Difyを活用したRAG構築の6ステップ。成功事例から学ぶ具体的開発手法も解説

近年、生成AI、特に大規模言語モデル(LLM)の進化は目覚ましく、多くの企業がそのビジネス活用に大きな期待を寄せています。例えば、
- 顧客サポートの自動化
- 社内ナレッジの高度活用
- マーケティングコンテンツの生成
など、その応用範囲は多岐にわたります。
しかし、この大きな可能性とは裏腹に、多くの企業がAIシステムの開発において課題に直面しています。従来のシステム開発手法では、変化の速いビジネスニーズに追いつくことが難しく、開発期間の長期化や高額なコスト、そして一度開発したシステムの柔軟性の欠如といった問題が浮き彫りになっています。
本記事では、こうした課題を解決する鍵として、オープンソースのLLMアプリ開発プラットフォーム「Dify(ディファイ)」と、LLMの性能を飛躍的に向上させる技術「RAG(Retrieval-Augmented Generation)」に焦点を当てます。Difyを活用することで、いかにしてAIシステムを「高速」かつ「柔軟」に開発できるのか、その具体的な手法とアプローチを、実際の開発事例を交えながら徹底的に解説します。
「RAGの構築方法がわからない」「RAGの精度を高めるにはどうすればいい?」とお悩みの方は、リベルクラフトへご相談ください。
リベルクラフトでは、AI・データ活用戦略の設計から、RAGシステムの開発、運用改善、人材教育まで一気通貫で支援しています。貴社のビジネスモデルや業務課題を踏まえたうえで、どのデータをナレッジ化すべきか、どの検索方式を採用すべきか、どのように精度改善を進めるべきかまで伴走します。
まずは以下のリンクから無料でご相談ください。
⇨リベルクラフトへの無料相談はこちら
RAG(Retrieval-Augmented Generation)とは?
RAGは、LLMが元々持っている広範な知識に加えて、自社独自のデータベースといった「外部情報源」を参照して回答を生成する技術です。
たとえば、社員が「今年度の経費精算ルールを教えて」と質問した場合、RAGは社内規程やマニュアルの中から該当する文書を探し、その内容をもとに回答を作成します。
LLMが記憶だけで答えるのではなく、実際の社内資料を参照して回答するため、業務で使いやすい精度の高い回答につながります。
RAGの仕組み
RAGは「検索」と「生成」を組み合わせることで、LLM単体では答えにくい質問にも対応しやすくする仕組みです。
- 質問: ユーザーがシステムに質問を投げかけます。
- 検索 (Retrieval): システムは、まず質問に関連する情報を、あらかじめ準備された対象データ(社内マニュアル、議事録、報告書など)から検索します。
- 拡張 (Augmented): 検索して見つかった関連情報を、元の質問文と組み合わせてLLMへの入力(プロンプト)を「拡張」します。
- 生成 (Generation): 拡張されたプロンプトをLLM(例:OpenAIのGPTモデル)に渡し、その情報に基づいて回答を生成させます。
- 回答: 生成された回答がユーザーに返されます。
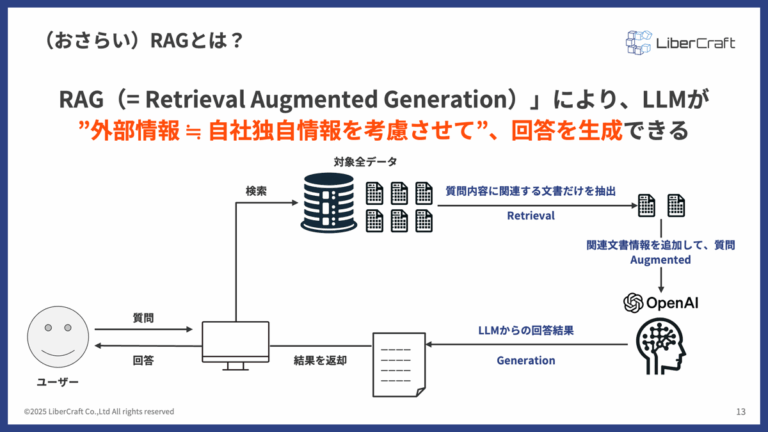
RAGを活用すれば、社内ナレッジをLLMに直接学習させ直すことなく、必要な情報を参照させながら回答を生成できます。
RAGシステム構築の一般的なステップ
RAGシステムをゼロから構築する場合、一般的に以下のステップが必要です。
- データ収集:社内文書、マニュアル、FAQなど、AIに参照させたい情報を収集。
- データ前処理:テキストのクリーニング、品質評価、個人情報のチェック、ベクトル化など、AIが処理しやすい形式にデータを整備。
- 生成AIモデルとの統合:プロンプトエンジニアリング、検索モデルの選択、LLMの選定などを実施。
- システムデプロイ・運用:インフラの構築、API設計、フロントエンド開発、継続的なモニタリング(LLMOps)など、システムを安定稼働させるための仕組みを構築

LLMアプリ開発プラットフォーム「Dify」とは?
Difyは、RAGシステムを含むLLMアプリケーションの開発に伴う複雑さと手間を大幅に削減するために設計された、オープンソースのプラットフォームです。
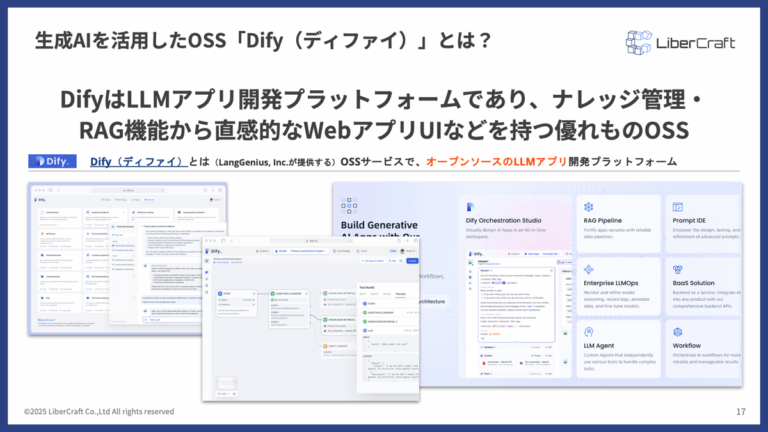
Difyを利用すれば、
- RAGに必要なデータ登録
- 検索設定
- LLMとの接続
- ワークフロー設計
- アプリ公開
までを一つの画面上で進められます。通常、RAGシステムを構築するには、データの前処理、ベクトルデータベースへの格納、検索ロジックの設計、LLMへのプロンプト連携、外部ツールとの接続など、複数の技術要素を組み合わせる必要があります。
しかしDifyでは、これらの工程を視覚的に操作できるため、開発者だけでなく、業務部門の担当者もAIアプリの設計に関わりやすくなります。
Difyが解決する課題
Difyは、SaaS、OSSモジュール活用、フルスクラッチ開発といった既存の開発アプローチの「良いとこ取り」を目指したツールです。そのため、
- 開発スピード
- 柔軟性
- 運用管理
のバランスを取りながら、LLMアプリケーションを構築できる点に強みがあります。
- 既存SaaS:導入は速いですが、カスタマイズ性が低く、継続的なライセンス費用が発生
- OSSモジュール活用:低コストですが、自社で保守・管理を行う必要があり、セキュリティリスクを伴う。
- フルスクラッチ開発:自由度は高いですが、開発期間とコストが膨大になる。
以下の記事では、Difyで実現できることについて詳しく解説していますので、あわせてご覧ください。
参照記事:Difyで何ができる?5つの特徴と活用例を成功事例も交えて紹介
Difyの強み
Difyは上記の課題に対し、以下のようなメリットを提供します。
- 低コストでの高速プロトタイピング:直感的なUIで、専門的な知識がなくても迅速にRAGアプリケーションのプロトタイプを構築可能。これにより、初期検証のハードルが劇的に下がる。
- ライセンス費用の抑制: OSSであるため、継続的なライセンス費用を抑えることが可能。
- 柔軟なカスタマイズ性: OSSの利点を活かし、バックエンドのロジックや外部システムとの連携など、柔軟なカスタマイズが可能。
つまりDifyは、「RAGプロジェクトのプロトタイプ構築を初期検証可能なレベルにまで引き上げる」ための強力なツールであり、AIシステム開発のハードルを大きく下げる存在と言えます。

以下の記事では、Difyの特徴や使い方をよりわかりやすく解説していますので、あわせてご覧ください。
参照記事:Difyの使い方や特徴を徹底解説!環境構築からアプリ作成まで
AIシステム開発のアプローチを整理
AIシステム開発のアプローチは、大きく以下3つに大別されます。
- プロンプトエンジニアリング|ChatGPTなど既存プラットフォームの活用
- RAG|自社データ活用
- ファインチューニング|モデルの特化
アプローチ1:ChatGPTなど既存プラットフォームの活用(プロンプトエンジニアリング)
ChatGPTやGeminiなどの既存プラットフォームを活用する方法は、生成AI導入の中でも最も始めやすいアプローチです。この方法で重要になるのが、プロンプトエンジニアリングです。
プロンプトエンジニアリングとは、AIに対する指示文を工夫し、期待する回答に近づける技術を指します。たとえば、「わかりやすくまとめてください」だけではなく、「経営層向けに、専門用語を補足しながら300文字程度でまとめてください」と指示することで、回答の精度や使いやすさが変わります。
| 項目 | 内容 |
|---|---|
| 概要 | ChatGPTやGeminiなど、既存の生成AIサービスを利用して業務を効率化する方法 |
| 主な活用例 | メール文作成、議事録要約、記事構成案作成、アイデア出し、翻訳、調査補助 |
| 有効な条件 | 公開情報や一般的な知識をもとに回答できれば十分な場合 |
| 長所 | すぐに導入でき、専門的な開発体制がなくても利用しやすい |
| 短所 | 社内文書や独自ノウハウなど、非公開情報を前提にした回答は苦手 |
| 向いている企業 | まずは生成AIを小さく試したい企業、部門単位で業務効率化を進めたい企業 |
ただし、既存プラットフォームは基本的に汎用的な知識をもとに回答するため、自社独自のルールや業務プロセスを正確に理解しているわけではありません。
アプローチ2:RAG(Retrieval-Augmented Generation)による自社データ活用
RAGは、自社データを生成AIに活用させるためのアプローチです。
たとえば、社員が「今年度の経費精算ルールを教えて」と質問した場合、RAGは社内規程やマニュアルの中から該当する情報を探し、その内容をもとに回答を作成します。
| 項目 | 内容 |
|---|---|
| 概要 | 社内文書やデータベースから関連情報を検索し、その情報をもとにLLMが回答を生成する方法 |
| 主な活用例 | 社内FAQ、問い合わせ対応、マニュアル検索、規程確認、製品情報検索、カスタマーサポート |
| 有効な条件 | 自社独自の情報を活用したいが、大量の学習データを準備するのが難しい場合 |
| 長所 | 自社データを反映でき、参照元を示しやすいため、回答の信頼性を高めやすい |
| 短所 | 検索システムの精度や文書整理の状態が、回答品質に大きく影響する |
| 向いている企業 | 社内ナレッジを活用したい企業、問い合わせ対応を効率化したい企業、生成AIを業務システムに組み込みたい企業 |
RAGのメリットは、LLMそのものを再学習させなくても、自社データを回答に反映できる点です。ファインチューニングのように大量の教師データを用意する必要がないため、比較的導入しやすく、更新頻度の高い情報にも対応しやすくなります。
アプローチ3:ファインチューニングによるモデルの特化
ファインチューニングは、既存のLLMに追加学習を行い、特定の業務や専門領域に合わせてモデルの挙動を調整する方法です。
プロンプトエンジニアリングやRAGが「LLMの使い方」や「参照情報」を工夫するアプローチであるのに対し、ファインチューニングはモデル自体を特定用途に近づける点が特徴です。
| 項目 | 内容 |
|---|---|
| 概要 | 既存のLLMに追加学習を行い、特定タスクや専門領域に合わせてモデルを調整する方法 |
| 主な活用例 | 専門領域の対話、特定フォーマットでの回答生成、業界特化型チャットボット、独自文体の再現 |
| 有効な条件 | 高品質な学習データを大量に用意でき、特定領域への最適化が必要な場合 |
| 長所 | 特定タスクにおいて、高い精度や一貫した応答を期待できる |
| 短所 | 学習データの準備、モデル学習、評価、運用にコストと専門知識が必要 |
| 向いている企業 | 専門性の高いAIを構築したい企業、独自の応答スタイルや業務判断をモデルに反映したい企業 |
ファインチューニングは、うまく活用できれば特定業務に強いAIモデルを構築できます。しかし、導入のハードルは3つのアプローチの中で最も高いといえます。
なぜなら、モデルに学習させるデータの品質が低ければ、期待した精度が出ないだけでなく、誤った判断や不自然な回答を学習してしまう可能性があるからです。
画像付き|DifyでRAGを構築する6ステップ
ここからは実際にDifyを用いてRAGを構築する方法を以下8つのステップで解説します。
- RAGで使うファイルをアップロードする
- チャンク分割とインデックス設定を行う
- スタジオでRAGアプリを新規作成する
- スタジオでRAGアプリを新規作成する
- ナレッジベースをアプリのコンテキストに追加する
- システムプロンプトを設定する
1.RAGで使うファイルをアップロードする
まずはRAGで使う外部のデータをアップロードしていきます。今回は文部科学省が公表している「【概要資料】初等中等教育段階における生成AIの利活用に関するガイドライン」を活用していきます。
まずはDifyを開き、画面上のナレッジを選択します。
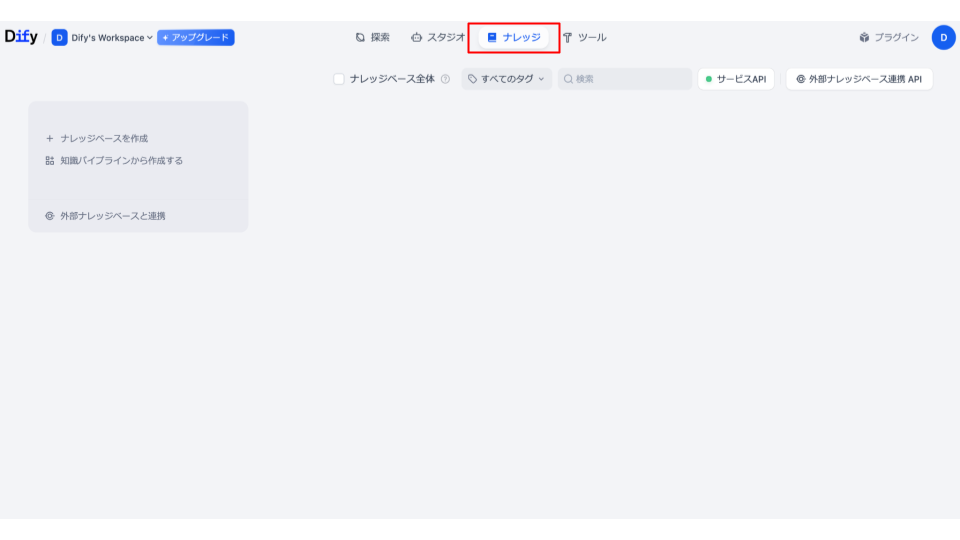
次に「ナレッジベースを作成」をクリックします。
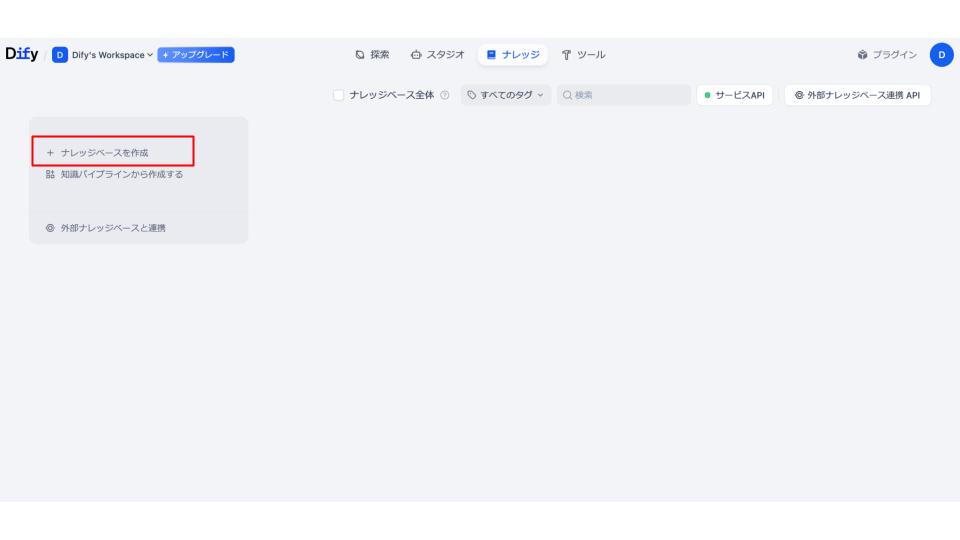
以下の画面が表示されるため、今回使用するデータのPDFをアップロードします。「テキストファイルからアップロード→参照」でアップロードできます。
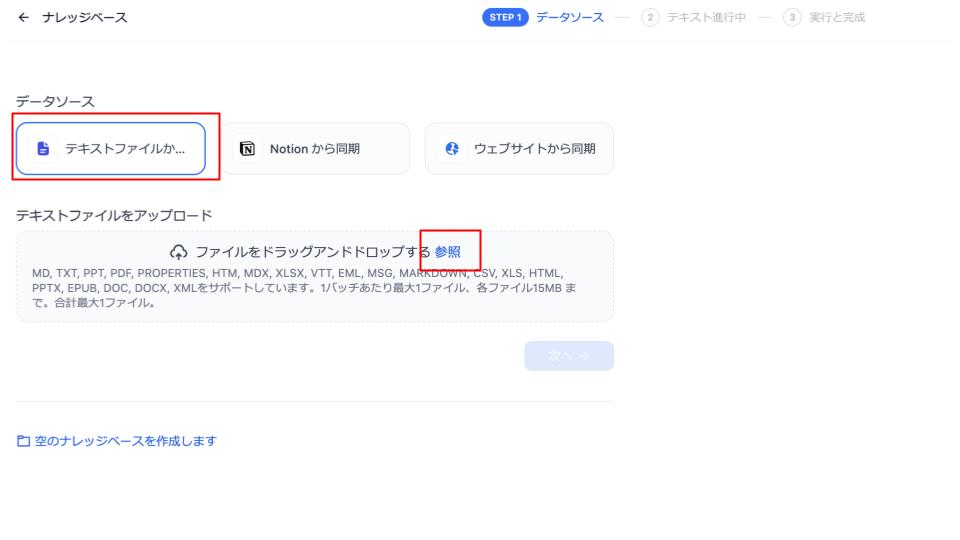
ここまで完了したら、次の章に移ります。
2.チャンク分割とインデックス設定を行う
ファイルのアップロードが完了したら、以下の画面に遷移します。ここでチャンク分割とインデックス設定を実施します。
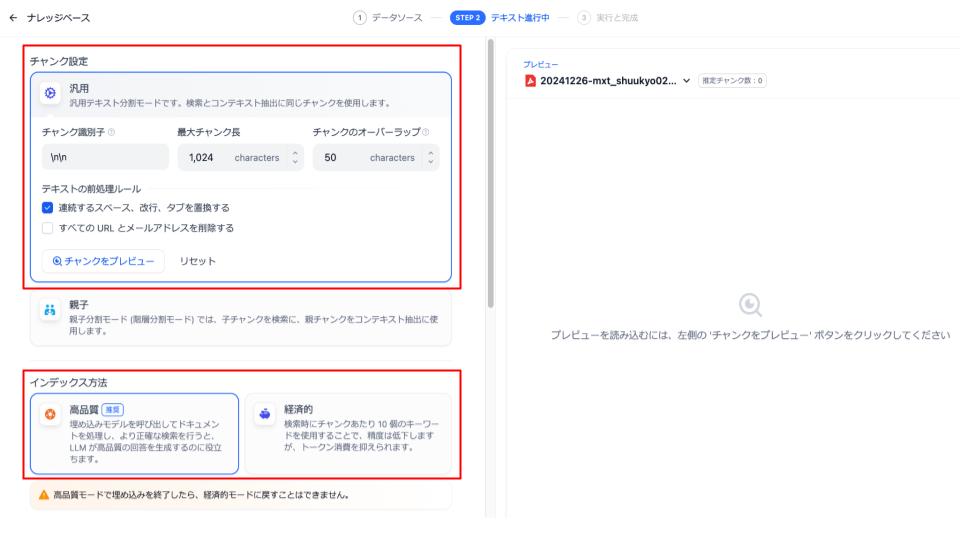
なお、それぞれの意味は以下のとおりです。
- チャンク:文章を分割すること
- インデックス方法:作成したナレッジに対してどのような手法で検索を行うかを定義する設定
まずはチャンク設定を行なっていきます。チャンク設定では、以下の3つを設定します。なお、意味は以下のとおりです。
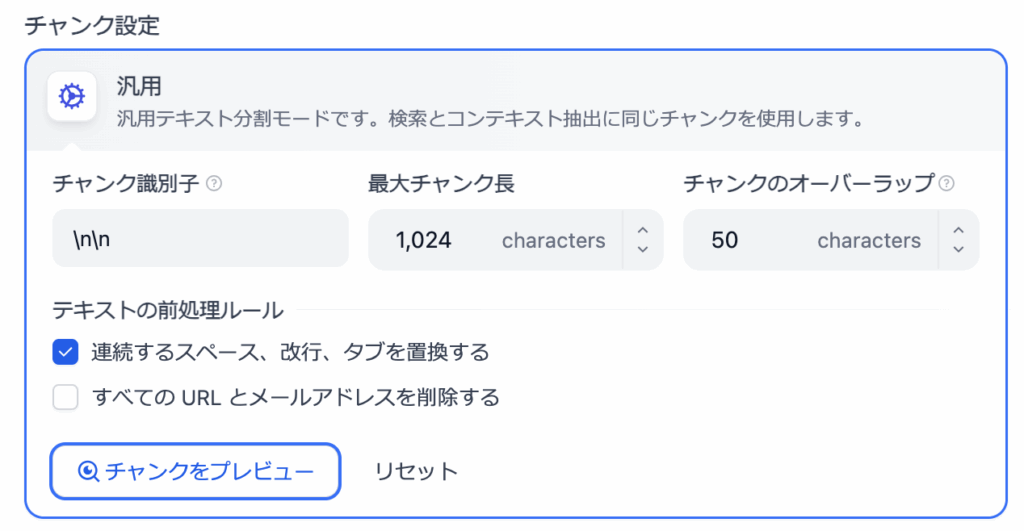
- チャンク識別子:文章の中でどの文字が出たら文章を区切るのか
- 最大チャンク長:文字数の区切り
- オーバーラップ:文章を分割した時の境目のオーバーラップをどれくらい許容するか
ここはRAGの精度を左右する重要な部分になりますので、必ず設定しておきましょう。どの数値を設定すればいいかわからない場合は、Microsoftが出している「Azure AI Search: Outperforming vector search with hybrid retrieval and reranking」で、
- 最大チャンク長:512
- オーバーラップ:25%
が最も精度が高いと記載されています。全てに当てはまるわけではありませんが、おすすめです。
今回は上記と同じに設定して、プレビューをクリックしてみます。
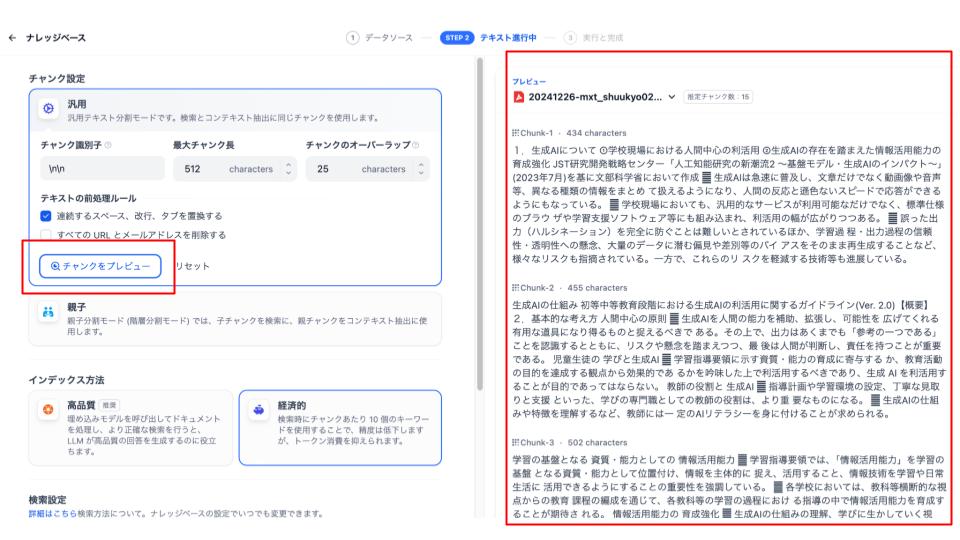
次にインデックス方法です。主に「高品質」と「経済的」の2つがあります。
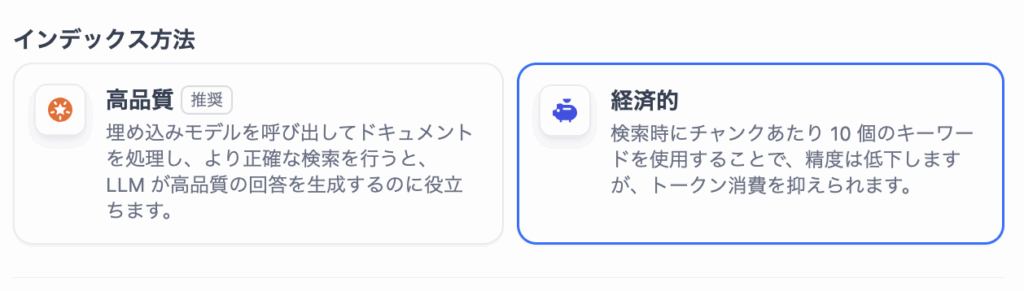
基本的にはRAGの精度を高めるために高品質(分割された文章から文章を検索するときにベクトル化する)を選んでおけば問題ありません。その他の設定はそのままで「保存して処理」をクリックして完了です。
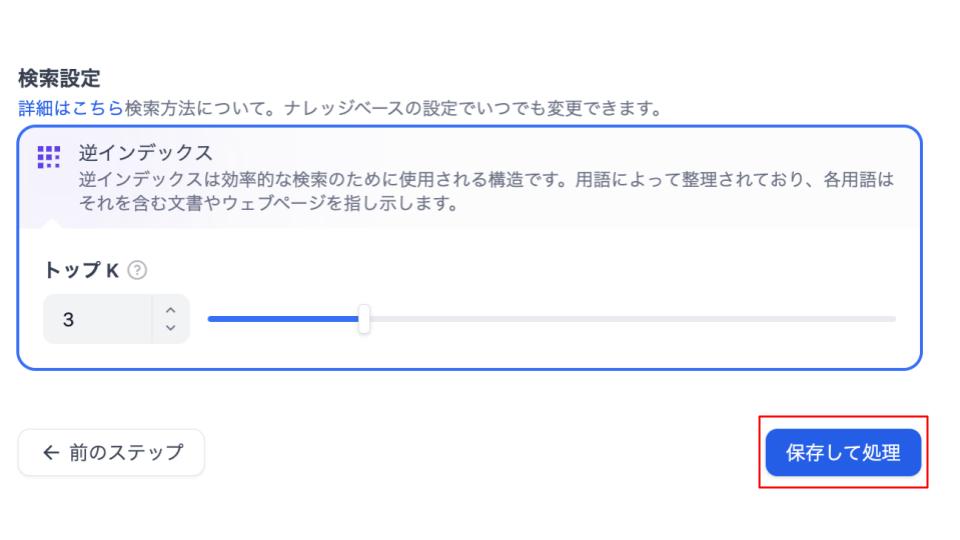
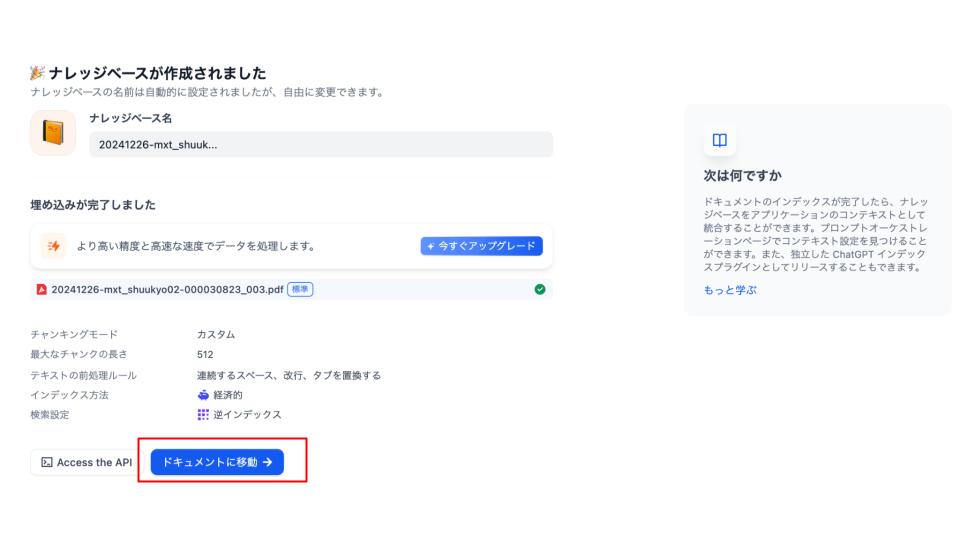
3.登録したドキュメントを確認する
次にドキュメントを作成します。先ほどの保存して処理をクリックすると、以下の画面に遷移するので「ドキュメントに移動」をクリックしましょう。
以下の画面に移動するので、実際にテストをしてみましょう。画面左の「検索テスト」をクリックします。
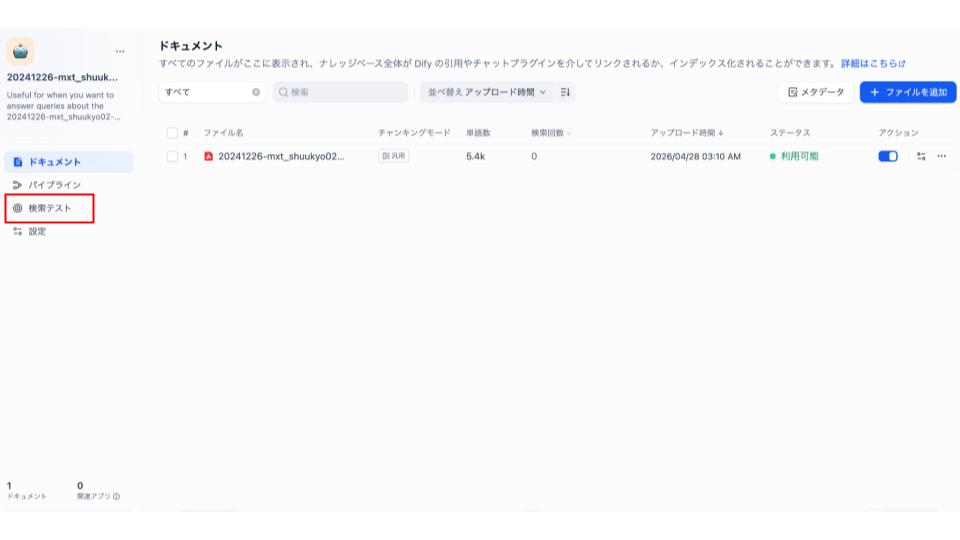
以下の画面に遷移するので、実際に質問してみましょう。
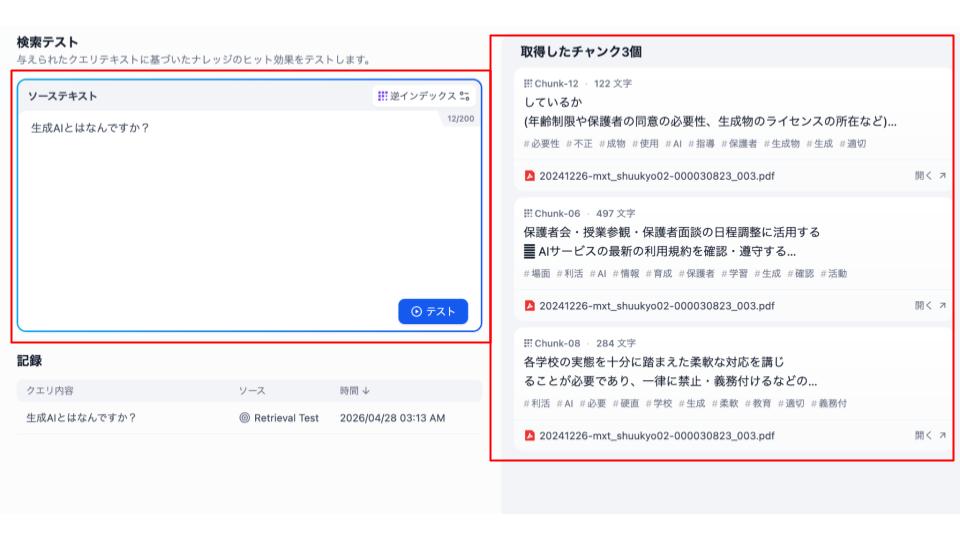
画面右の取得したチャンクを抽出できれば、アップロードしたファイルの中から検索ができていると言うことです。
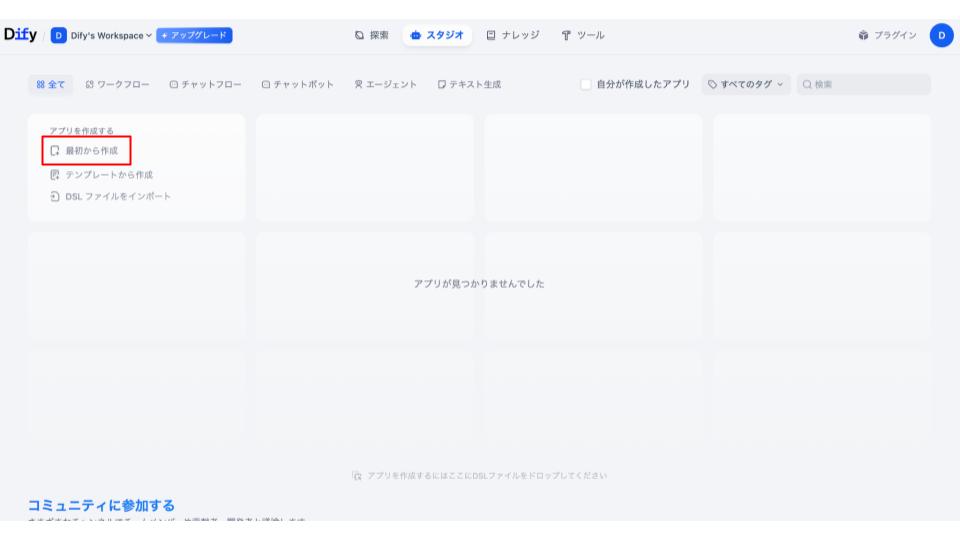
4.スタジオでRAGアプリを新規作成する
ここからはアプリケーションの作成に入っていきます。初期の画面に戻り、「最初から作成」をクリックします。
今回はチャットボットを選択し、アプリと名前では自分のわかりやすいように設定しましょう。
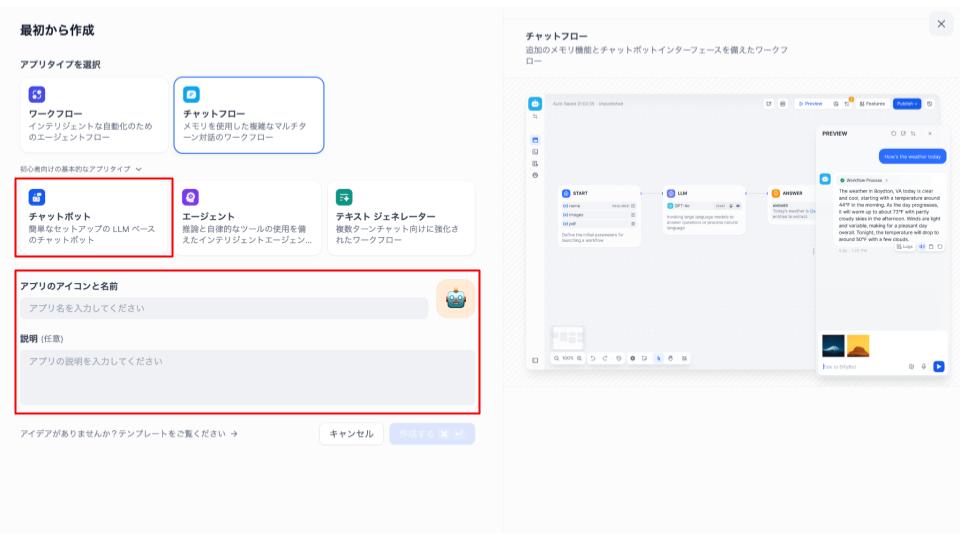
完了したら次の章に移ります。また、以下の記事ではワークフローを用いた作成方法についても解説していますので、あわせてご覧ください。
参照記事:Difyのワークフローとは?作り方から活用事例・チャットフローとの違いまで解説
5.ナレッジベースをアプリのコンテキストに追加する
先ほどの設定が完了したら、コンテキストの追加を行なっていきます。画面垢枠にある「追加」をクリックしましょう。
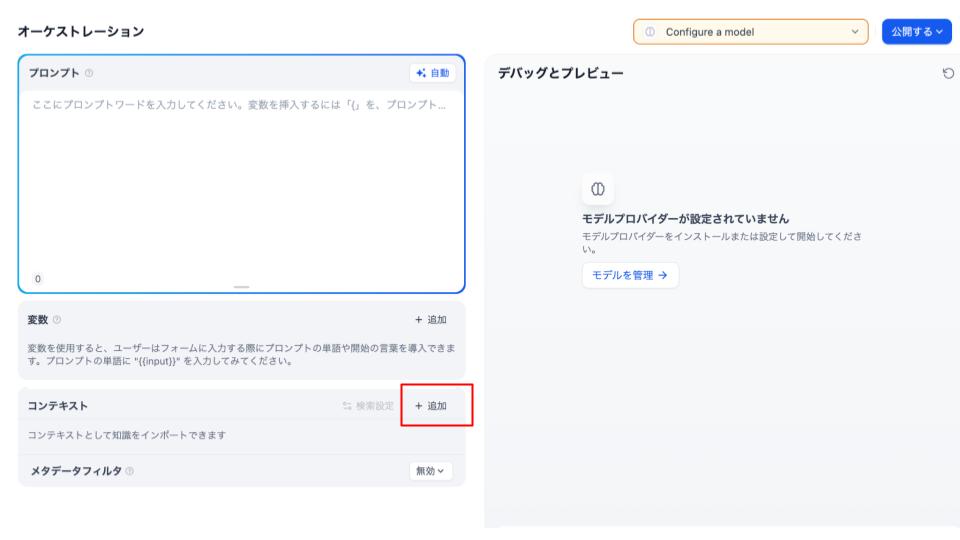
ここで先ほど作成したナレッジベースを選択します。完了したら次の章に移ります。
6.システムプロンプトを設定する
次に以下の画面にある「プロンプト」の欄に入力をしていきます。ここでは、以下のプロンプトを入力するのがおすすめです。
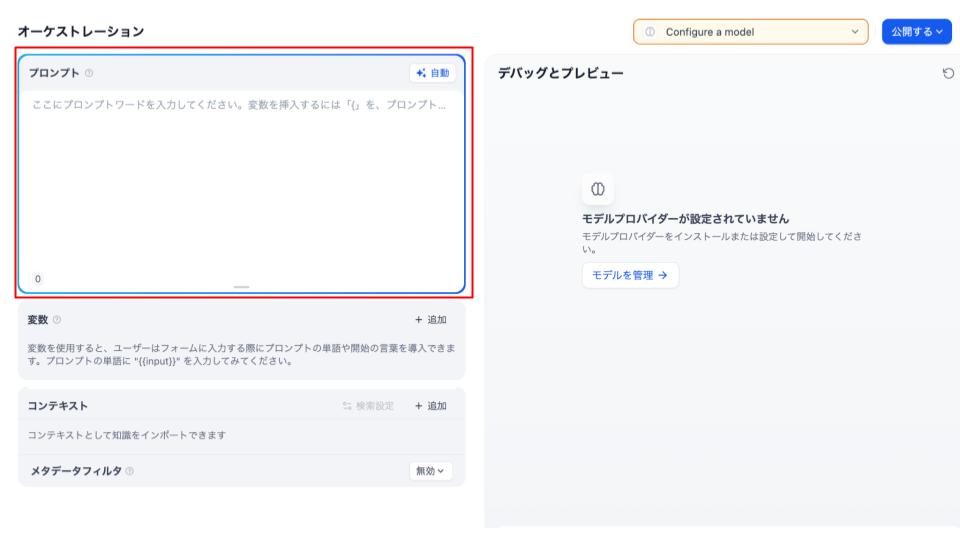
【入力するプロンプト】
コンテキストに基づいてユーザーからの質問に回答するチャットボットです。 コンテキストに基づいて回答できない場合は「回答が出来ませんでした。質問を変更してください。」と返答してください。
なお、コンテキストに書いていないことを回答することは避けてください。
最後に質問をして、以下のように出力されたら完成です。
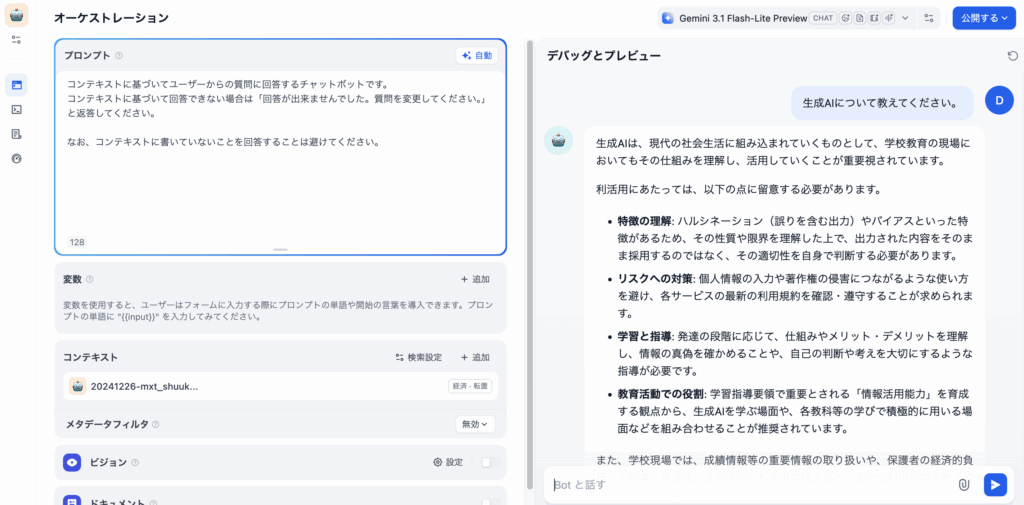
ここまでをご覧になって「どのようにRAGを構築するべきかわからない」「RAGの精度を向上するにはどうしたらいい?」と悩む方は、リベルクラフトへご相談ください。
リベルクラフトなら、RAGの構想段階から精度改善、本番活用に向けた体制づくりまで相談できます。自社データを活用したAIチャットボットや社内ナレッジ検索、問い合わせ対応の効率化を検討している方は、まずは無料相談をご活用ください。
⇨⇨リベルクラフトへの無料相談はこちら
DifyでRAGの精度を高めるポイント
前章でも少し触れていますが、DifyでRAGの精度を高めるためには工夫が必要です。ここでは以下3つのポイントを紹介します。
- 文書を前処理して回答しやすい状態に整える
- チャンク分割とオーバーラップを調整して文脈をつなげる
- 検索結果にノイズが多いときは検索設定を見直す
文書を前処理して回答しやすい状態に整える
DifyでRAGの精度を高めるには、まず登録する文書を前処理し、AIが読み取りやすい状態に整えましょう。RAGは、アップロードされた文書を検索対象として扱うため、文書内に不要な情報や表記ゆれ、重複した内容が多いと、検索結果の質が下がりやすくなります。
たとえば、社内マニュアルに
- 最新版はこちら
- 別紙参照
- 前述のとおり
といった文言が多く含まれていると、AIはその部分だけを取り出しても意味を理解しにくくなります。
そのため、Difyに文書を登録する前には、見出し構造を整理し、不要なヘッダーやフッター、目次、注釈、重複表現などを削除しておくと効果的です。人間が読んでもわかりにくい資料は、AIにとっても扱いにくい資料ということを覚えておきましょう。
チャンク分割とオーバーラップを調整して文脈をつなげる
RAGでは、長い文書をそのまま検索するのではなく、一定の単位に分けて検索対象にします。この分割されたテキストのかたまりを「チャンク」と呼びます。Difyでもナレッジを登録する際に、文書をどの程度の大きさで分割するかが、回答精度に影響します。
チャンクが短すぎると、検索には引っかかりやすくなる一方で、回答に必要な前後の文脈が不足しやすくなります。たとえば、料金表の説明部分だけが切り出され、対象プラン名が前のチャンクに分かれてしまうと、AIは「何の料金なのか」を判断しにくくなります。
そこで重要になるのが、チャンク分割とオーバーラップの調整です。オーバーラップとは、前後のチャンクで一部の文章を重ねて持たせる設定のことです。これにより、文書が途中で分割されても、前後の文脈をある程度保ったまま検索できるようになります。
検索結果にノイズが多いときは検索設定を見直す
DifyでRAGを運用していると、「文書は登録しているのに、質問と関係の薄い情報ばかり返ってくる」「回答の根拠として、意図しない資料が参照される」といった問題が起きることがあります。このような場合、LLMそのものの性能だけが原因とは限りません。
たとえば、取得する検索結果の件数が多すぎると、関係の薄い情報までLLMに渡され、回答が散らかる原因になります。反対に、取得件数が少なすぎると、必要な根拠情報が不足し、回答が浅くなる可能性があります。
見直すポイントは以下のとおりです。
| 見直すポイント | 起こりやすい問題 |
|---|---|
| 検索方式 | 意味は近いが、質問意図とはずれた文書が取得される |
| ベクトル検索 | 類似表現の検索には強いが、製品名・型番・部署名などの完全一致に弱い場合がある |
| 全文検索 | キーワードが一致しないと、関連情報を拾いにくい場合がある |
| ハイブリッド検索 | 設定によっては検索結果のバランスが崩れる場合がある |
| 取得件数 | 多すぎるとノイズが増え、少なすぎると根拠情報が不足する |
| スコアのしきい値 | 関連度の低い文書まで取得される |
| 検索対象の範囲 | 関係のないナレッジまで検索対象になり、回答がずれる |
このように、DifyでRAGの検索精度を高めるには、
- 検索方式や取得件数
- スコアのしきい値
- 検索対象の範囲
を実際の質問に合わせて調整することが重要です。
特に、社内FAQや業務マニュアルのように自然文で質問されるケースではベクトル検索が有効ですが、製品名、型番、規程番号、部署名などを正確に拾いたい場合は、全文検索やハイブリッド検索のほうが適していることもあります。
Difyを活用した具体的な開発プロジェクト事例
Difyを活用した具体的な開発プロジェクト事例を3つ紹介します。
- 社内ナレッジ活用(議事録検索RAG)
- 業務効率化ツール(企画書アイデア生成支援)
- エンタープライズ向けシステム連携(Azure環境でのRAGチャットボット)
社内ナレッジ活用(議事録検索RAG)
- 課題:過去の膨大な議事録の中から、特定の情報を探し出すのに多大な時間がかかっていた。
- 解決策:すべての議事録データをDifyに投入してナレッジベースを構築。Dify単体でRAGチャットボットを作成し、自然言語で質問するだけで関連する議事録の内容を要約して回答できるようにした。
- 効果:情報検索の時間を大幅に短縮し、社内の知識共有を促進した。

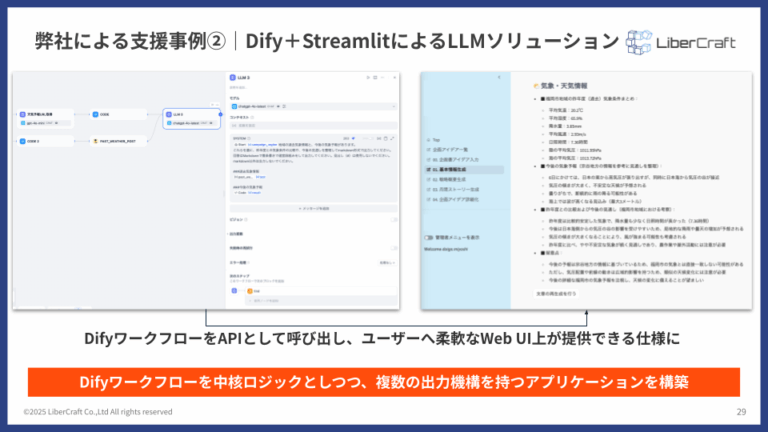
業務効率化ツール(企画書アイデア生成支援)
- 課題:小売業の販促企画を立案する際に、市場データ、天候データ、過去の販売実績など、多岐にわたる情報を分析する必要があり、担当者の負担が大きかった。
- 解決策:Difyで複数のワークフロー(市場動向分析、ターゲット顧客設定、戦略概要生成、販促アイデア詳細化など)をAPIとして構築。フロントエンドをStreamlitで開発し、ユーザーがいくつかの基本情報を入力するだけで、段階的に詳細な企画書を自動生成するアプリケーションを構築した。バックエンドでは、外部の気象情報APIや社内のPOSデータとも連携。
- 効果:企画立案にかかる時間を劇的に削減し、データに基づいた質の高い企画の量産を可能にした。
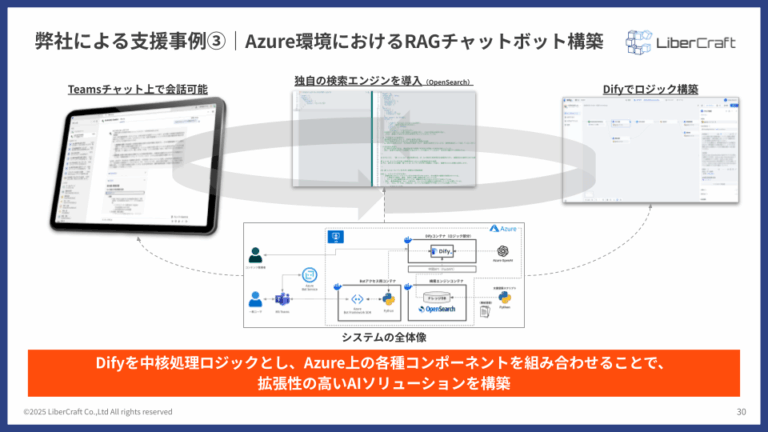
エンタープライズ向けシステム連携(Azure環境でのRAGチャットボット)
- 課題:大企業において、セキュリティポリシーや既存のITインフラ(Microsoft Teams, Azureなど)との連携が必須であり、一般的なSaaS型のAIツールでは対応が困難だった。
- 解決策:Difyを処理ロジックの中核に据え、ユーザーインターフェースはMicrosoft Teams、認証はAzure AD、検索エンジンはOpenSearch、LLMはAzure OpenAI Serviceと、既存のAzure環境上のコンポーネントと全面的に連携するRAGチャットボットを構築。
- 効果:高度なセキュリティを維持しつつ、従業員が使い慣れたTeams上で自然に利用できる社内情報検索システムを実現し、拡張性と保守性の高いソリューションを構築した。
また、以下の記事ではDifyの活用事例について詳しく解説していますので、あわせてご覧ください。
参照記事:Difyの活用事例20選!業務ごとの活用例や企業の成功例も紹介
Difyを活用したプロジェクト事例から学ぶ成功のポイント
Difyを活用したプロジェクトでは、最初から大規模なAIシステムを作り込むよりも、段階的に検証しながら実用性を高めていく進め方が重要です。ここでは2つのポイントを紹介します。
- Dify単体でPoCを行う
- Difyと独自ロジックを組み合わせる
Dify単体でPoCを行う
Difyを活用する際は、まずDify単体でPoCを行い、RAGやLLMアプリの有効性を小さく検証することが重要です。いきなり全社向けの大規模なAIシステムを構築しようとすると、
- 対象データの整理
- 権限設計
- 外部システム連携
- UI設計
など、検討すべき要素が増えてしまいます。その結果、開発期間が長期化し、現場で本当に使えるのかを確認する前にコストだけが膨らむリスクがあります。
この段階で見るべきなのは、「AIが回答できたか」ではありません。どの文書が参照されたのか、回答に根拠があるのか、利用者が期待する粒度で返答できているのかまで確認する必要があります。
Difyと独自ロジックを組み合わせる
DifyはLLMアプリ開発を効率化できるプラットフォームですが、すべての要件をDifyだけで完結させる必要はありません。むしろ実務で価値の高いAIシステムを構築するには、Difyが得意な領域と、外部コンポーネントで補うべき領域を切り分けることが重要です。
たとえば、利用者向けの画面はStreamlitやWebアプリケーションで構築し、裏側のLLM処理やRAGの呼び出しをDifyに任せる構成が考えられます。また、Pythonで事前にデータを加工し、必要な形式に整えたうえでDifyのナレッジに登録すれば、検索精度を高めやすくなります。
重要なのは、Difyを「LLMアプリの中核機能を効率よく担う基盤」として設計することです。Difyに任せる部分と独自開発する部分を整理できれば、開発スピードを保ちながら、現場要件にも対応しやすくなります。
自社でAI開発プロジェクトを推進するためのアクションプラン
これまでの内容を踏まえ、自社でAI開発プロジェクトを成功させるために、どのようなステップを踏むべきか、具体的なアクションプランを提示します。
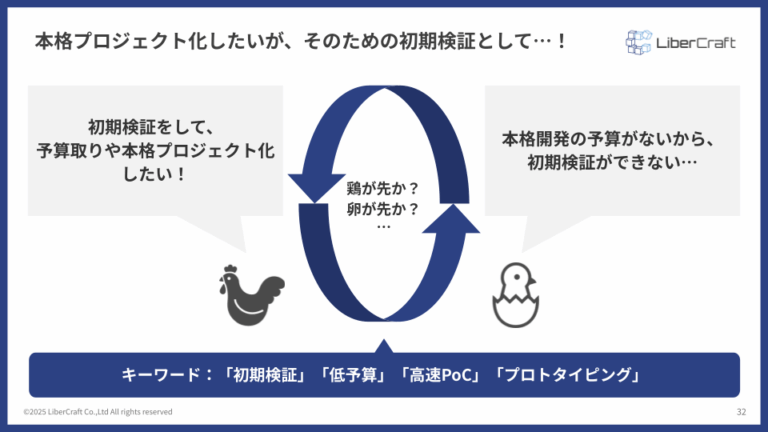
- 「鶏が先か、卵が先か」問題を超えるための初期検証
- Difyでできること・できないことを理解する
- 開発支援ソリューションを活用する
「鶏が先か、卵が先か」問題を超えるための初期検証
多くの企業でAIプロジェクトが進まない原因として、「本格開発の予算がなければ初期検証ができない」「初期検証をしていないので本格プロジェクト化の予算が取れない」という「鶏と卵」の問題があります。
このジレンマを解決する鍵が、
- 低予算
- 高速PoC
- プロトタイピング
です。Difyは、まさにこの初期検証フェーズにおいて絶大な効果を発揮します。まずはDifyを活用して、最小限のコストと時間で「動くもの」を作り、その価値を具体的に示すことが、プロジェクトを次のステップに進めるための最も確実な方法です。
Difyでできること・できないことを理解する
自社でAI開発プロジェクトを推進する際は、まずDifyで対応できる範囲と、独自開発が必要になる範囲を切り分けることが重要です。Difyは、
- プロンプト作成
- RAGの基本構築
- ワークフロー設計
- LLMアプリのプロトタイピング
などに強みがあります。そのため、社内FAQやマニュアル検索のように、まず小さくAI活用を試したい場面では非常に有効です。
一方で、Difyだけですべての要件を満たせるわけではありません。たとえば、大量データのETL処理、検索エンジンの高度なチューニング、認証やログ管理を含む本格的なアプリケーション化、外部APIとの複雑な連携などは、Pythonやクラウドサービス、独自システムとの組み合わせが必要になる場合があります。

そのため、プロジェクト初期段階では「Difyに任せる領域」と「外部開発で補う領域」を整理しておくべきです。
開発支援ソリューションを活用する
AIプロジェクトを成功に導くには、技術力だけでなく、ビジネス要件の定義からデータ分析、モデル開発、そして内製化支援まで、幅広い専門知識と経験が必要です。
株式会社リベルクラフトでは、こうした一連のプロセスをステップバイステップで支援する開発ソリューションを提供しています。
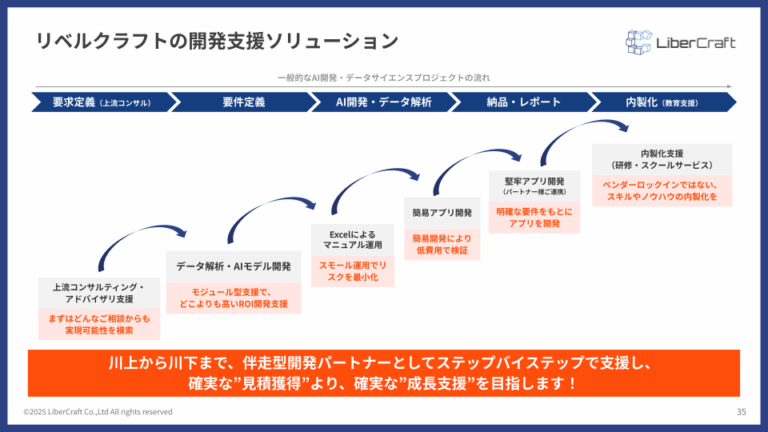
- 要求定義(上流コンサル): ビジネス課題のヒアリングから、AIで解決すべきテーマを特定します。
- AI開発・データ分析: PoCから本格開発まで、データ分析とモデル構築を支援します。 簡易アプリ開発: DifyやExcelなどを活用し、低コストで迅速にプロトタイプを開発します。
- 内製化支援: スキルスクールやノウハウの移管を通じて、企業が自律的にAI開発を推進できる体制構築を支援します。
このような外部パートナーと連携することも、プロジェクトを成功に導くための一つの有効な手段です。以下のリンクからまずはお気軽にお問い合わせください。
⇨リベルクラフトへのご相談・お問い合わせはこちら
Difyを活用したRAGの構築はリベルクラフトへ
Difyを活用すれば、RAGアプリのプロトタイプ構築やナレッジベースの作成、LLMとの連携を比較的スピーディーに進められます。
しかし、実際のプロジェクトでは「どの業務からAI化すべきか」「Difyだけで実装できるのか」「独自開発や外部システム連携が必要なのか」といった判断が必要になります。判断が難しい場合は、リベルクラフトへご相談ください。
リベルクラフトでは、AI開発・データ分析・簡易アプリ開発・内製化支援まで、企業のAI活用を幅広く支援しています。Difyを活用したRAG構築を検討している方や、自社データを活用したAIシステムをどこから始めればよいかわからない方は、まずは無料相談をご活用ください。
DifyやRAGを活用したAI開発について相談したい方は、以下よりリベルクラフトへお問い合わせください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



