RAGとファインチューニングの違いを7つの視点で比較。使い分けの判断基準も解説

「RAGとファインチューニング、どちらを選べばいいのかわからない」「聞いたことがあるけれど何が違うのかイメージできない」と感じている方は少なくないでしょう。
どちらも生成AIを自社の業務に合わせて活用するための手法ですが、仕組みや適している用途、コストなどが異なります。
そこで本記事では、
- RAGとファインチューニングそれぞれの仕組み
- 7つの視点での違いの比較
- それぞれが向いているユースケース
- 使い分けの判断基準
をわかりやすく解説します。「自社にはどちらが合っているのか」と悩んでいる方は、ぜひ最後までご覧ください。
「RAGとファインチューニングのどちらを選ぶべきかわからない」「自社の業務に合ったAI活用の方針から相談したい」という方は、リベルクラフトへご相談ください。
リベルクラフトでは、業務課題の整理から最適な手法の選定、設計・構築・運用まで一気通貫で支援しています。
また、自社が保有するデータをもとにAIを構築し、業務フローに合わせた柔軟なカスタマイズにも対応していますので、まずは以下のリンクからお気軽にお問い合わせください。
⇨リベルクラフトへの無料相談はこちら
RAGとは?
RAGとは(検索拡張生成)、生成AIが回答を出す前に外部のデータベースや文書を検索し、その内容をもとに回答を生成する手法です。
下記のYouTube動画「データサイエンティストが解説!自社向けにAIをカスタマイズする方法」でも触れているように、RAGは、自社のナレッジを生成AIで活用するための代表的な手法として多くの企業で導入されています。
一般的な生成AIは、あらかじめ学習したデータの範囲をもとに回答するため、自社の業務マニュアルや社内規程といった自社固有の情報は、そのままでは参照できません。
RAGは、この課題を解決するための技術であり
- 社内文書
- FAQ
- 業務マニュアル
などをデータベースとして整備しておくことで、生成AIが必要な情報を検索し回答を生成できるようになります。
以下のYouTube動画では、RAGの概要から自社向けにAIをカスタマイズする方法を紹介していますので、あわせてご覧ください。
参照リンク:【企業のAI活用の5段階③】「自社向け」にAIをカスタマイズする方法
RAGの仕組み
社内にある情報を参考にして回答できるRAGの具体的な仕組みは以下のようになっています。
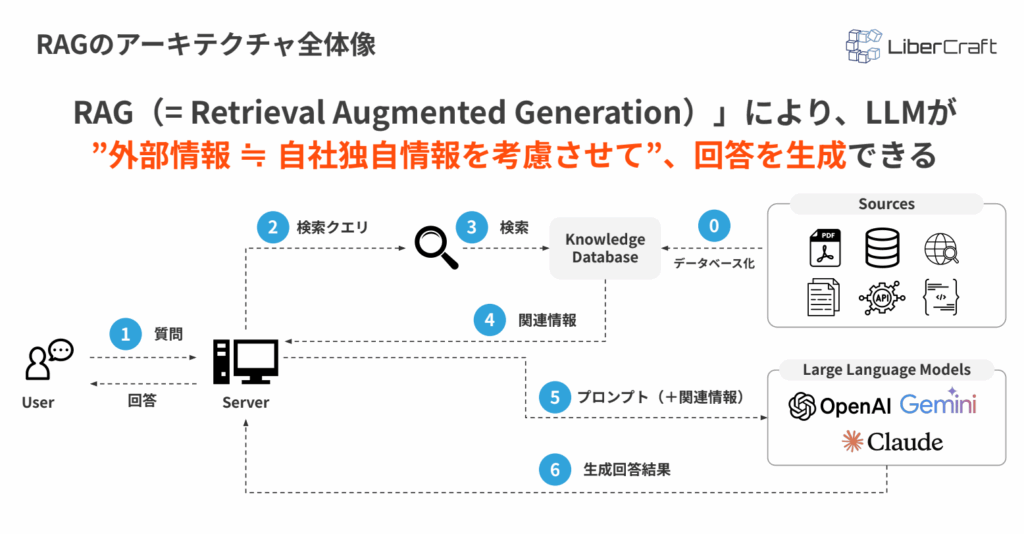
基本的な流れは、次の3つです。
- 質問に関連する情報を探す 利用者が質問を入力すると、社内文書などの中から、質問に関係する情報を検索します。
- 見つけた情報を生成AIに渡す 検索で見つかった情報を、質問と一緒に生成AIへ渡します。
- 生成AIが回答を作り、利用者に返す 生成AIは、渡された情報をもとに回答を作成し、その結果を利用者に返します。
RAGは、回答の根拠がわかりやすく生成AIの回答の間違いが起きにくくなり、社内文書やFAQを更新すれば新しい情報を回答に反映しやすい点もメリットです。
ファインチューニングとは?
ファインチューニングとは、学習済みの生成AIモデルに追加データを学習させ、特定の業務や判断基準に合うように調整する手法です。
自社の業務データや回答例を追加で学習させることで、モデルの出力内容を自社仕様に近づけることができます。
ファインチューニングで調整しやすいものには、
- 業界特有の用語や言い回し
- 自社らしい回答のトーンや文体
- 特定の判断基準や分類ルール
のようなものがあります。
ただし、学習させた内容は簡単に削除・更新できないため、変化の少ない情報の活用や、出力スタイルを統一するケースに向いています。
ファインチューニングの仕組み
特定の業務や回答の型をモデルに学習させ、自社に合った出力をしやすくできるファインチューニングの具体的な仕組みと流れは以下のようになっています。
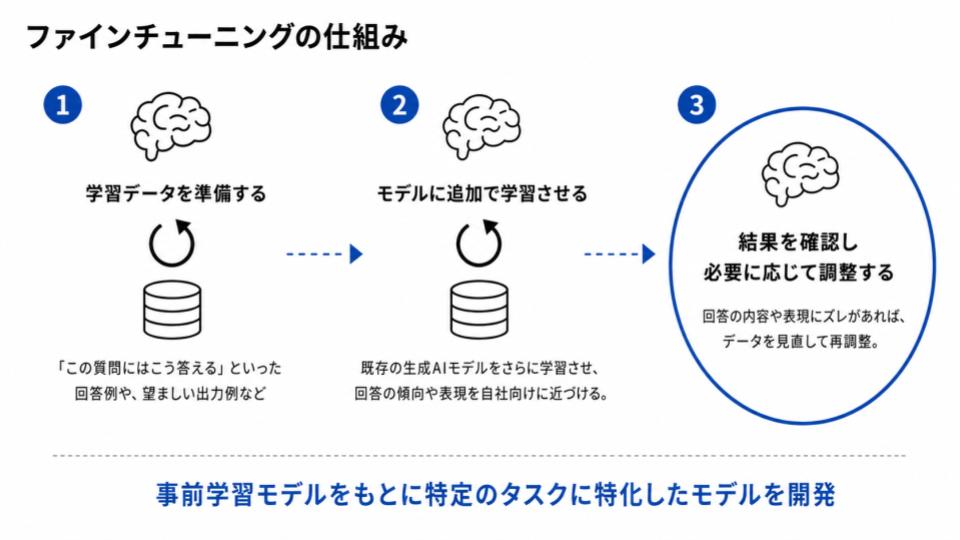
- 学習データを準備する 「この質問にはこう答える」といった回答例や、望ましい出力例など、生成AIに学習させるためのデータを用意します。
- モデルに追加で学習させる 準備したデータをもとに、既存の生成AIモデルをさらに学習させ、回答の傾向や表現を自社向けに近づけていきます。
- 結果を確認し必要に応じて調整する 学習後のモデルが意図した通りに動くかを確認し、回答の内容や表現にズレがあれば、データを見直して再調整します。
ファインチューニングでは情報を外から探して使うのではなく、モデル自体に回答の傾向やパターンを学習させることが特徴であり、同じような質問に対して安定した回答を返しやすくなります。
RAGとファインチューニングにおける7つの違い
RAGとファインチューニングは、「生成AIを自社仕様に近づける」という点で共通していますが、設計や運用上の課題もまったく異なります。
ここでは7つの視点でそれぞれの特徴を比べながら、どのような違いがあるのかを整理します。
- 知識の持たせ方の違い
- 最新情報への対応力の違い
- 回答の根拠の違い
- 導入時における準備の違い
- コスト構造の違い
- 出力スタイルの違い
- セキュリティ設計の違い
知識の持たせ方の違い
RAGとファインチューニングの大きな違いは、生成AIに知識をどのように持たせるかにあります。
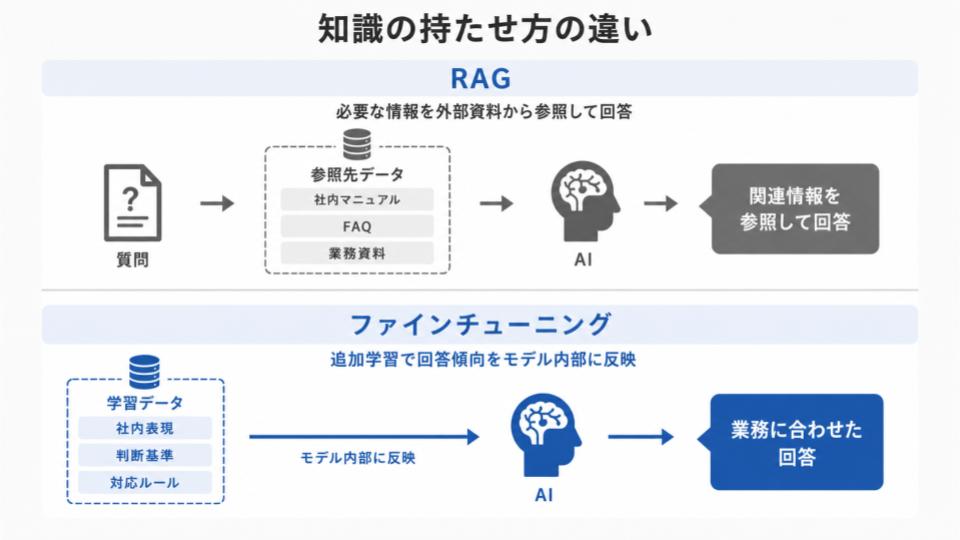
RAGは、必要な情報をモデルの外側に置き、質問に応じてその情報を参照しながら回答する仕組みです。
社内マニュアルやFAQ、業務資料などを参照先として用意しておき、生成AIがそこから関連する情報を取り出して答えるイメージです。
一方、ファインチューニングは、特定のデータを使ってモデルを追加学習させることで、回答の傾向や判断パターンをモデル内部に反映させる手法です。
外部の資料を都度参照するというより、生成AIモデルが出力する内容を業務に合わせて調整します。
最新情報への対応力の違い
RAGは、参照する文書やデータベースを更新するだけで、生成AIの回答に新しい情報を反映できます。
社内マニュアルの改定、製品情報の変更、FAQの見直しなどがあった場合でも、参照元を更新すれば対応できます。モデル自体に手を加える必要がないため、情報の変化に合わせて運用しやすい点が特徴です。
一方、ファインチューニングは、学習させた時点のデータのみ反映されます。
情報が更新された場合は、モデルを再学習させるか、少なくとも再評価を行う必要があるため、頻繁に変わる情報を扱う業務では運用負荷が大きくなりやすいです。
規程改定やサービス内容の変更が多い業務では、参照元の更新で対応しやすいRAGの方が扱いやすい場合があります。
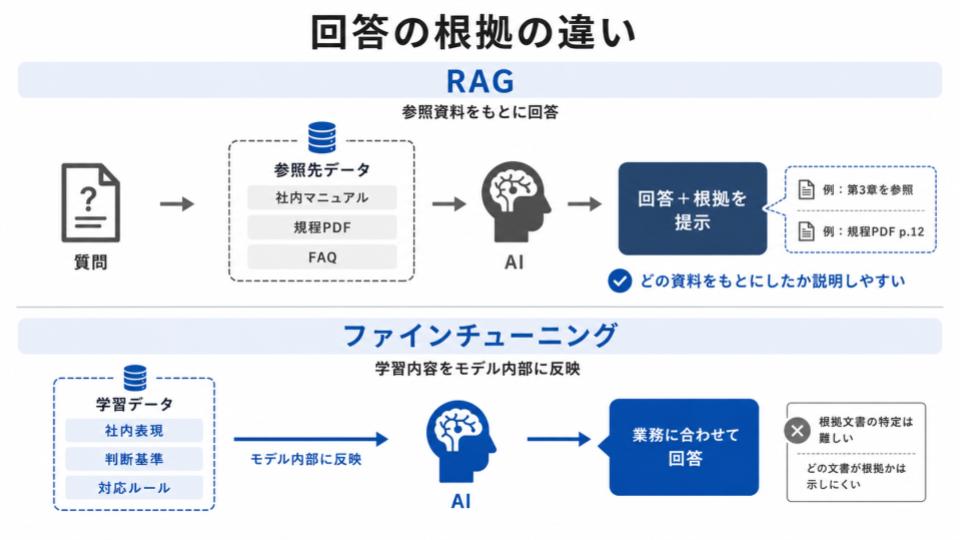
回答の根拠の違い
「なぜその回答になったのか」を説明できるかどうかという点でも、RAGとファインチューニングには違いがあります。
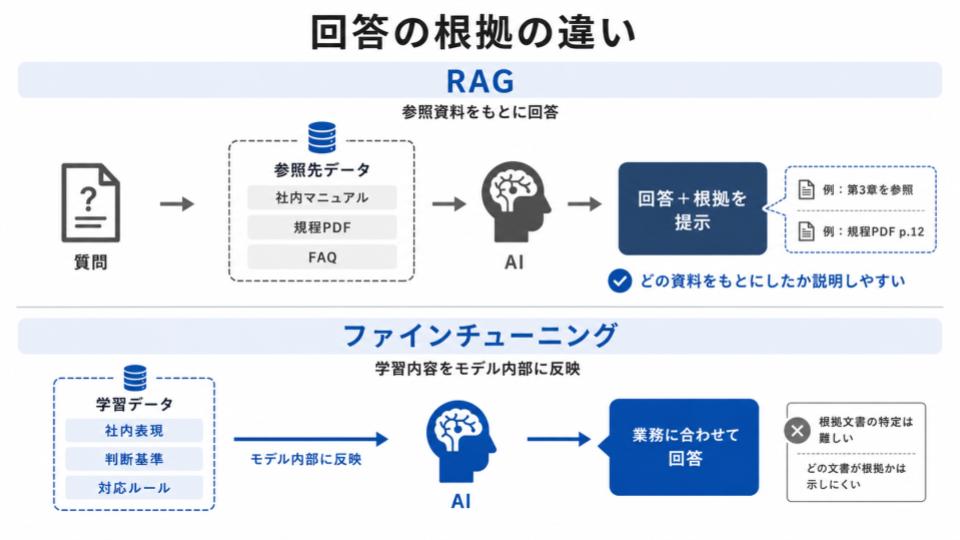
RAGは、回答を生成する前に特定の文書やデータを検索し、それを参照しながら答える仕組みのため、「どの資料をもとに回答したか」を出力に含めやすい特徴があります。
たとえば、「社内マニュアルの第3章を参照」「規程PDFの該当ページをもとに回答」といった形で、回答の出どころを示しやすくなるのです。
一方、ファインチューニングは、学習データの内容や傾向をモデル内部に反映させるため、回答の品質を高められる一方で、「どの文書が根拠になったのか」を生成AIの回答から確認することは難しくなります。
ミスが許されない業務や、担当者が内容を確認しながら使いたい場面では、根拠を示しやすいRAGの方が設計しやすいでしょう。
導入時における準備の違い
RAGとファインチューニングはどちらも、導入前に準備が必要ですが、準備する内容は異なります。
RAGでは、社内文書やマニュアル、FAQなどを生成AIが参照しやすい形に整える必要があります。
古い情報や重複した文書を整理し、内容を適切な単位に分割したうえで、カテゴリや更新日などの情報を付けておくことが重要です。
一方、ファインチューニングでは、モデルに学習させるためのデータを準備します。
単に資料を集めるだけではなく、「どのような質問に、どう答えるべきか」が分かる質問回答データや、望ましい出力例を用意する必要があり、データの作成や形式の統一に手間がかかります。
導入前には、データの収集や整理、クレンジングなどさまざまな準備が必要であり、自社だけで進めると想定以上に工数がかかることがあります。
リベルクラフトでは、こうした導入前のデータ整備から参照データの選定、RAG検索精度の検証、業務フローへの組み込みまでを一貫して支援しているため、自社だけでは負担になりやすい準備工程もスムーズに進められます。
「何から手をつければよいかわからない」「自社だけで準備を進めるのが不安」という段階からでも、ぜひお気軽にご相談ください。
⇨リベルクラフトへの無料相談はこちら
コスト構造の違い
コスト面では、初期と運用で負担の内容が異なります。
RAGは、モデルを再学習させずに構築できるため、初期費用を抑えやすい傾向があります。
一方で、運用を続けるうえでは、検索処理やベクトルデータベースの維持、参照データの更新管理といったコストが継続的に発生します。
利用量が増えるほど処理コストも増えやすいため、想定される利用頻度をもとに試算しておくことが重要です。
ファインチューニングは、学習データの作成や計算資源が必要になるため、初期費用が高くなりやすい手法です。
一方で、一度モデルを構築すれば、毎回外部データを検索する仕組みは不要になるため、運用フェーズではシステム構成を比較的シンプルにできる場合があります。
どちらが安いかは、導入規模や利用頻度、情報の更新頻度によって変わり、短期的な費用だけでなく、運用期間全体のコストを見て比較することが大切です。
出力スタイルの違い
RAGは、プロンプト設計によって文体や回答形式をある程度整えることができます。
ただし、毎回参照する検索結果や入力内容によって、表現が少し変わることがあるため、常に同じ形式で出力したい場合は、追加の設計が必要になることがあります。
一方、ファインチューニングは、望ましい出力形式や文体を学習データとして与えることで、出力の傾向を安定させやすい手法です。
営業メールの文体をそろえたい、FAQの回答フォーマットを固定したいといった場合に適しています。
出力の形式やトーンを業務に合わせて厳密にそろえたい場合は、ファインチューニングの方が向いているケースがあります。
セキュリティ設計の違い
セキュリティの観点でも、RAGとファインチューニングでは注意すべきポイントが異なります。
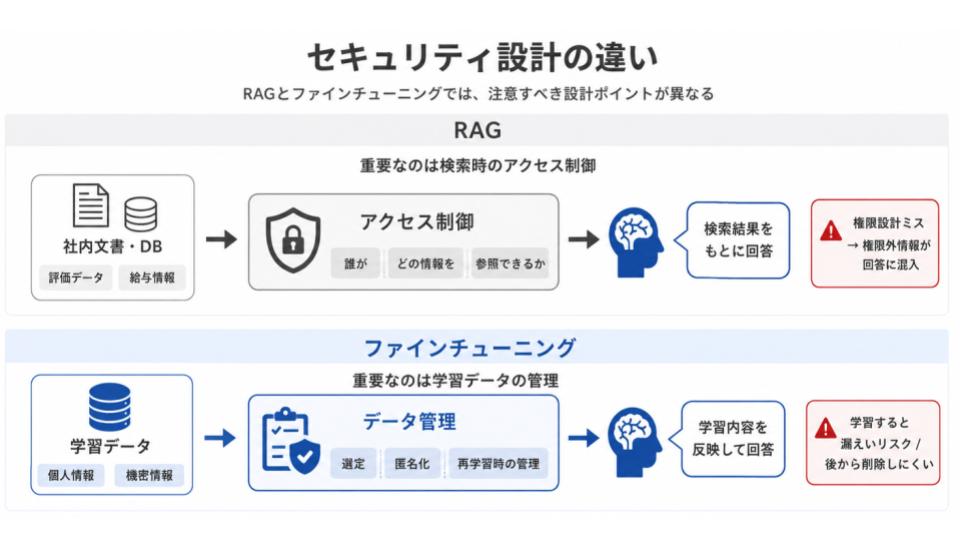
RAGでは、社内文書やデータベースを検索対象にするため、「誰がどの情報を参照できるか」というアクセス制御の設計が重要になります。
たとえば、役員や人事担当者しか閲覧を想定していない評価データや給与情報がデータベースに含まれている場合、権限設計を誤ると本来見られない情報が回答に含まれるリスクがあります。
一方、ファインチューニングで特に注意すべきなのは、学習データの内容です。
個人情報や機密情報を学習データに含めると、後から回答として漏れ出るリスクがあり、一度学習させた情報は簡単に削除できるものではありません。
そのため、学習データの選定や匿名化、再学習時の情報管理を徹底する必要があります。
RAGのセキュリティリスクと対策についてより詳しく知りたい方は、具体的な対策方法をまとめた以下の記事もあわせてご覧ください。
RAG構築におけるセキュリティリスクと5つの対策方法。対策が必要な理由も紹介
RAGがおすすめなユースケース
7つの違いを踏まえると、RAGがおすすめなのは「最新情報の反映が重要で、根拠を明示する必要のある業務」です。
ここでは代表的な3つのユースケースを紹介します。
- 社内文書・マニュアルを参照する社内問い合わせ対応
- 法務・契約・コンプライアンス関連の確認業務
- 最新情報を反映する調査・レポート作成
社内文書・マニュアルを参照する社内問い合わせ対応
社内問い合わせ対応は、RAGとの相性がよく多く企業で活用されています。
人事・総務・情報システムなどへの問い合わせは、「有給の申請方法は?」「このシステムのエラーはどう対応する?」といった、社内規程やマニュアルに答えが書いてある質問が多いです。
たとえば、
- 有給休暇や経費精算など、社内規程に関する質問
- 業務システムの操作方法やエラー対応
- 入社・退職・異動時の手続き
- セキュリティルールや社内ツールの利用方法
のような問い合わせに関して、RAGを構築すれば、文書をデータベースとして整備し、質問に対して生成AIが関連箇所を検索しながら回答を返せるようになります。
24時間参照できる状態になるため、担当者不在の時間帯でも解決しやすくなるでしょう。
法務・契約・コンプライアンス関連の確認業務
正確さが求められる法務・契約・コンプライアンス関連の業務でも、RAGは役立ちます。
たとえば、
- 契約書内の特定条項や条件の確認
- 社内規程・コンプライアンスガイドラインとの整合性チェック
- 過去の契約書や関連資料からの類似事例の検索
- 法令・社内ルールの改定内容に基づく確認
などにRAGを活用でき、回答の根拠となる文書を検索して参照できるため、「契約書の第X条をもとに回答」といった形で根拠を示しながら答えることができます。
法令や内部ガイドラインが更新された場合でも、データベースを整備すれば新しい内容をすぐに反映できるため、常に最新の基準に沿った確認が可能です。
ただし、法的な判断を最終的に生成AIに任せることは避けるべきであり、生成AIが参照した文書を人が確認することで、より安全に活用できます。
最新情報を反映する調査・レポート作成
最新の社内データや過去の報告書・議事録を参照しながら現状をまとめたい、複数の部署にまたがる情報を横断的に調べたいケースでは、必要な情報を探し出して整理する作業が大きな負担になります。
しかし、
- 過去の報告書や議事録をもとにした経緯の整理
- 部署横断のデータや資料を参照した現状分析
- 最新の社内データを反映したレポート作成
のような調査・レポート作成にRAGを活用すると、文書を一括で検索対象にしたうえで、質問に応じた形で情報を引き出せます。
情報が頻繁に更新される環境や、過去の蓄積データを活かした分析・まとめ業務を効率化したい場合に向いています。
RAGの具体的な活用事例をさらに詳しく知りたい方は、17社の事例を業種・用途別にまとめた以下の記事もあわせてご覧ください。
RAGの活用事例17選。実装の手順と成功させるポイントも解説
RAGの導入を検討しているが、データ整備や構築方法で悩んでいるという方は、リベルクラフトへご相談ください。リベルクラフトでは、ビジネス課題の整理から最適な手法の選定、システムの構築・運用改善まで一気通貫で伴走支援しています。
まずは以下のリンクからお気軽にお問い合わせください。
⇨リベルクラフトへの無料相談はこちら
ファインチューニングがおすすめなユースケース
ファインチューニングが向いているのは、「出力の形式やトーンを業務に合わせて固定したい」「特定の専門領域での判断精度を高めたい」という場面です。
生成AIの回答形式をより自社仕様に近づけたいときに向いています。
- 自社独自の文体・トーンを反映した文章生成
- 専門領域に特化した分類・判定業務
- 定型業務の自動処理・ワークフロー組み込み
自社独自の文体・トーンを反映した文章生成
ファインチューニングは、社内で統一された文体や言い回しで文章を生成したい場合に役立ちます。
一定の文体で大量の文章を作成したい場合、汎用的な生成AIでは出力にばらつきが出やすくなります。
たとえば、
- 営業メールや提案文の作成
- プレスリリースやお知らせ文の作成
- カスタマーサポートの返信文の作成
などへファインチューニングを活用すると、自社の理想的な文章例を学習データとして与えることで、生成AIが自然にそのスタイルで出力するようになります。
「この書き方でお願い」とプロンプトに毎回書き添えなくても、自社のトーンに合った文体が安定して出力されます。
専門領域に特化した分類・判定業務
特定の業界や自社独自のルールに基づいた分類・判定業務でも、ファインチューニングが活用できます。
汎用的な生成AIでは、自社独自の判断基準に沿った回答の精度が出にくいことがあります。
たとえば、
- 問い合わせ内容のカテゴリ分類や担当部署への振り分け
- 契約書・申請書などの社内基準に基づく判定
- レビューやアンケート回答の感情分類
のような分類・判定業務にもファインチューニングを導入し「この内容はAカテゴリ」「これはNG判定」といった自社の正解データを学習させると、汎用モデルでは難しいニュアンスの判断も処理できるようになります。
大量のデータを一定の基準で素早く仕分けたい業務など判断の基準が明確で、処理量が多いほど費用対効果が上がりやすいです。
定型業務の自動処理・ワークフロー組み込み
毎回同じ形式の処理を繰り返す定型業務でも、ファインチューニングが活用できます。
たとえば
- 発注書や注文データの定型フォーマット化
- 定期レポートや報告書の雛形生成
- 問い合わせ内容の要約と項目別入力
のような業務はファインチューニングによって、生成AIが「いつもこの形式で返す」という型を学習し決まった形式で安定して回答できます。
一度モデルができれば、外部データベースを毎回検索する必要がないため、ワークフローに組み込んで自動化しやすい点もメリットです。
担当者が手動で繰り返していた定型作業を自動化し、より判断が必要な業務に人の時間を使えるようにしたい場合に向いています。
RAGとファインチューニングの使い分け判断基準
ここまでの比較とユースケースをふまえると、判断の軸は主に2つに絞られます。
「生成AIに何を参照させたいか」と「出力の何を安定させたいか」この2点を整理するだけで、自社に合った手法が見えてきます。
- 最新情報や社内データを参照したいならRAG
- 文体や回答形式を業務に合わせて最適化したいならファインチューニング
最新情報や社内データを参照したいならRAG
社内マニュアル・FAQ・製品情報・規程など、自社固有の情報を生成AIが参照しながら答えてほしい場合はRAGが向いています。
RAGは、外部のデータベースやナレッジベースから必要な情報を検索し、その内容をもとに回答を生成するため、LLMそのものを再学習させるわけではありません。
参照元の文書を更新すれば、新しい情報をすぐ回答へ反映できるため、情報が頻繁に変わる業務環境でも精度を保ちやすいという特徴があります。
特に以下のような状況はRAGが向いていると判断できるでしょう。
- 社内情報が定期的に更新される
- 回答の根拠を明示しながら使いたい
- 特定のデータベースや文書を参照させたい
RAGの精度をさらに高めたい方や、導入後の改善施策を具体的に知りたい方は、成功事例を交えて解説した以下の記事もあわせてご覧ください。
参照記事:RAGの精度向上施策・事例紹介 〜成功事例からRAGの具体的活用方法を学ぶ〜
文体や回答形式を業務に合わせて最適化したいならファインチューニング
出力の形式やトーンを自社仕様に固定したい場合は、ファインチューニングが向いています。
ファインチューニングは、既存の学習済みモデルに追加学習を行い、望ましい回答例や分類データを学習させることで、出力の傾向を安定させやすくなります。
たとえば、
- 毎回同じ構成で返信文を生成したい
- 記事やコンテンツのトーンを統一したい
- 問い合わせ内容を一定の基準で分類させたい
といった場合には、ファインチューニングが適しています。
生成AIに「どんな形で答えるべきか」を学習させることで、プロンプトで毎回指示しなくても安定した出力が得られるようになるでしょう。
RAGの構築・運用は「リベルクラフト」
ここまで、RAGとファインチューニングを7つの視点で比較し、それぞれのユースケースと使い分けの判断基準を解説してきました。
「RAGの方が自社の業務に合いそうだ」と感じた方も多いかもしれません。ただ、RAGは参照先のデータを用意しただけでは精度が出ません。
チャンク設計や検索精度の検証、アクセス権限の設計など、成果を出すまでには専門的な知識が必要になります。
社内にノウハウがない状態でこれらを自社で一から進めるのは、期間やコストが多くかかってしまうことがあります。そんなときは、リベルクラフトへご相談ください。
リベルクラフトでは、参照させるデータの選定・ナレッジの整理・検索精度の検証から業務フローへの組み込みまでを一貫して設計・支援しています。
また、手法の選定段階からご相談いただくことで、RAGとファインチューニングのどちらが自社の課題に合っているかという整理からもお手伝いできます。
構築して終わりではなく、精度の検証と継続的な改善まで含めた運用設計も一体で提供しているため、「導入したけれど現場で使われない」という状態を防ぐことができます。
現場で実際に成果が出る生成AIを目指したい企業は、まずは以下のリンクからお気軽にお問い合わせください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



