RAGにおけるナレッジベースの構築方法。3つの重要な理由と注意点も解説

「RAGを導入したのに期待した回答が返ってこない」「社内文書を読み込ませたはずなのに的外れな答えが出る」などの悩みを持つ方は少なくありません。
その原因は、ナレッジの整備がうまくできていないことがよくあげられます。
RAGは参照するデータの質によって精度が変わるため、優れたモデルを使っても、それだけでは回答の精度は安定しません。
そこで本記事では、
- RAGにおける「ナレッジ」の意味
- ナレッジ整備が重要な3つの理由
- ナレッジベースの具体的な構築手順
- 構築時の注意点
をわかりやすく解説します。すでにRAGを導入している方も、これから検討している方も、ぜひ社内データの整理を見直すきっかけにしてみてください。
「RAGのナレッジ整備から構築・運用まで任せたい」という方は、リベルクラフトへご相談ください。
リベルクラフトでは、社内データのナレッジ化やRAG検索基盤の構築から運用改善まで、業務の内容に合わせて一貫して対応しています。
まずは以下のリンクからお気軽にお問い合わせください。
⇨リベルクラフトへの無料相談はこちら
そもそもRAG(検索拡張生成)とは?
RAGとは、生成AIが回答を作る前に社内文書やマニュアルなどを検索し必要な情報を参考にして答える技術です。
生成AIは、あらかじめ学習した内容をもとに回答するため、社内マニュアルや規程のように、学習していない内容はそのままでは正しく答えられません。
そこで、RAGを導入することで
- ユーザーの質問に関係する情報を社内文書やマニュアルなどから探す
- 見つけた情報を、生成AIが参考にできるようにする
- その情報をもとに、生成AIが回答を作る
という仕組みにより、社内にある情報を活用できるようになります。
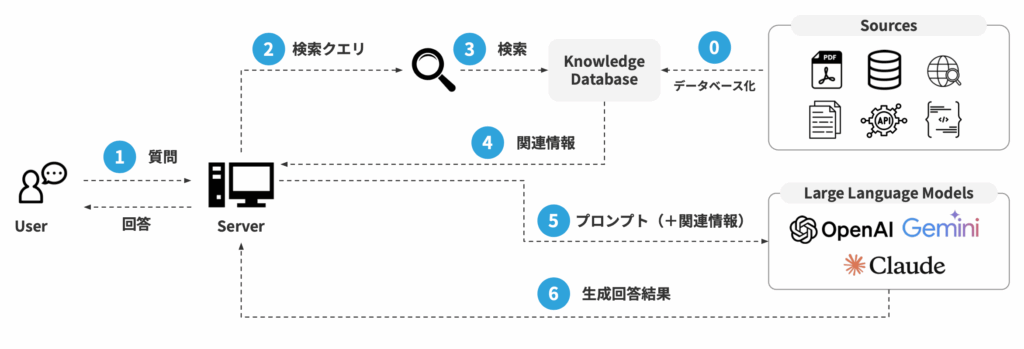
RAGでは、実際の社内データを参考にして回答するため、「どの情報をもとに答えたのか」がわかりやすくなり、事実と違う回答も起こりにくくなります。
社内文書をきちんと整理しておくことで、会社特有の業務に関する質問にも答えやすくなり、多くの企業で活用が進んでいます。
RAGにおけるナレッジとは?
RAGにおけるナレッジとは、生成AIが回答を作るときに参照する情報を、検索しやすい状態に整理したもののことです。
単にデータが存在しているだけではなく、きちんと整理されていて、必要なときに取り出せる状態になっていることが重要です。
たとえば、社内に大量の文書があったとしても、フォルダにただ入っているだけでは検索しようがありません。
- この情報は何に関するものか
- どの部署向けか
- いつ更新されたものか
といった整理がされていて初めて、生成AIが正しく使える知識になります。
また、RAGは文書の中にある単語や文章を手がかりにして情報を探すため、ファイル内容の用語を統一することなどの整理も大切になります。
具体的に、ナレッジを整理する考え方として、
- RAGが参照する知識をためておく「ナレッジベース」
- 情報同士の関係性を整理する「ナレッジグラフ」
の2つがあり、以下で詳しく説明します。
RAGが参照する知識をためておく「ナレッジベース」
ナレッジベースとは、RAGが回答の根拠にする情報を保管し、必要なときに取り出せるようにした土台のことです。
社内WikiやラベルのついたGoogle Driveの共有フォルダのイメージに近く、製品マニュアル、社内ルール、FAQなどを1か所に集めたAIが見に行ける場所を意味します。
たとえば、バラバラに保存された社内文書をナレッジベースとしてまとめると、
- 「〇〇製品の保証期間はどこに書いてある?」
- 「この申請手続きのフローは最新のものか?」
といった質問にも、生成AIが該当する文書を探し出して回答できるようになります。
情報が整理されているからこそ、生成AIが使える知識として扱えるようになります。
情報同士の関係性を整理する「ナレッジグラフ」
ナレッジグラフとは、情報と情報の関係性をわかりやすく整理する仕組みのことです。
たとえば、製品情報であれば
- 「製品A」には「製品Aのマニュアル」と「製品AのFAQ」がある
- 「製品B」には「製品Bのマニュアル」と「製品BのFAQ」がある
- 「製品A」と「製品B」は、どちらも「サポート窓口C」が対応している
のようなつながりをあらかじめ整理しておきます。
RAGでは「製品Aについて教えてください」と質問したとき、製品Aと直接書かれた文書を探しにいき、関連する情報までは十分に拾えないことがあります。
ナレッジグラフを導入すると、製品Aを起点に
- 関連するマニュアルやFAQ
- 対応しているサポート窓口
- 同じ窓口が担当する製品Bの情報
などをつながりをたどって引き出せるようになり回答の精度も高まりやすくなります。
RAGでナレッジの整備が重要な3つの理由
RAGでは、「とりあえず文書を入れれば動く」と思って進めると、後から思ったように機能しないケースが多いです。
ここでは、なぜナレッジ整備がそこまで重要なのか、理由を3つ説明します。
- 生成品質はナレッジに依存するため
- 文書が存在するだけでは理解に限界がある
- 実務で使うには運用性と信頼性が必要なため
生成品質はナレッジに依存するため
RAGの回答品質は、使っている生成AIモデルの性能に加え、ナレッジの整備状態が大きく影響されます。
- 古い情報と新しい情報が混在している
- 内容に重複や矛盾がある
- 文書の切り方が粗く、文脈が途中で切れている
といった状態のまま文書を入れてしまうと、余計な情報や不正確な内容が回答として引き出されます。
たとえば、製品の価格が改定された際に、旧価格と新価格の文書が両方残っていた場合、AIは旧価格を答えてしまうことがあります。
生成AIが参照するデータが整理されていないと回答の質は上がらないため、正確な情報をもとにナレッジを設計する必要があります。
文書が存在するだけでは理解に限界がある
「社内文書をそのままデータベースに入れれば使える」と思いがちですが、実際にはそうではなくそのまま検索できる情報になっていないケースがあります。
具体的には、社内の文書は
- 表記ゆれ:「会議」「MTG」「ミーティング」など、同じ意味でも言い方が異なる
- 略語・社内用語:第三者が見たときに意味がわからない表現がある
- 重複・矛盾:別々の部署が作った資料に、食い違う内容がある
- 更新履歴が混在:改訂前と最新版の資料の両方が保存されている
などの内容が含まれていることが多いです。
このような状態では、生成AIが質問の意図に合う情報を正確に探すことが難しくなります。
そのため、文書を意味のまとまりで区切るチャンク分割や用語の統一といったナレッジの整備が必要になります。
RAGにおける社内データを活用する際の注意点や整備の考え方については、以下の記事も参考にしてください。
参照記事:ChatGPT×RAGで社内データを活用する5つの手順。精度を向上させる施策も解説
実務で使うには運用性と信頼性が必要なため
試しに動かして確認する段階では、RAGはそれなりに機能しているように見えることが多いです。
しかし、実務で継続的に使おうとすると、
- 制度や手順が変わったのに、データベースの情報が更新されていない
- 複数のバージョンの文書が混在していて、どれが正しいかわからない
- 回答が間違っていたとき、どの文書が根拠になったか追えない
などが問題になりやすいです。
ナレッジがきちんと整備されていれば、
- 回答がどの文書をもとに回答しているか
- その文書自体が正しい内容であるか
なども正確に確認でき、問題が起きたときに原因を特定しやすいです。
RAGを長く使い続けるためには、ナレッジの中身を定期的に見直し・更新できる仕組みを、最初からセットで用意しておくことが大切です。
ナレッジを活用したRAGの具体的なユースケース
ナレッジをしっかり整備すると、RAGは実際の業務でどのように役立つのでしょうか。
ここでは、よく使われる活用シーン3つを解説します。
- 問い合わせ対応の自動化・高度化
- 社内ナレッジの共有と技術継承
- 営業支援とパーソナライズ提案
問い合わせ対応の自動化・高度化
| 項目 | 内容 |
|---|---|
| 活用するナレッジ | FAQ、製品マニュアル、価格表、製品ドキュメント |
| RAG内容 | ユーザーの質問に対して関連文書を検索し、根拠に基づいた回答を自動生成する |
| 主なメリット | 正確な回答を24時間提供でき、サポート担当者の対応工数を削減できる |
問い合わせ対応では、「FAQ」「マニュアル」「製品ドキュメント」「価格表」などをナレッジとして活用し、ユーザーからの質問に対して生成AIが適切な回答を生成できます。
たとえば、ユーザーが「〇〇製品の価格はいくらですか?」と質問した場合、RAGでは最新の価格表や製品資料を生成AIが検索し、その内容をもと回答を生成します。
主な活用シーンは
- 製品価格や仕様に関する問い合わせ対応
- 操作方法や設定手順の案内
- エラー発生時のトラブルシューティング
- よくある質問への一次回答
などです。
また、ユーザーの質問の意図を汲み取ることにより、よくある質問に答えるだけでなく、問い合わせ内容に応じて関連する注意点や次に取るべき対応まで案内できます。
社内ナレッジの共有と技術継承
| 項目 | 内容 |
|---|---|
| 活用するナレッジ | 設計書、議事録、規程集、業務マニュアル、過去事例 |
| RAG内容 | 社内文書を横断検索し、社員の自然文質問に対して必要情報を整理して回答する |
| 主なメリット | 情報探索時間を短縮し、知識の属人化を防ぎながら教育・引き継ぎを効率化できる |
多くの企業では、必要な情報が社内ポータル、チャット、個人フォルダなどに分散しており、情報を知っている人に聞かなければ業務が進まない、という属人的な状況が起こりがちです。
RAGを活用すれば、文書に蓄積された知識を検索・活用できるため、社員は必要な情報に素早くアクセスできます。
たとえば、社員が「〇〇プロジェクトの設計方針は?」と質問すると、RAGは関連する設計書や議事録を検索し、必要な情報を整理して回答します。
主な活用シーンは
- 業務手順や社内ルールの確認
- 過去プロジェクトの設計方針や意思決定の参照
- 類似トラブルの解決策の検索
- 新入社員や異動者向けのオンボーディング支援
などです。
特に、ベテラン社員のノウハウやこれまでの判断を活用しやすくなり、技術を新たな担当者へ伝えやすくなり、組織全体の力も高まります。
営業支援とパーソナライズ提案
| 項目 | 内容 |
|---|---|
| 活用するナレッジ | CRM、商談履歴、提案履歴、成功事例、商品情報 |
| RAG内容 | 顧客情報や商品データを検索し、顧客に合う候補商品や提案内容を生成する |
| 主なメリット | 顧客ごとの提案精度を高め、商談準備や提案資料作成を効率化できる |
営業活動では、顧客の業種、困っていること、これまでのやり取りをふまえて提案することが大切です。
ただ、必要な情報がCRMや資料フォルダなど、いろいろな場所に分かれていると、提案の準備に時間がかかってしまいます。
RAGを使うことで、お客様の情報や商品情報をまとめて確認でき、顧客に合った提案を短時間で準備できます。
たとえば
- お客様ごとにおすすめ商品を探す
- 似ている商品の違いを整理する
- 過去にうまくいった提案を参考にする
- 提案書や商談資料の下書きを作る
のような使い方ができ、新人の営業担当者や店舗スタッフでも、提案の質を安定させやすくなります。
また、過去にうまくいった事例を使うことで、顧客が納得できる提案資料を作りやすくなります。
RAGの活用シーンはほかにも多くあります。具体的なユースケースについては、以下の記事で詳しく紹介していますのでぜひご覧ください。
参照記事:RAGの活用事例17選。実装の手順と成功させるポイントも解説
RAGのナレッジベースを構築する方法
ナレッジベースの構築はデータの整理から検索の設計、継続的な改善まで、ステップを踏んで進めることが重要です。
ここでは、実務での構築を5つに分けて解説します。
- 1.ユースケースと回答要件を定義する
- 参照対象データのノイズを除去する
- チャンク設計とメタデータ設計を行う
- 検索基盤へインデキシングし検索方式を設計する
- 検索ログと回答ログを用いて継続的に最適化する
1.ユースケースと回答要件を定義する
最初にやるべきことは、「どの業務課題に対してRAGを使うのか」を明確にすることです。
用途によって必要なデータも変わり、どういう内容が「良い回答」になるかの基準も異なります。たとえば、
- 社内ヘルプデスクの自動化が目的なら、FAQや手順書が対象になる
- 営業支援が目的なら、製品資料や過去の提案事例、顧客データが対象になる
といったように、この定義をあいまいにしたまま構築を進めると、「どのデータを入れるべきか」が判断できず、関係のない資料まで入ってしまいます。
生成AIに何を答えさせたいのか、どんな質問に対応する必要があるのかを先に決めることが、その後の設計すべてに影響します。
2.参照対象データのノイズを除去する
使う目的が決まったら、次は対象データを集めて整理します。
ナレッジベースに入れる文書から、必要のない情報を取り除くことでRAGの品質を大きく向上できます。
検索の精度が下がってしまう代表的なノイズとその対処方法は以下の通りです。
| アプローチ | 内容 |
|---|---|
| 不要文字・制御文字の削除 | 余計な空白や改ページ記号、不要な文字などを取り除く |
| 大文字小文字の正規化 | すべて小文字に揃えるなど表記を統一し、「Apple」と「apple」が別の情報として扱われる問題を防ぐ |
| ストップワードの除去 | 「の」「が」「は」「a」「the」など意味に影響しない単語を取り除く |
| スペルミス・表記ゆれの修正 | タイポや表記ゆれを修正し、検索にヒットしやすい状態に整える |
| 不要コンテンツの除去・分離 | ヘッダー・フッター・広告など本文と無関係なテキストを取り除く |
| 重複データの処理 | 同一・類似した文書が複数ある場合、1つだけ残してデータを整理する |
「使える文書だけを選ぶ」という意識で、ここで丁寧に整理しておくことで、検索時に関係のない情報が混じってしまうリスクを減らせます。
3.チャンク設計とメタデータ設計を行う
文書が整理できたら、意味のまとまりごとに適切な単位へ分割(チャンク化)する作業に入ります。
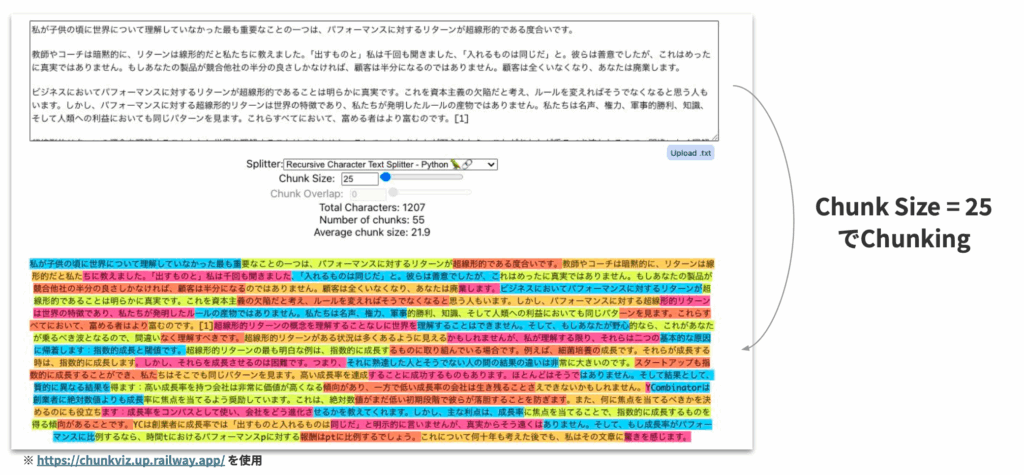
チャンク設計では
- 細かすぎると前後のつながりが失われ断片的な情報しか取り出せない
- 大きすぎると関係の薄い情報まで一緒に入り込んでしまう
という課題があるため、適切に設計する必要があり、基本的には1つのチャンクが「ひとつの意味のまとまり」となるようにします。
マニュアルであれば手順ごと、FAQであれば質問と回答のセットをひとまとまりにするといったイメージです。
あわせて重要なのが、文書につける補足情報であるメタデータをつけることです。
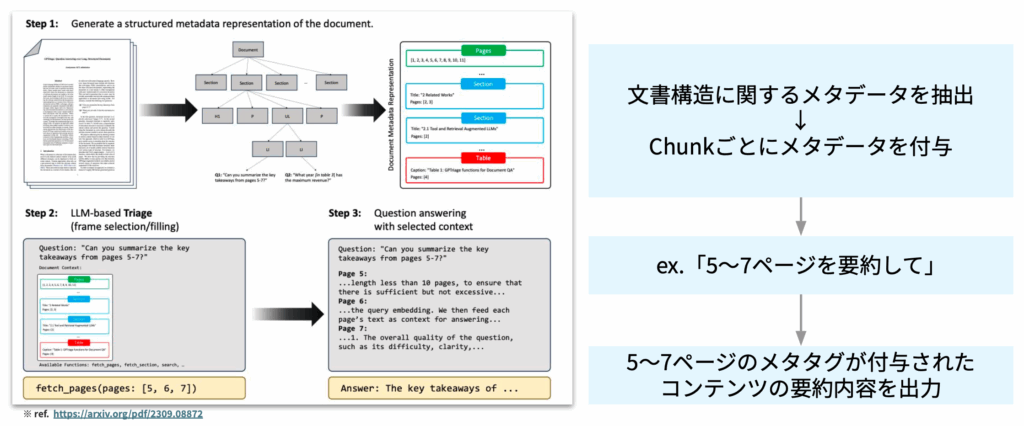
メタデータは、文書構造から情報を抽出してチャンクごとに紐づける形でつけていきます
たとえば「5〜7ページを要約して」という質問に対して、それぞれ5、6、7ページのメタデータが付与されたチャンクだけを絞り込めるようになります。
また、「2024年以降に更新された営業部門向けの手順書だけを検索対象にする」といった細かい絞り込みも可能になり、大量の文書を扱うほど、メタデータが重要になります。
4.検索基盤へインデキシングし検索方式を設計する
次に、チャンクを検索基盤に登録し、どのような方式で情報を検索するかを設計します。検索方式には大きく次の3つがあります。
| 検索方式 | 仕組み | 強み | 弱み |
|---|---|---|---|
| キーワード検索(全文検索) | 入力した語句と一致する文書を探す | 製品名・型番・エラーコードなど明確な語句の検索 | 言い換えや表現の違いに対応できない |
| ベクトル検索 | 文章の意味を数値化して比較する | 自然な言葉での質問、意味が近い表現の検索 | 固有名詞や数字の完全一致には弱い |
| ハイブリッド検索 | 上記2つを組み合わせる | 幅広い質問に精度よく対応 | 設計・調整のコストがかかる |
キーワード検索とベクトル検索にはそれぞれ得意・不得意なことがあるため、実際にはキーワード検索とベクトル検索を組み合わせたハイブリッド検索を使うことが多いです。
両方の検索結果にまとめる手法を使うことで、「製品名で絞り込みながら、意味の近い表現にも対応する」といった柔軟な検索が実現できます。
5.検索ログと回答ログを用いて継続的に最適化する
システムを動かし始めた後も、精度は運用しながら継続的に高めていく必要があります。
最初から完璧な精度を目指すより、ログをもとに
- 答えられていない質問の傾向を把握する
- 回答がずれる場合は、チャンクの区切り方を見直す
- 検索漏れが多い場合は、付与しているメタデータを見直す
- プロンプトを調整し、回答の精度や表現を整える
のように少しずつ改善を重ねていくことが大事です。
「どこで精度が落ちているか」を特定し、「データの中身」「検索の設計」「AIへの指示文のどこを直すべきか」などを判断・改善を続けることが、長期的な品質を保つことにつながります。
RAGの精度向上施策や具体的な改善事例について詳しく知りたい方は、以下の記事もあわせてご覧ください。
参照記事:RAGの精度向上施策・事例紹介 〜成功事例からRAGの具体的活用方法を学ぶ〜
RAGのナレッジベース構築における注意点
RAGのナレッジベースを構築する中で、見落としやすいポイントがあります。
ここでは、構築するにあたっての注意点を2つ紹介します。
- 情報量ではなく知識の鮮度を優先する
- 文書中心で設計しすぎると質問の意図とズレが出る
情報量ではなく知識の鮮度を優先する
「文書をたくさん入れるほど、RAGの精度が上がる」と思いがちですが、実際にはそうではありません。
むしろ、情報を増やすことで精度が下がってしまうケースのほうが多いです。
問題になりやすいのは
- 古い資料と最新版が同じ場所に保存されている
- 一時的な対応として作られた文書が残っている
- 複数のルールがありどれが正しいのかがあいまい
のような状況です。
こういった状態では、RAGが複数の情報を引き出したとき、どれが正しいかをAI自身は判断できず、古い情報を回答することがあります。
大切なのは「どれが正しい情報かを決めて、常に最新の状態に保つ」ことです。
情報の鮮度を保ち、内容のブレをなくすことが、質の高いナレッジベースの構築につながります。
文書中心で設計しすぎると質問の意図とズレが出る
ナレッジベースを作るとき、「どの文書を入れるか」ということが中心になりがちですが、良い文書を集めることと、検索がうまく機能するようにすることが大事です。
- 社内文書は、業務手順やルールを整理するため、「進め方」が中心
- ユーザーの質問は、「この場合どうする?」「この言葉の意味は?」といった質問の形
というように、社内文書とユーザーの質問の構成にはズレがあります。
たとえば、手続きの案内書には「申請手続き」という見出しがあっても、使う人は「出張費を精算したい」という言葉で質問し、この言葉のずれが、RAGがうまく情報を引き出せない原因になることがあります。
これを防ぐには、最初から使う人が「どんな言葉で」「どんな場面で聞いてくるか」を想定しておくことが大切です。
よく来る質問の言葉を見出しに取り入れたり、よくある質問を想定して文書の区切り方を決めるといった工夫が大事です。
RAGのナレッジベース構築は「リベルクラフト」へ
ここまで、RAGにおけるナレッジの考え方から、ナレッジベース・ナレッジグラフの役割、整備が重要な理由、具体的な構築手順、そして注意点まで解説してきました。
RAGはナレッジの整備次第で成果が大きく変わる技術です。
しかし実際に取り組もうとすると、データの見直し・チャンク設計・メタデータの付与・検索方式の選定・運用フローの整備と、専門知識が必要な場面が次々と出てきます。
- 何から手をつければいいかわからない
- 社内にノウハウがなく、構築を任せられる会社を探している
- 導入後の改善・運用まで継続してサポートしてほしい
そういった方は、リベルクラフトへお気軽にご相談ください。
リベルクラフトでは、社内データの整備からRAGの運用まで、一貫して支援しています。
ナレッジの品質確認・文書の整理、チャンク設計・メタデータ設計、検索基盤の構築、精度検証と改善サイクルの設計まで、業務の内容に合わせて設計します。
構築して終わりではなく、実際に現場で使われ続けるための運用設計まで含めて提供しているため、「導入したけど使われなかった」という状態を防げます。
RAGのナレッジベースを本当に機能する仕組みとして整えたいとお考えの方は、まずは以下のリンクからお気軽にお問い合わせください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



