
RAGの精度向上とは?
RAGの精度向上とは、ユーザーの質問に対して、必要な情報を正しく検索し、その根拠をもとに適切な回答を生成できる状態へ改善することです。
RAGは、LLM単体で回答するのではなく、社内文書やFAQ、マニュアルなどの外部データを検索し、その内容を参照して回答を作ります。
しかし、
- 参照するデータが古い
- チャンク分割が適切でない
- 検索キーワードと文書の表現が合っていない
などの問題があると、回答の抜け漏れや誤回答が発生しやすくなります。そのため、RAGの精度向上では、モデル性能だけに頼るのではなく、総合的に見直すことが重要なのです。
RAGは外部データを検索して回答精度を高める仕組み
RAGは、外部データを検索し、その情報をもとに回答を生成する仕組みです。
下記の図のように、まず各種データをナレッジデータベース化し、ユーザーから質問が送られると、システムが検索クエリを作成し、関連情報を取得します。
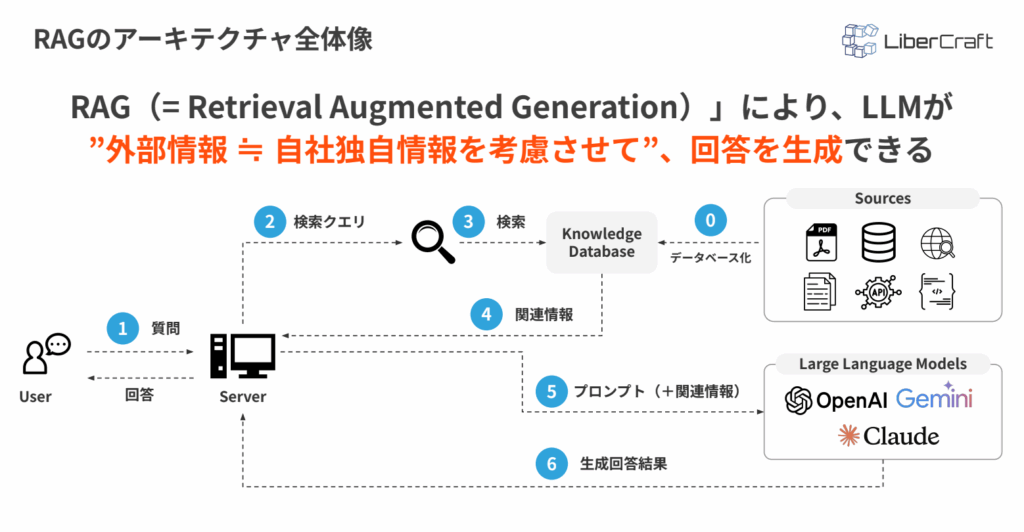
その後、取得した関連情報をプロンプトに含めてLLMへ渡すことで、LLMは自社独自の情報やナレッジベースに登録・更新された業務データを踏まえた回答を生成できます。
これにより、LLMがもともと学習していない社内情報にも対応しやすくなり、回答の根拠性や実務での使いやすさを高められます。RAGは、外部データの検索精度とLLMの生成能力を組み合わせることで、回答精度を向上させる技術です。
RAGの精度は「検索精度」と「回答精度」に分けて考える
RAGの精度を高めるには、回答全体を一括で改善しようとするのではなく、「検索精度」と「回答精度」に分けて原因を切り分けることが重要です。回答が不正確な場合でも、原因が、
- 必要な情報を検索できていない
- 検索できた情報をうまく回答に反映できていない
のかで、改善策は変わります。
検索精度
検索精度とは、ユーザーの質問に対して、ナレッジデータベースの中から回答に必要な情報を正しく取り出せているかを示す精度です。
たとえば、社内マニュアルに正しい情報が存在していても、「検索クエリが曖昧」「チャンク分割が不適切」などの原因があると、LLMに渡すべき関連情報を取得できません。
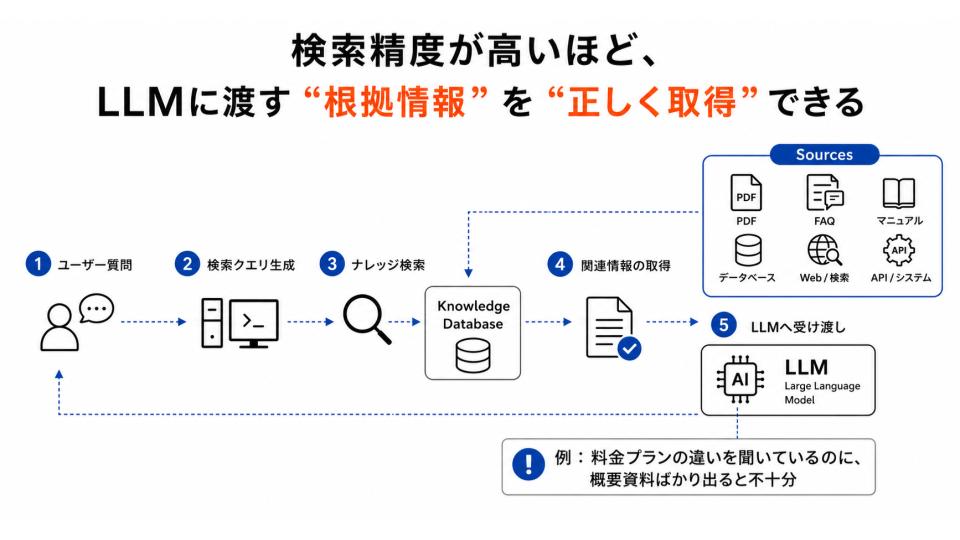
特に重要なのは、検索精度は「検索結果の多さ」ではなく、質問意図に対して有効な根拠が含まれているかで判断する点です。
たとえば、ユーザーが「料金プランの違い」を聞いているのに、料金表ではなくサービス概要資料ばかり取得している場合、検索結果は一見関連していても、回答に必要な情報としては不十分です。
つまり検索精度は、RAGにおける回答の前提品質を決める工程であり、この段階で必要な情報を取得できないと、後の回答生成では修正しきれない問題が発生します。
回答精度
回答精度とは、検索によって取得した関連情報をもとに、LLMがユーザーの質問意図に沿って、正確かつ実務で使える回答を生成できているかを示す考え方です。
検索精度が「材料を正しく集める力」だとすれば、回答精度は「集めた材料を正しく解釈し、目的に合った形で出力する力」といえます。
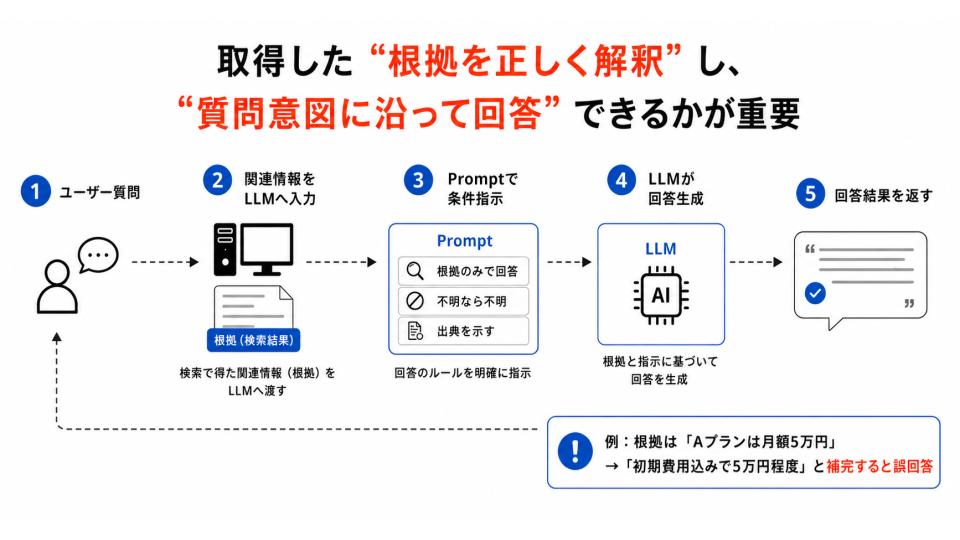
回答精度で重要なのは、LLMが文章を作れているかではなく、取得した根拠に忠実に回答できているかです。
たとえば、検索結果には「Aプランは月額5万円」と明記されているのに、LLMが文脈を補いすぎて「初期費用も含めて5万円程度」と回答してしまえば、文章として自然でも業務上は誤回答になります。
根拠にない内容を補完すること自体がリスクになるため、回答の自然さよりも、根拠との整合性や説明責任が重視されます。
RAGの精度が低くなる主な原因
RAGの精度が低い場合、構築時の設計やデータ整備、運用に原因があることが多くあります。ここでは、精度が低くなる原因を4つ紹介します。
- 検索対象のドキュメント品質が低い
- チャンク分割が文書の意味構造に合っていない
- 検索方式が質問内容に合っていない
- プロンプト設計が曖昧で回答がブレる
検索対象のドキュメント品質が低い
RAGは参照した資料をもとに答える仕組みなので、出力の質は検索対象のドキュメント品質に左右されます。古い情報・誤情報・重複・表記揺れが混じった参照データ群では、誤った文書を関連情報として取得すると、LLMはその内容を根拠として回答します。
さらにPDFやスキャン文書から文字を抽出する際にレイアウト崩れやOCRノイズが入ると、文章の意味を数値化した埋め込みベクトルが本来の意味からズレてしまい、意味ベースの検索が前提から崩れます。
図表・脚注・ヘッダーフッターなど本文以外の要素の混入もノイズ源です。前処理でのクレンジングや重複排除、メタデータ付与、鮮度管理を怠ると、後段をいくら最適化しても精度の上限が低く固定されてしまいます。
チャンク分割が文書の意味構造に合っていない
RAGでは、長い文書はそのままだと検索やLLMへの入力に適さない場合が多いため、チャンクに分割して保管しますが、この切り方が雑だと精度が落ちます。
仮に固定長で機械的に区切ると、
- 1つの論理単位が複数チャンクに分断される
- 無関係な内容が同居する
などの精度低下要因が発生します。すると埋め込みベクトルが複数の意味を平均化した「ぼやけた」表現になり、質問との類似度が正しく計算されません。
特に「定義と説明」「見出しと本文」「表とそのキャプション」が切り離されると、検索でヒットしても文脈が欠落し、AIが正確に解釈できなくなります。粗すぎればノイズが増え、細かすぎれば文脈が失われるため、文書の性質に応じた調整が欠かせません。
社内文書をRAGで活用するには、単にファイルを登録するのではなく、文書の分割設計や補足情報の整備まで含めて検討する必要があります。以下の記事では、データの整備も含めて精度を向上する施策を紹介していますので、あわせてご覧ください。
参照記事:ChatGPT×RAGで社内データを活用する5つの手順。精度を向上させる施策も解説
検索方式が質問内容に合っていない
RAGで使われる検索方式は、大きく分けると「意味で探す検索」と「キーワードで探す検索」の2つがあります。
意味で探す検索は、言い換えや類義語に強く、ユーザーの質問が多少曖昧でも関連する情報を見つけやすい点が特徴です。一方で、製品名・型番・エラーコードのように、特定の文字列を正確に照合する必要がある質問では、別の情報を拾ってしまうことがあります。
以下は主な検索方式です。
| 検索方式 | 得意なこと | 苦手なこと |
|---|---|---|
| ベクトル検索 | 意味が近い情報を探す | 固有名詞・型番・略語の厳密な一致 |
| キーワード検索 | 特定の語句を正確に探す | 表記揺れ・言い換えへの対応 |
| ハイブリッド検索 | 意味検索とキーワード検索の弱点を補う | 設計や調整がやや複雑 |
| Re-ranker | 検索候補を精度順に並べ替える | 処理コストや遅延が増える場合がある |
そのため、RAGでは質問内容に応じて検索方式を使い分けることが重要です。たとえば、制度や手順のような概念的な質問では密ベクトル検索が有効ですが、型番やエラーコードのように文字列の一致が重要な質問ではキーワード検索のほうが適している場合があります。
実務では、どちらか一方に依存するのではなく、ハイブリッド検索やRe-rankerを組み合わせ、質問の性質に応じて必要な情報へたどり着ける設計にすることが求められます。
プロンプト設計が曖昧で回答がブレる
検索で適切な関連情報を取得できていても、LLMに渡すプロンプトが曖昧だと、最終的な回答は安定しません。RAGでは、検索結果をもとに回答を生成しますが、
- 検索結果のみを根拠に答える
- 根拠がない場合は不明と答える
といった制約を明確にしておかないと、LLMが自身の内部知識を混ぜて回答してしまうことがあります。
その結果、文章としては自然でも、実際には根拠のない内容や誤った情報が含まれる可能性があります。
さらに、回答の形式、粒度、トーン、出典の示し方を指定していない場合、同じ質問でも出力が毎回変わりやすくなります。たとえば「箇条書きで回答する」「出典を併記する」「判断できない場合は推測しない」など、回答ルールを明確にすることで、再現性を高められます。
また、RAGでは回答の正確性だけでなく、プロンプトインジェクションや情報漏えいへの対策も必要です。以下の記事では、RAGの構築においてセキュリティリスクも含めて対策方法を紹介していますので、あわせてご覧ください。
参照記事:RAG構築におけるセキュリティリスクと5つの対策方法。対策が必要な理由も紹介
このように、RAGの精度を高めるには、検索精度やプロンプト設計だけでなく、どの業務で使うのか、どの社内データを参照させるのか、現場でどのように運用・改善していくのかまで含めて考える必要があります。
こうした課題を自社だけで整理しきれない場合は、リベルクラフトへご相談ください。リベルクラフトでは、社内に分散されたデータの整備からRAGの構築、運用までを一気通貫で対応します。
すでにRAGを構築済みの場合でも、自社のRAGでどこにボトルネックがあるのか整理したい場合は、リベルクラフトへご相談ください。
⇨リベルクラフトへのお問い合わせはこちら
RAGの精度を向上させる具体的な手法
RAGの精度向上では、回答が外れた原因をLLMの性能不足と一括りにせず、データ前処理・検索・応答生成・運用改善のどこに問題があるのかを切り分けることが重要です。
ここからはRAGの精度を向上させる具体的な手法を6つ紹介します。
- データ前処理で検索対象のノイズを減らす
- チャンク設計を見直して文脈を残す
- メタデータを付与して検索条件を絞り込みやすくする
- ハイブリッド検索で検索漏れを減らす
- リランキングで回答に使う情報の質を高める
- プロンプトを改善して根拠に基づく回答を促す
データ前処理で検索対象のノイズを減らす
RAGの精度改善で最初に見直すべきなのは、検索対象となるデータの前処理です。RAGはナレッジベースから取得した情報をもとに回答を生成するため、
- 投入データに不要なヘッダー・フッター
- 広告文
- 制御文字
- 重複テキスト
- OCR由来の崩れた文字列
などが含まれていると、検索結果にも回答内容にも悪影響が出ます。
以下は、ノイズを除去する主なアプローチです。
| アプローチ | 内容 |
|---|---|
| 不要文字・制御文字の削除 | 文中の余計な空白や改ページ記号、不可視文字などを削除する |
| 大文字小文字の正規化 | すべて小文字に揃えるなど、ケースを統一する |
| ストップワード(Stop Words)の除去 | 「の・が・は」「a, the」など、意味に寄与しにくい機能語を除去し、ノイズを削減する |
| スペルミス修正 | タイポによる誤綴りは、正しい綴りと別ベクトル・別単語として扱われるため修正が必要 |
| 不要コンテンツの除去・分離 | ページごとに繰り返されるヘッダー・フッター・ナビゲーションメニュー・著作権表示・広告・バナー文など、本文とは無関係なテキストを除去する |
| 重複データの処理 | 同一または類似文章の重複が多いと、検索結果がそればかりになる偏りが生じる |
そのため、データ前処理では「不要な情報を取り除くこと」と「検索に必要な情報を残すこと」のバランスが重要です。
チャンク設計を見直して文脈を残す
チャンク設計とは、長い文書をRAGで検索しやすい単位に分割する設計のことです。RAGでは、文書全体をそのまま検索対象にするのではなく、一定のまとまりごとに分割した「チャンク」を検索し、質問に関連する情報をLLMへ渡します。

上の図のように、チャンクサイズを小さく設定すると、文書が細かく分割されます。細かく分けることで検索対象を絞り込みやすくなる一方、1つのチャンクに含まれる情報量が少なくなり、前後の文脈が失われる可能性があります。
たとえば、ある条件を説明する文章と、その例外や補足説明が別々のチャンクに分かれてしまうと、LLMは一部の情報だけを根拠に回答してしまうおそれがあります。
そのため、チャンク設計では、単に文字数やトークン数で機械的に分割すればよいわけではありません。固定長チャンクは実装しやすいものの、規程、技術マニュアル、研究資料のように見出しや節構造が意味を持つ文書では、文脈断絶が起きやすくなります。
メタデータを付与して検索条件を絞り込みやすくする
メタデータ付与は、RAGの検索精度を「意味的な近さ」だけに依存させないための重要な設計です。メタデータとは、ファイル名、ページ番号、カテゴリ、作成日、部署、製品名、権限情報など、本文そのものとは別に付与する補助情報を指します。
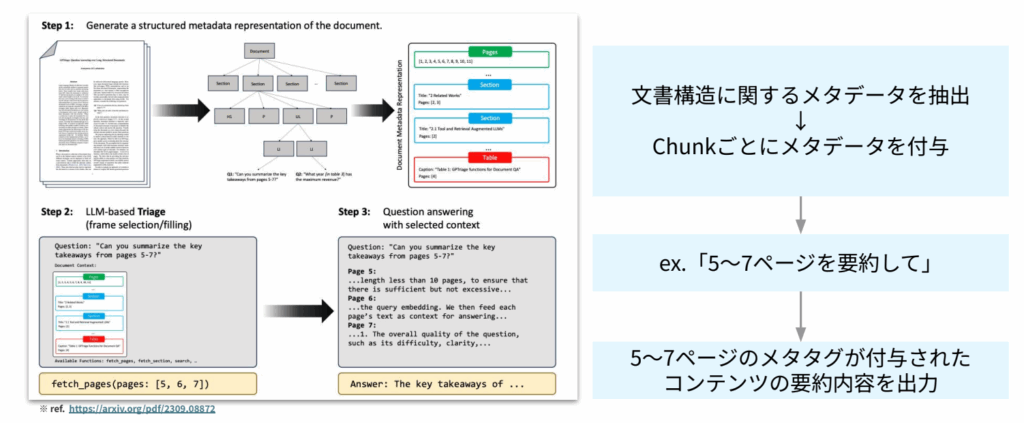
上の図のように、文書構造に関する情報を抽出し、チャンクごとにメタデータを付与しておくことで、検索時に「どの文書の、どの範囲の情報を参照すべきか」を判断しやすくなります。
たとえば、ユーザーが「5〜7ページを要約して」と質問した場合、ページ番号のメタデータが付与されていれば、該当ページに紐づくチャンクだけを対象にして回答を生成できるのです。
ハイブリッド検索で検索漏れを減らす
RAGの検索方式は、ベクトル検索だけに固定しないことが重要です。下記の図で分かる通り、ベクトル検索は、「固有名詞等の一致に弱い」「計算コストが高くなる」といった注意点があります。
また、全文検索(キーワード検索)は「言い換えに弱い」「表記揺れに弱い」という弱点があります。そこで有効なのが、全文検索とベクトル検索を組み合わせるハイブリッド検索です。
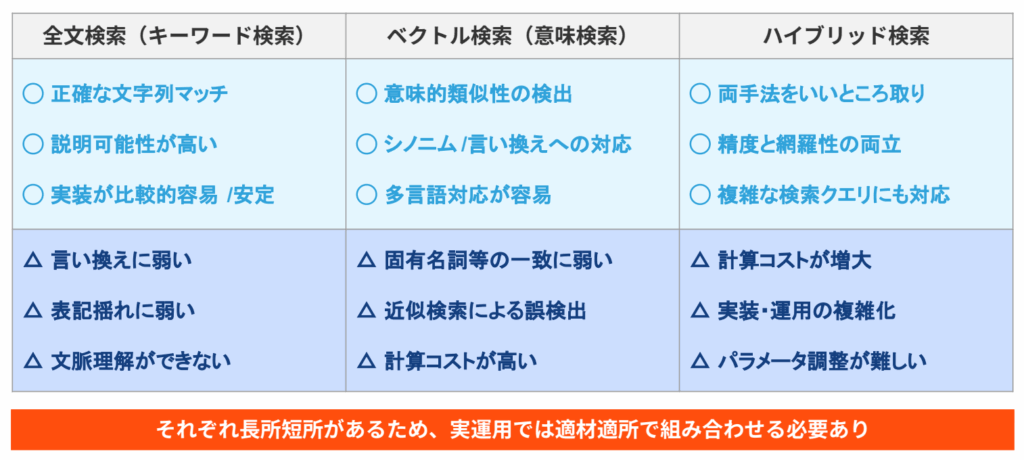
ハイブリッド検索は、画像でも示されているように、さまざまな強みがあります。
キーワードの厳密一致が必要な情報は全文検索で拾い、言い換えや意味的な近さが重要な情報はベクトル検索で補うことで、どちらか一方だけでは生じやすい検索漏れを減らせます。
リランキングで回答に使う情報の質を高める
リランキングは、初回検索で取得した候補文書を再評価し、LLMに渡す情報の質を高めるための手法です。
RAGでは、検索クエリをもとにナレッジDBから類似Chunkを取得しますが、最初に取得された検索結果がそのまま回答に最適とは限りません。表面的には質問と近いものの、実際には回答根拠として不十分なチャンクが含まれることもあります。
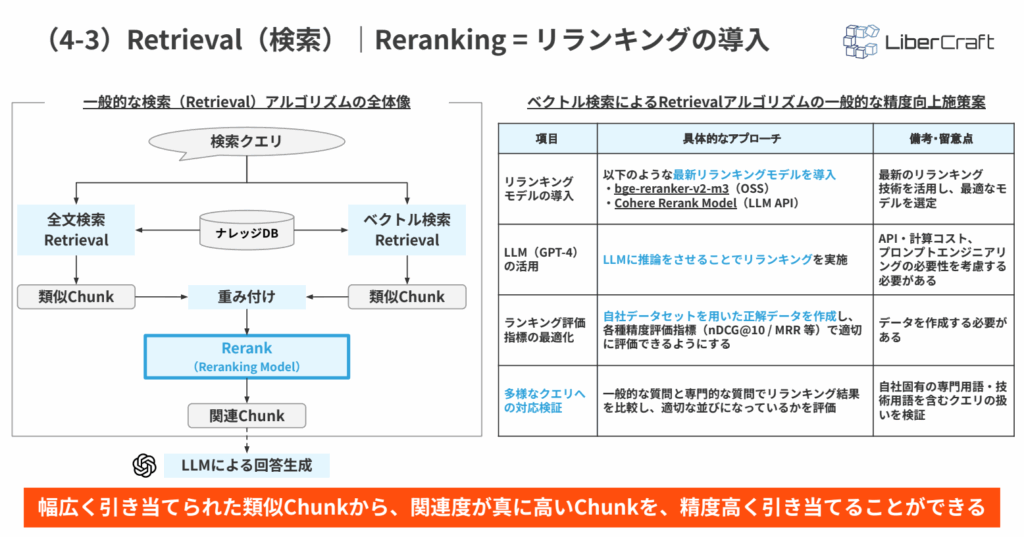
上図のように、一般的な検索では、検索クエリに対して全文検索やベクトル検索を行い、関連しそうな類似Chunkを取得します。その後、取得した候補に対して重み付けを行い、Rerank(Reranking Model)によって再評価します。これにより、質問に対して本当に回答根拠として使える関連Chunkを選び直せます。
たとえば、ユーザーが「AプランとBプランの料金差」を質問した場合、回答に必要なのは、料金差を判断できる最新の料金表やプラン比較表です。リランキングを行うことで、こうした候補の中から回答に直結するチャンクを上位に並べ替えられます。
プロンプトを改善して根拠に基づく回答を促す
RAGにおけるプロンプト改善は、検索で取得した関連情報をどのように使って回答させるかを制御する工程です。
検索精度が高く、適切なチャンクを取得できていたとしても、LLMに対する指示が曖昧だと、回答内容がブレたり、根拠にない情報を補完したりする可能性があります。

上図のように、RAGで使うプロンプトでは、システム指示・関連ドキュメント・ユーザー質問を明確に分けて設計することが重要です。
たとえば、「あなたは製品サポート担当者です」「以下の情報をもとに回答してください」「回答は簡潔にし、参考情報を明示してください」といった指示を入れることで、LLMがどの立場で、どの情報を根拠に、どの形式で回答すべきかを判断しやすくなります。
ここまでRAGの精度を高める具体的な手法について紹介しましたが、実際に自社でRAGを構築したい方は、以下の記事もご参照ください。
参照記事:Difyを活用したRAG構築の6ステップ。成功事例から学ぶ具体的開発手法も解説
RAGの精度を評価する方法
RAGの精度改善は、施策を実施して終わりではなく、改善前後で「本当に精度が上がったのか」を評価しましょう。ここでは、3つの評価方法を紹介します。
- 検索結果に正解文書が含まれているか確認する
- 回答が根拠文書に忠実か確認する
- 改善前後で同じ質問セットを使って比較する
検索結果に正解文書が含まれているか確認する
まず確認すべきなのは、ユーザーの質問に対して、RAGが正しい文書やチャンクを取得できているかです。検索段階で正解文書を取得できていなければ、後続のLLMがどれだけ高性能でも正確な回答を出すことは難しくなります。
たとえば、ユーザーが「Aプランの解約条件」を質問しているのに、料金表やサービス概要資料だけが検索結果に出ている場合、回答に必要な根拠が不足している状態です。
一方で、検索結果の中に正解文書が含まれているにもかかわらず回答が間違っている場合は、検索ではなくプロンプト設計や生成処理側に問題がある可能性が高くなります。
そのため、評価ではLLMに渡された検索結果の中身まで確認することが重要です。検索結果に正解チャンクが含まれているかを確認すれば、改善すべき対象が「検索精度」なのか「回答精度」なのかを切り分けやすくなります。
回答が根拠文書に忠実か確認する
検索結果に正しい文書が含まれていても、生成された回答がその文書に忠実でなければ、RAGとしての信頼性は高いとはいえません。
RAGの回答評価では、回答内容が参照文書に書かれている事実と一致しているかを確認する必要があります。たとえば、根拠文書には「Aプランは月額5万円」と書かれているのに、回答で「初期費用込みで5万円程度」と補完してしまう場合、文章としては自然でも業務上は誤回答です。
また、根拠のない推測や一般論が混ざっていないかも評価ポイントです。
回答が、
- 参照文書に基づいているか
- 質問に対して過不足なく答えているか
- 出典や根拠を確認できる形になっているか
を見ます。RAGの回答精度は、流暢さではなく、根拠との整合性と再現性で評価することが重要です。
改善前後で同じ質問セットを使って比較する
RAGの改善効果を正しく確認するには、改善前後で同じ質問セットを使って比較する必要があります。質問を毎回変えてしまうと、チャンク設計や検索方式、プロンプト改善などの施策が本当に効いたのか判断しづらくなります。
まずは、実際の利用ログや想定業務からよく聞かれる質問、失敗しやすい質問や、複数文書をまたいで回答する質問などをテストセットとして用意します。
そのうえで、改善前と改善後で
- 正解文書の取得率
- 回答の根拠忠実性
- 回答の過不足
- 出典提示の正確性
などを比較します。
たとえば、ハイブリッド検索を導入した結果、型番や略語を含む質問で正解文書の取得率が上がったのか、プロンプト改善によって根拠のない補完が減ったのかを確認します。
RAGの精度改善は一度で完了するものではなく、質問セットを使って継続的に評価し、ログをもとに改善サイクルを回すことが重要です。
RAGの精度改善では、検索結果に正解文書が含まれているか、回答が根拠文書に忠実か、改善前後で精度がどう変化したかを継続的に検証する必要があります。
業務目的に合った評価設計と改善運用まで行うことで、実務で使えるRAGに近づけられます。
RAGの設計・構築・精度改善を進めたい場合は、データ活用を戦略から開発・教育まで伴走支援するリベルクラフトへの相談を検討してみてください。
⇨リベルクラフトへのお問い合わせはこちら
ビジネスを加速させるRAGの具体的なユースケース
RAGの精度向上を考える際は、改善手法だけでなく、具体的なユースケースも確認しておくことが重要です。ここでは、4つの事例を紹介します。
- 問い合わせ対応の自動化・高度化
- 社内ナレッジの共有と技術継承
- 営業支援とパーソナライズ提案
- 社内データベースからのデータ抽出(Text-to-SQL)
ユースケース1:問い合わせ対応の自動化・高度化
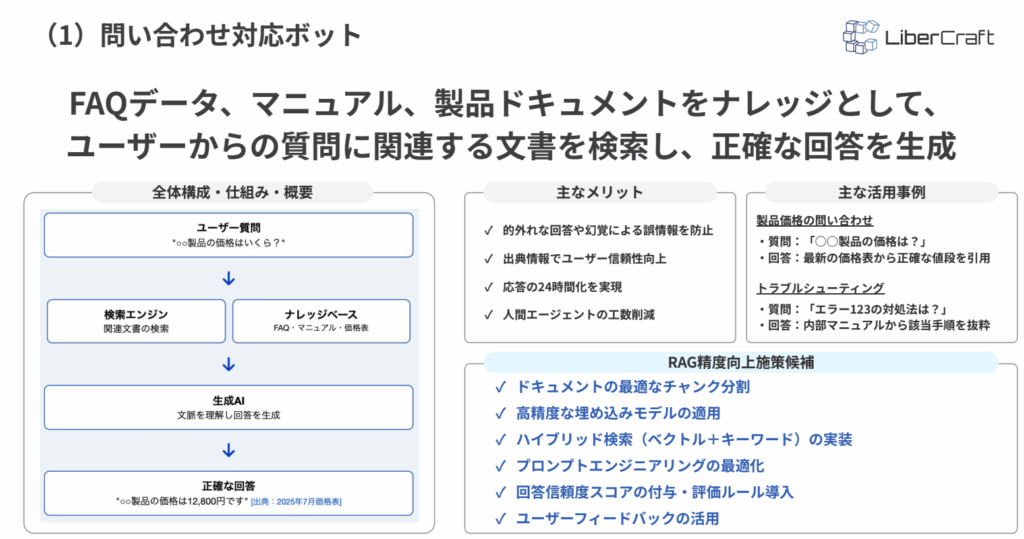
| 課題 | 問い合わせ対応で回答品質にばらつきが出る |
| RAGによる解決策 | FAQ・マニュアル・製品ドキュメントをナレッジ化し、質問に関連する文書を検索して正確な回答を生成する |
| 精度向上のポイント | チャンク分割、埋め込みモデル、ハイブリッド検索、プロンプト改善など |
問い合わせ対応ボットにRAGを活用すると、FAQデータ、業務マニュアルなどをナレッジとして参照し、ユーザーからの質問に関連する文書を検索したうえで回答を生成できます。
たとえば「〇〇製品の価格は?」という質問には最新の価格表をもとに回答し、「エラー123の対処法は?」という質問には内部マニュアルから該当手順を抜粋して案内できます。
これにより、担当者ごとの回答のばらつきや、LLMの推測による誤回答を抑えやすくなります。また、出典情報を示せるため、ユーザーが回答の根拠を確認しやすくなり、問い合わせ対応の信頼性向上にもつながります。さらに、24時間対応や一次回答の自動化によって、人間のサポート担当者の工数削減も期待できます。
ユースケース2:社内ナレッジの共有と技術継承

| 課題 | 必要な情報が分散・属人化し、技術やノウハウが継承されにくい |
| RAGによる解決策 | 社内文書を統合し、自然言語で検索・回答できる社内Q&Aを構築する |
| 精度向上のポイント | メタデータ付与とアクセス権限管理で、必要な情報だけを正確に参照できるようにする |
企業内には、設計書、議事録など、多くのドキュメントが蓄積されています。しかし、情報が部署ごとに分散していたり、特定の社員しか保管場所や内容を把握していなかったりすると、必要な情報を探すだけで時間がかかります。
こうした課題に対して、RAGを活用すれば、社内ドキュメントを統合したナレッジベースを構築し、社員が自然言語で質問するだけで必要な情報を引き出せる社内QAシステムを実現可能です。
たとえば「過去に同じ不具合はあったか」「この業務の手順はどこに書かれているか」と質問すれば、関連するマニュアルや議事録、トラブル対応履歴をもとに回答できます。
これにより、情報を探す時間を削減できるだけでなく、属人化していた知識を組織全体で共有しやすくなります。精度を高めるには、文書にカテゴリ・部署・作成日・製品名などのメタデータを付与し、検索条件を絞り込みやすくすることが重要です。
ユースケース3:営業支援とパーソナライズ提案

| 課題 | 必要な情報が分散・属人化し、技術やノウハウが継承されにくい |
| RAGによる解決策 | CRM・商談履歴・商品データ・成功事例を横断検索し、顧客ニーズに合う類似商品や提案候補を生成する |
| 精度向上のポイント | CRMや商談履歴との連携、商品データのメタデータ整備、顧客別プロンプトなど |
営業支援にRAGを活用すると、CRMやナレッジDBに蓄積された顧客情報、商品データなどを横断的に検索し、次の提案に活かせる情報を生成できます。
たとえば、営業担当者が「この顧客におすすめの商品は?」と質問すると、過去の商談履歴や購買傾向、類似顧客への提案事例、商品仕様、レビュー、在庫情報などを連携していれば、候補商品を提示できます。
これにより、顧客ごとのパーソナライズ提案がしやすくなり、営業担当者の経験や勘に依存しすぎない提案活動が可能になります。また、類似商品一覧やスペック比較をもとに、PowerPointやExcelの提案書へ落とし込むことで、提案資料作成の効率化にもつながります。
ユースケース4:社内データベースからのデータ抽出(Text-to-SQL)

| 課題 | 非エンジニアが社内DBから必要なデータを取り出しにくく、データ活用が一部の担当者に依存しやすい |
| RAGによる解決策 | RAGを使ってDB構造やスキーマ情報を参照しながら、必要なSQLを生成する |
| 精度向上のポイント | スキーマ情報の整備、サンプルクエリの拡充、アクセス権限管理、SQLインジェクション対策 |
社内データの自動抽出にRAGを活用すると、社内データベースに対して自然言語で質問し、必要なデータを抽出しやすくなります。
たとえば、ユーザーが「今年の四半期ごとの売上は?」と質問すると、RAGがDBのスキーマ情報やカラム定義、サンプルクエリを参照しながら、適切なSQL文の候補を生成します。
これにより、非エンジニアでもデータベースを直接扱いやすくなり、売上分析や解約率分析などの業務に活用できます。
特にText-to-SQL用途では、LLMに単に質問を投げるだけではなく、社内DBの構造を正しく理解させることが重要です。テーブル名、カラム名、エイリアス、自然言語での別名などが整理されていないと、誤ったSQLを生成したり、存在しないカラムを参照したりする可能性があります。
以下の記事では、RAGの活用事例をさらに紹介しています。あわせてチェックしてみてください。
参照記事:RAGの活用事例17選。実装の手順と成功させるポイントも解説
さらに高度なRAGの精度を改善する手法
ここまでRAGの精度向上の方法について紹介しましたが、さらにRAGの精度を向上させる手法を3つ紹介します。
- Query Transformation
- GraphRAG
- Agentic RAG
Query Transformation
Query Transformationとは、ユーザーの質問をそのまま検索に使うのではなく、検索しやすい形に変換する手法です。
たとえば「解約するといくらかかる?」という曖昧な質問を、
- 解約金
- 違約金
- 途中解約費用
- 契約解除手数料
などの検索語に展開すれば、ナレッジベース内の表記揺れに対応しやすくなります。元のクエリが必ずしも検索に最適ではないため、LLMでクエリを書き換えてから検索する方法や、より抽象度の高い問いを生成するStep-back promptingなどが有効な場合があります。
ただし、Query Transformationは「検索語を増やせばよい」という単純な施策ではありません。クエリを広げすぎると、質問意図から外れた文書まで取得し、かえって回答精度が下がる可能性があります。
GraphRAG
GraphRAGは、文書中の人物・組織・製品などの実体やそれらの関係性を抽出し、ナレッジグラフとして構造化したうえで、その関係性を検索や回答生成に活用する手法です。
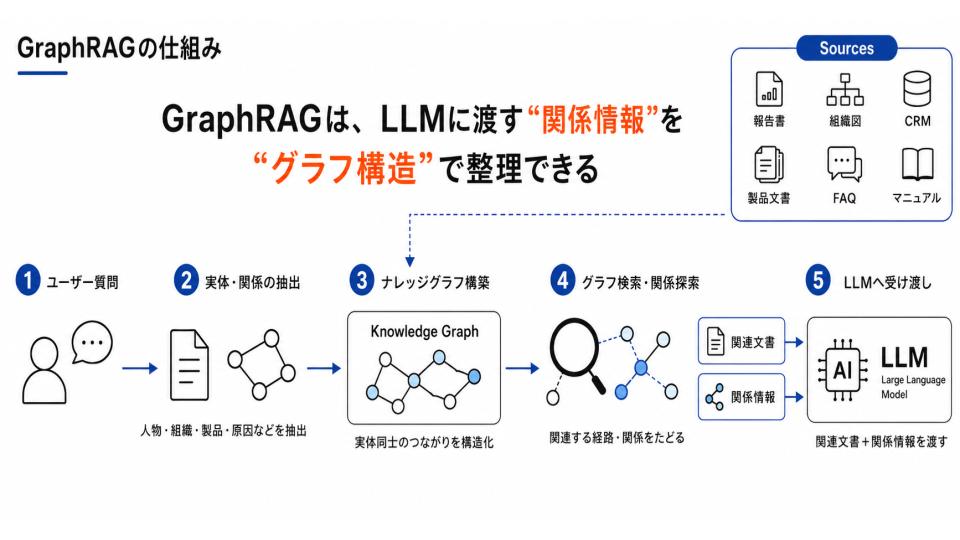
GraphRAGは、テキスト抽出、ネットワーク分析、LLMによるプロンプト拡張・要約を組み合わせるアプローチと考えるとわかりやすいでしょう。
通常のRAGが「質問に意味的に近いチャンクを引っ張ってくる」だけなのに対し、GraphRAGは実体同士のつながりをたどれるため、
- 複数の文書にまたがる関係性
- 組織構造
- 顧客と製品の関係
- 原因と対策のつながり
といった「点ではなく線・面で理解すべき問い」に強いのが特徴です。
一方で、グラフの構築や更新にはコストがかかり、エンティティや関係の抽出精度を検証する工程も必要になります。
Agentic RAG
Agentic RAGとは、通常のRAGパイプラインにAIエージェントの考え方を取り入れ、検索・再検索・ツール利用・検証をより自律的に行わせるアーキテクチャです。
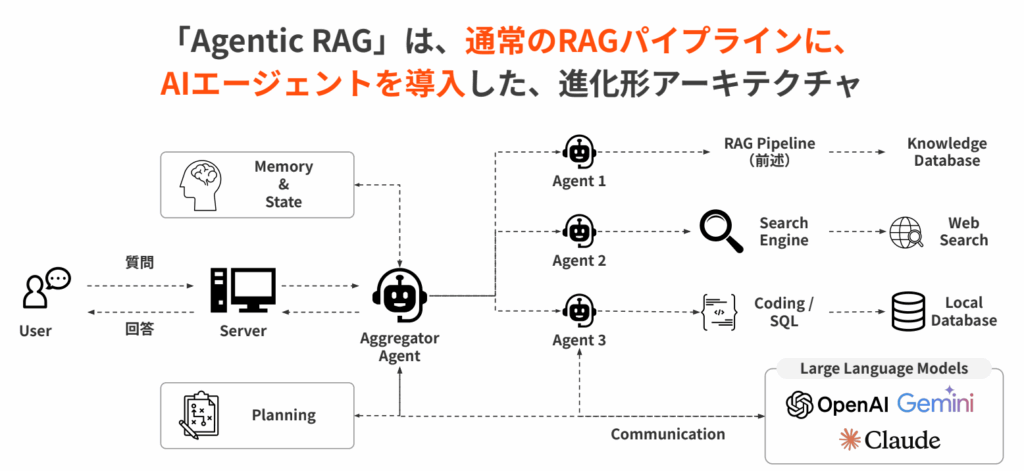
基本的なRAGは、ユーザーの質問に対して一度検索し、その検索結果をもとに回答を生成する流れが中心です。
一方、Agentic RAGでは、エージェントが質問を分解し、必要に応じて複数ツールを使い分けながら、段階的に回答を導き出します。
Agentic RAGの強みは、複雑な質問に対して一度きりの検索で終わらず、検索結果を評価し、不足があれば再検索できる点です。
まとめ
RAGの精度向上で重要なのは、精度が低い原因を「LLMの性能不足」と決めつけず、検索・データ・チャンク・プロンプト・評価のどこに問題があるのかを切り分けることです。
正しい文書を取得できていない状態では回答生成を改善しても限界があり、逆に正しい文書を取得できていても、プロンプト設計が曖昧であれば根拠にない回答が生まれる可能性があります。
業務で信頼して使える水準にするには、技術面だけでなく、業務目的や運用体制まで踏まえた設計が必須です。自社だけで原因を特定しにくい場合は、リベルクラフトへご相談ください。
リベルクラフトでは、企業内に分散した社内文書・業務マニュアル・議事録・FAQ・暗黙知などを整理し、実務で使えるRAG環境の構築を支援しています。
また、すでにRAGを構築している場合でも、「正しい文書を検索できていない」「回答が根拠に沿っていない」「業務で使える精度にならない」といった課題に対して、原因を切り分けながら改善を進めることが可能です。
まずは以下のリンクからお気軽にお問い合わせください。
⇨リベルクラフトへのお問い合わせはこちら



