善を繰り返すほうが現実的です。
Difyを活用したRAGシステムの構築方法や事例について詳しく知りたい方は、以下の記事もあわせてご覧ください。
参照記事:DifyとRAGで実現するAIシステム高速開発ガイド 〜成功事例から学ぶ具体的開発手法〜
ChatGPT×RAGで社内データを活用するには、データ整備やシステム設計など、専門的なノウハウが必要な場面が多くあります。
「自社だけで進めるのが難しい」と感じている方は、まずは以下のリンクからお気軽にリベルクラフトへご相談ください。
⇨リベルクラフトへの無料相談はこちら
RAGの精度を向上させる施策
RAGを導入しても
- 期待どおりの回答が返ってこない
- 的外れな文書が参照されている
といったケースは珍しくありません。
精度が上がらない原因の多くは、生成AIモデルの性能ではなく、データの整え方と検索の設計にあります。
ここでは、精度向上に効果的な3つの施策を紹介します。
- 社内文書の前処理とチャンク分割を最適化する
- メタデータを整備して検索しやすくする
- キーワード検索とベクトル検索を組み合わせる
社内文書の前処理とチャンク分割を最適化する
RAGの精度は、文書に不要なノイズが多かったり、分割の単位が合っていなかったりすると、質問に関係する情報がうまくヒットせず、回答がずれやすくなります。
前処理のポイントとしては、
- 不要な記号・ページ上下の余白情報・重複した内容を取り除く
- 崩れたレイアウトや文字化けを修正する
- 表やリストが意味のある形で文字データに変換されているかを確認する
のような点を押さえておくことが重要です。
チャンク分割では、長い文書を細かく切りすぎると前後のつながりが失われ、大きすぎると関係の薄い情報が混ざってしまいます。
回答精度を担保するためには、固定サイズでチャンク分割するのではなく、セクションごとにチャンク分割することが有効です。目安としては、1つの区切りがひとつの意味のまとまりとして成立する最小単位になるよう調整することです。
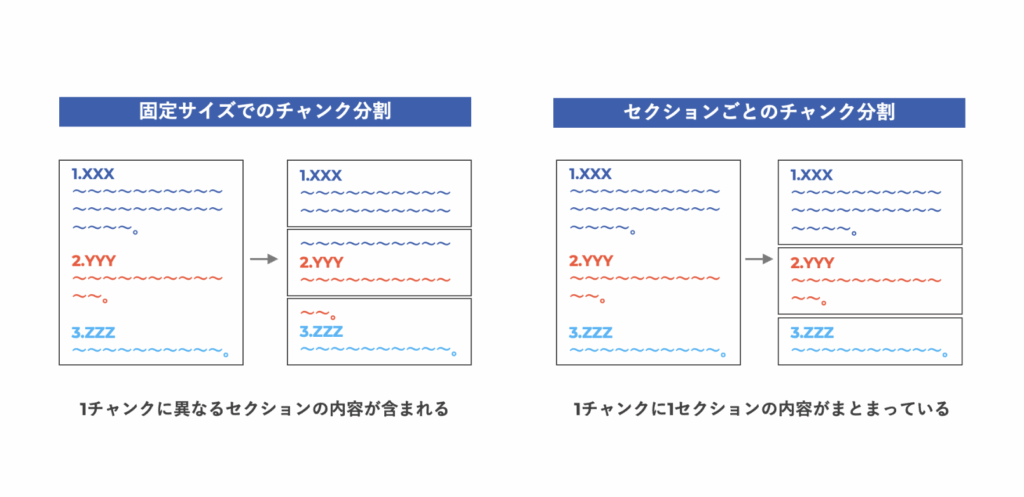
たとえば、マニュアルであれば手順ごとに区切る、FAQであれば質問と回答のセットをひとまとまりにするといった形が基本です。
メタデータを整備して検索しやすくする
社内文書は、同じテーマでも部署ごとに表現が異なったり、似た名称の資料が複数存在したりするケースが多くあります。
文書の本文だけで検索すると見落とすことも起こりやすくなるため、文書に属性情報であるメタデータを付け加えることが有効です。
代表的なメタデータは、以下のような項目です。
| メタデータの例 | 用途 |
|---|---|
| カテゴリ・文書の種類 | 対象範囲を絞り込む |
| 関連部署・対象製品 | 検索対象を特定の領域に限定する |
| 作成日・更新日 | 最新の文書を優先して参照させる |
| 機密レベル | 閲覧できる範囲の管理に活用する |
たとえば「2024年以降に更新された営業部門向けの手順書」のように、複数の条件を組み合わせた検索ができるようになります。
また、部署ごとに管理ルールが異なる場合は、まず共通のタグを整理してから整備を進めると、後から追加・修正がしやすくなります。
キーワード検索とベクトル検索を組み合わせる
RAGの検索には、大きく分けて
- キーワード検索
- ベクトル検索
の2つの方式があります。
それぞれに得意・不得意があるため、組み合わせて使う「ハイブリッド検索」が精度向上に有効です。
| 項目 | キーワード検索 | ベクトル検索 |
|---|---|---|
| 仕組み | 入力した語句と一致する文書を探す | 文章の意味を数値に変換して比較する |
| 得意な質問 | 製品名・エラーコード・型番など明確な語句を含む質問 | 普通の言葉での質問や、意味が近い別の表現での質問 |
| 弱点 | 言い換えや表現の揺れに対応できない | 固有名詞や数字の完全一致には向いていない |
この2つを組み合わせた「ハイブリット検索」では、それぞれの弱点を補いながら、より広い範囲の質問に対して精度の高い検索ができるようになります。
実際の運用では、両方の検索結果に点数をつけてまとめる手法なども活用されています。
RAGの精度向上施策や具体的な活用事例について詳しく知りたい方は、以下の記事もあわせてご覧ください。
参照記事:RAGの精度向上施策・事例紹介 〜成功事例からRAGの具体的活用方法を学ぶ〜
社内データにRAGを導入する際の注意点
RAGは社内データを生成AIに活用するうえで有効な技術ですが、導入すれば自動的にうまくいくわけではありません。
事前に把握しておくべき注意点が3つあります。
- 社内データの質が低いと回答精度も上がりにくい
- アクセス権限の設計を誤ると情報漏洩リスクがある
- 最新情報を反映する更新フローが必要になる
社内データの質が低いと回答精度も上がりにくい
RAGは社内データを検索して回答を生成する仕組みであるため、参照元のデータの質が回答の質を左右します。
内容が古い、重複している、表現が曖昧、誤記が多いといった状態のデータを使ってしまうと、精度の高い回答は生成できません。
データの質を高めるためには、以下のような取り組みが効果的です。
- 古いマニュアルや規程を見直し、最新の内容に書き直す
- 部署ごとにバラバラに存在する資料をまとめ、同じ内容が重ならないように整理する
- 口頭で変更したルールや手順は、テキスト化するようにする
- わかりにくい表現や間違いを直し、誰が読んでも伝わる内容に整える
また、データの整備は導入前に一度やれば終わりではなく、業務のやり方が変わったり規程が改定されたりするたびに見直す必要があります。
アクセス権限の設計を誤ると情報漏洩リスクがある
社内のさまざまな文書をRAGに活用する場合、誰がどの情報を参照できるかの設計を誤ると、意図しない情報の漏洩につながるリスクがあります。
たとえば、役員や人事担当者しか閲覧を想定していない給与情報や評価記録、経営会議の議事録なども、RAGのデータベースに入れてしまえば、そのシステムを使える社員なら誰でも参照できてしまいます。
そこで、
- 誰がどの文書を検索できるか:部署・役職・担当業務に応じた閲覧範囲の制限
- どの情報を回答に含めてよいか:検索でヒットしても、回答として出してよい情報かどうかのルール整備
というの2点の設計を押さえておく必要があります。
最新情報を反映する更新フローが必要になる
RAGは、データベースに登録された情報をもとに回答を生成するため、データベースの情報が古いと、古い情報にもとづいた回答になってしまいます。
たとえば、就業規則が改定されたにもかかわらずデータベースが更新されていない場合、旧ルールを正しいものとして生成AIが回答し続けるリスクがあります。
RAGを導入する際は、
- 文書更新のタイミングで担当者がデータベースに反映する手順を決めておく
- 更新状況を定期的に確認する見直しの仕組みを設ける
- 古いバージョンの文書が残り続けないよう、削除・上書きのルールを明確にする
など文書の更新サイクルに合わせてデータベースもその都度更新できる運用が必要です。
RAGのセキュリティや運用管理について詳しく知りたい方は、以下の記事もあわせてご覧ください。
参照記事:RAG構築におけるセキュリティリスクと5つの対策方法。対策が必要な理由も紹介
社内データを活用したRAGの構築は「リベルクラフト」
ここまで、RAGの仕組みや社内データへの活用方法、導入ステップ、精度向上の施策、注意点まで幅広く解説してきました。
RAGは社内データを活かすうえで有効な技術ですが、データの整備設計・検索の最適化・閲覧権限の管理・更新フローの構築など、実際に成果を出すには専門的なノウハウが必要な場面が多くあります。
- 自社のデータ整備や構築を誰に頼めばよいかわからない
- 導入後の運用まで見てもらえる会社に相談したい
という方は、リベルクラフトへお気軽にご相談ください。
リベルクラフトでは、社内にあるデータを生成AIが参照・活用できる状態へと整えるところから支援しています。
RAGの構築にあたっては、データの見直しと品質確認、文書の分割設計、補足情報の整備、閲覧範囲の設計まで、業務要件に合わせて一から設計します。
さらに、構築して終わりではなく、精度の検証と継続的な改善まで含めた運用設計を一体で提供しているため、「入れたけど使われない」という状態を防ぐことができます。
社内データをRAGで本当に活用できる仕組みにしたいとお考えの企業は、まずは以下のリンクからお気軽にお問い合わせください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



