AIで何ができるかを、自社データから逆算する|データ種別×AI手法の早見表で「作れるAI」を見つける

「AIで何ができるのか、結局のところよく分からないまま検討が止まっている」という方も多いでしょう。生成AIの話題は毎日のように流れてくるのに、いざ自社で何を作ればよいかとなると、手が止まってしまうのが実情かもしれません。
しかし、世の中のAI事例をいくら集めても、自社で「何を作るか」は決まりません。事例は他社の文脈で生まれたものなので、自社の業務やデータに当てはめ直す作業が抜けると、検討は前に進まないからです。
そこで本記事では、
- AIでできることの全体像と、逆に苦手なこと
- 自社データを起点に「作れるAI」を見つける、データ種別×AI手法の早見表
- 部門別に見た、業務データから作れるAIの具体例
- 候補を絞り込み、優先順位をつけて進める手順
についてわかりやすく解説します。AI・DX推進のご担当者や、経営企画でデータ活用を検討している方は、ぜひ最後までご覧ください。
自社のどのデータからどんなAIが作れるか整理したいという方は、リベルクラフトへご相談ください。
⇨リベルクラフトへの無料相談はこちら
AIで何ができるかが見えない原因|検討が止まる3つの壁
「AIで何ができるか」を考える前に、まずなぜ多くの企業で検討が止まってしまうのか、その原因を整理しておきます。ここを押さえると、後半の「作れるAIの見つけ方」が腑に落ちやすくなります。
成果が出る企業と出ない企業の差は「目的」にある
生成AIを業務で使っている企業の割合は、調査によって幅はあるものの50%を超え、いまも増え続けています。一方で「導入したのに期待ほどの成果が出ていない」という声も同じくらい増えています。使っている企業同士でも、成果に差が開き始めているわけです。
この差を生んでいるのは、技術力でも予算でもありません。「どのAIを作るべきか」という目的が定まっているかどうかです。目的が曖昧なままツールだけ配っても、各自がチャットで質問する個人利用にとどまり、業務の成果には結びつきません。逆に「自社の何を解決するAIを作るか」が決まっている企業は、投資の効果が見えやすくなります。
つまり、AIで何ができるかという問いは、技術を調べる前に「自社の業務とデータで何を解決したいか」という問いに置き換えると考えやすくなります。
AI企画が止まる3つの壁
実際にAIの活用を検討すると、多くの企業が次の3つの壁のどこかで止まります。
- 何ができるか分からず検討が進まない:AIの守備範囲が漠然としていて、自社で何を作れるのか見当がつかない
- やりたいことと自社データがつながらない:「こんなことができたら」という発想はあるのに、手元のデータと結びつけられない
- 使うべきAIのイメージが湧かない:解きたい課題はあるが、どんな仕組みで実現するのかが想像できない
この3つは別々の問題に見えますが、共通する原因は1つです。「自分たちが持っているデータ」と「AIの手法」が頭の中で結びついていないことです。この2つをつなぐ地図さえあれば、3つの壁はまとめて越えやすくなります。
AIでできることの全体像|機能カテゴリ別に押さえる
壁の原因が「データと手法が結びついていないこと」だとすると、まず手法の側、つまり「そもそもAIに何ができるのか」をざっくり把握しておくと話が早くなります。個別の製品名で覚えるのではなく、AIの機能を4つのカテゴリに分けて押さえると、後半の早見表ともつながります。
認識・理解する(画像・音声・言葉)
1つ目は、画像や音声、文章といったデータを読み取り、内容を理解する機能です。製品の画像から傷や異物を見つける画像認識、通話や会議の音声を文字に起こす音声認識、問い合わせ文の意図を読み取る自然言語処理などが当てはまります。人が目や耳で確認していた作業を、AIが代わりに大量にこなせるようになる領域です。
予測・分析する(数字から先を読む)
2つ目は、過去の数値データから将来を予測したり、異常を見つけたりする機能です。例えば、売上や来店数の需要予測、設備のセンサーデータからの異常検知、解約しそうな顧客の早期発見などがあります。経験や勘で判断していたことを、データの裏づけつきで見通せるようになります。
生成する(文章・画像・コードを作る)
3つ目は、文章・画像・コードなどを新しく作り出す機能です。いわゆる生成AIが担う領域で、文章の要約やメールの下書き、画像の作成、プログラムコードの生成などができます。「生成AIで何ができるか」という問いの中心がここで、たたき台づくりや下書きの自動化に向いています。
自動化・制御する(作業をAIに任せる)
4つ目は、決まった手順の作業を自動でこなしたり、機器を制御したりする機能です。書類の転記や仕分けといった定型作業の自動化、ロボットや設備の制御などがあります。さらに、複数の機能を組み合わせて一連の業務を自走させる「AIエージェント」も、この延長線上にあります。
この4カテゴリを頭に入れておくと、「AIで何ができるか」が漠然とした不安ではなく、4つの引き出しとして整理できます。あとは、自社のどのデータにどの引き出しを当てるか、という話になります。
AIが苦手なこと・任せきれないこと
できることの全体像をつかんだら、裏返しとして「AIが苦手なこと」も知っておくと、過度な期待や的外れな企画を避けられます。何でもできる魔法ではないという前提を持つほど、かえって使いどころが見えてきます。
AIが苦手とされるのは、おおむね次のような領域です。
- ゼロからの独創・クリエイティブ:過去のデータを学習して応答するため、前例のない発想や本当の意味での独創性は不得手です
- 倫理的な判断と最終責任:何が正しいかという価値判断や、結果に責任を持つ意思決定は人が担う領域です
- 因果関係の理解:AIは相関(一緒に起きやすい傾向)を捉えるのは得意ですが、「なぜそうなるか」という因果の理解は苦手です
- 個別の機微をくんだ対応:相手の事情や感情を察した、その場限りの柔軟なコミュニケーションは人のほうが向いています
- 事実の正確さ(ハルシネーション):もっともらしい誤った内容を生成することがあり、重要な用途では人による検証が欠かせません
つまり、AIは認識・予測・生成・自動化といった作業の自動化に強く、判断や責任、独創は人が担う、という役割分担が現実的です。この前提を踏まえたうえで、では自社では何を任せられるのかを考えていきます。
自社データを起点にすると「作れるAI」が見えてくる
ここまで、検討が止まる原因は「データとAI手法がつながっていないこと」だと整理しました。次に、その解き方として「自社データを起点に考える」という発想を説明します。
なぜ事例集めではなく自社データから考えるのか
AIで何ができるかを調べるとき、多くの方はまず他社の事例を探します。もちろん事例は発想のヒントになりますが、事例だけを集めても自社で作るものは決まりません。他社の事例はその会社のデータと業務の上で成立しているので、自社にそのデータがなければ再現できないからです。
そこで出発点を変えます。「世の中でAIに何ができるか」ではなく、「自社にあるデータで何ができるか」から考えるのです。各社はそれぞれ異なるデータを持っています。売上やCRMの数字、契約書やマニュアル、設備のログ、通話の録音など、自社固有のデータを起点にすると、作れるAIの候補が一気に絞り込めます。持っていないデータの活用は考えなくてよくなるので、検討がぐっと整理されます。
業界別にどんなAI活用があるかを俯瞰したい場合は、業界別のAI活用事例の記事も参考になります。
企業データの9割は「非構造化データ」
自社データを起点にするうえで、まず知っておきたいのが企業データの構成です。
データは大きく2種類に分かれます。1つは構造化データで、売上DBやCRM、在庫管理など、行と列で整理された数値・表形式のデータです。もう1つは非構造化データで、契約書・マニュアル・議事録などの文章、通話の音声、製品の画像、現場の動画などを指します。

ストレージ事業者のBoxの調査などでは、企業が持つデータのうち、きれいに整った構造化データは全体の約10%にすぎず、残り約90%は非構造化データだとされています。多くの企業が「データはあるのにAIに使えていない」と感じるのは、活用できていないデータの大半がこの非構造化データだからです。逆に言えば、文章・音声・画像をどう扱うかを押さえれば、これまで眠っていた9割のデータが活用の対象になります。
データ種別×AI手法の早見表|自社で作れるAIの見つけ方
自社データを起点にするといっても、データを眺めているだけでは作れるAIは見えてきません。そこで役立つのが、データの種別とAIの手法を掛け合わせる「早見表」です。本記事の中心になる考え方なので、丁寧に見ていきます。
早見表の読み方
まず、自社のデータを次の3種類に分けます。
- 数値(構造化データ):売上、在庫、センサーの計測値など、表形式で集計できるもの
- テキスト(文書):契約書、マニュアル、議事録、問い合わせ履歴など、文章で書かれたもの
- マルチメディア:画像、音声、動画など
次に、AIの代表的な手法を3つに分けます。
- 予測・最適化:過去のデータから将来を予測したり、最適な組み合わせを計算したりする
- 検索・生成:大量の文書から必要な情報を探し出し、答えを生成する
- 分類・認識:データを種類ごとに仕分けたり、対象が何かを見分けたりする
この「データ種別×AI手法」を一枚の表として掛け合わせると、各マスに「自社で作れるAIの候補」が浮かび上がります。
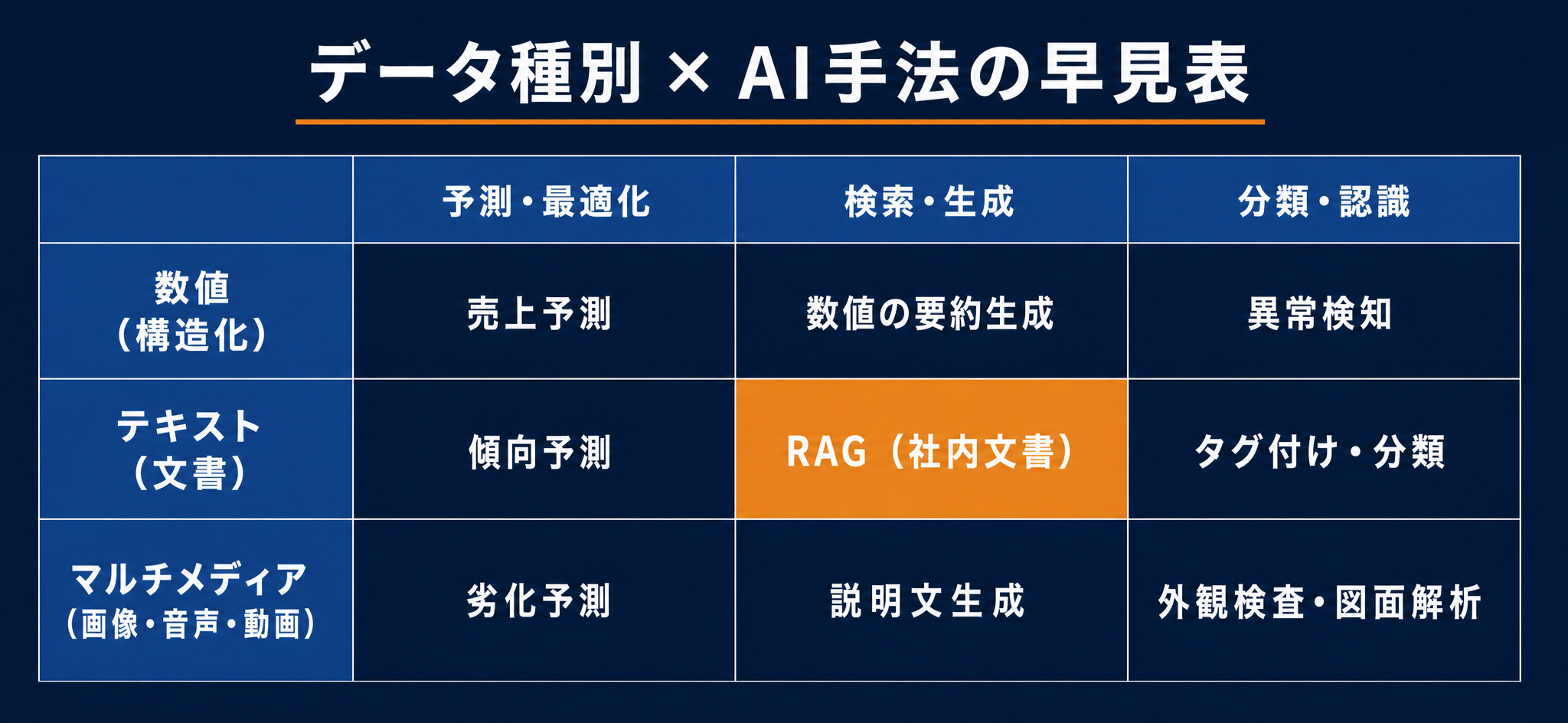
各マスに当てはまる代表的なユースケース
早見表の各マスには、次のような業務がおおむね当てはまります。
| データ種別 | 予測・最適化 | 検索・生成 | 分類・認識 |
|---|---|---|---|
| 数値(構造化) | 売上予測、解約予測、需要予測 | 数値をもとにした要約・コメント生成 | 顧客セグメント、異常検知、不正検知 |
| テキスト(文書) | テキスト指標の傾向予測 | RAG(社内文書の知識ベース化) | 項目抽出、タグ付け、ポジネガ分類 |
| マルチメディア | 画像系の劣化予測など | 画像・音声からの説明文生成 | 外観検査、図面解析、文字起こし |
この表から読み取れるのは、「同じデータでも、掛け合わせる手法を変えると別のAIになる」ということです。例えば売上の数値は、予測・最適化なら需要予測に、分類・認識なら異常検知や不正検知に使えます。手元のデータを縦軸に置き、横軸の手法を一つずつ当てていけば、「自社で作れそうなAI」の候補が複数見えてきます。
特に取り組みやすいのが、テキスト×検索・生成のマスにあたるRAGです。RAGとは、社内のマニュアルや規定、議事録、問い合わせ履歴などをAIが検索できる知識ベースにして、自然な言葉で質問すると根拠つきで答えてくれる仕組みを指します。多くの企業が持て余している非構造化データを、比較的早く活用しやすい手法です。
つまり、「うちは何ができるか」と漠然と考えるのではなく、自社データを早見表の縦軸に並べ、横軸の手法を順に当てる。これだけで検討の解像度が上がります。
業務データはそのままでは使えない|AIレディ化という前処理
早見表で候補が見えても、すぐにAIが作れるわけではありません。手元のデータは、たいていそのままではAIに渡せない状態にあります。ここでは、その間を埋める「AIレディ化」という前処理について説明します。
Excel地獄も整備すれば資産になる
多くの現場のデータは、セル結合だらけのExcelだったり、似た情報が複数のファイルに分散していたりします。人が見る分には成立していても、AIに処理させようとすると、読み取りのコストが高く、量が多いと最後まで扱いきれません。
そこで、データをAIが扱える形に整える前処理を行います。これを「AIレディ化」と呼びます。セル結合をほどいて表を正規化する、表記ゆれをそろえる、複数ファイルを1つの形式にまとめる、といった地道な整備です。一見「Excel地獄」に見えるデータも、整備すれば価値のあるデータ資産に変わります。整っていない原石を磨くイメージに近いといえます。
自社のデータが活用に使える状態にあるかをどう確認するかは、データ棚卸しの進め方の記事も参考になります。
着手のしやすさには順番がある
AIで作れるものには、着手のしやすさに差があります。低リスクで早く始められるものから、設計が重く難易度の高いものまで、いわば階段状になっています。
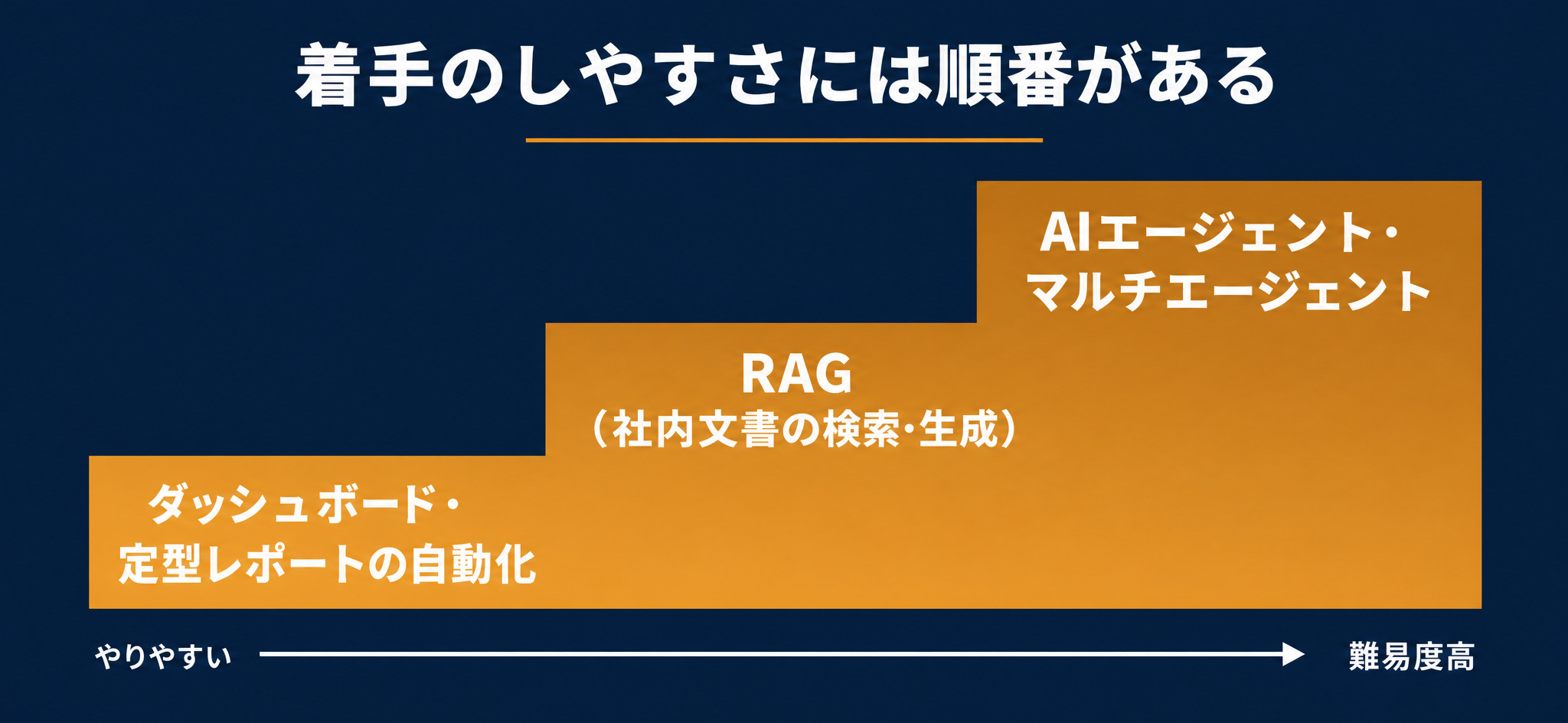
比較的やりやすいのは、ダッシュボードや定型レポートの自動化、そしてRAGによる社内文書の検索・生成です。データの形が決まっていて、効果も見えやすいため、最初の一歩に向いています。一方、複数のAIが役割分担して自走するAIエージェントやマルチエージェントの設計は、難易度が高く、相応の準備が要ります。
定型レポートの自動化を具体的にどう進めるかは、レポート作成をAIで自動化する方法の記事で詳しく解説しています。
まずは階段の下段、つまりレポート自動化やRAGから着手し、運用の手応えを確かめてから上段へ進むのが現実的です。いきなりエージェントから始めると、データ整備も運用設計も追いつかず、頓挫しやすくなります。
このように、データを整え、着手しやすいところから始めるという前提が整って初めて、早見表で見つけた候補が実際に動き出します。自社のデータがどの段階にあるか整理したい方は、構想段階からご相談いただけます。
⇨リベルクラフトへの無料相談はこちら
部門別に見る、業務データから作れるAI
ここまでは考え方を中心に説明してきました。次に、早見表を実際の部門に当てはめると、どんなAIが作れるのかを具体的に見ていきます。いずれも特定の企業の事例ではなく、業務でよく見られる一般的な例として整理します。
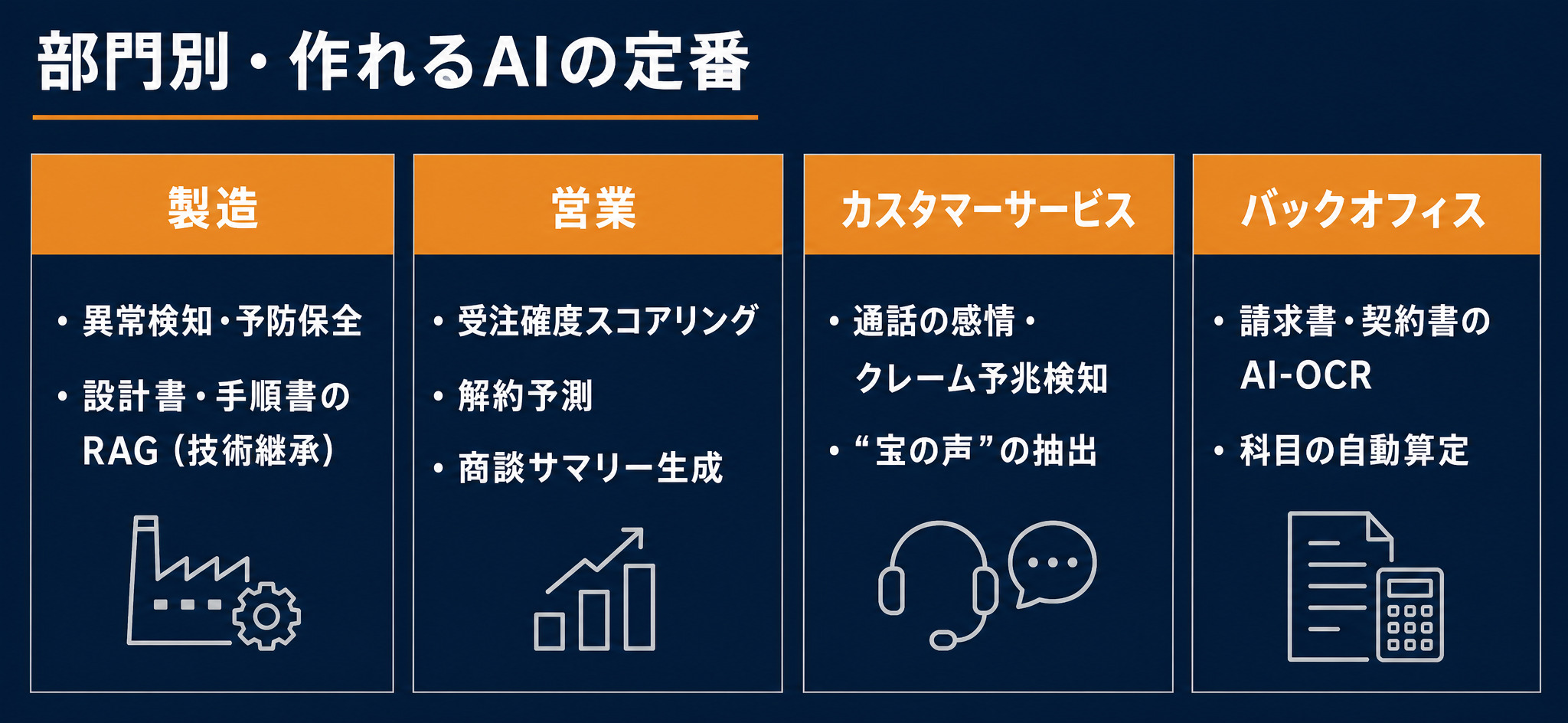
製造部門
製造部門は、数値とマルチメディアの両方のデータが豊富です。
- 品質・設備系:センサーデータの異常検知で不良の検出率を上げる、設備データの予防保全で停止時間を減らす、製品画像の外観検査で目視検査を補う
- 技術継承系:設計書・作業手順書・トラブル事例をRAGで知識ベース化し、若手が自然な言葉で過去の知見を引き出せるようにする
技術継承のRAGは、最小のステップで始められるのが利点です。関連するPDFをフォルダに整理し、RAGに取り込み、自然言語で対話する、という流れから着手できます。ベテランの暗黙知を再現性のある形に移し替える第一歩になります。
営業部門
営業部門は、CRMの数値と、メールや議事録のテキストが蓄積されています。
- 数値×予測:CRMの商談データから受注確度をスコアリングする、サブスクリプション事業なら解約リスクを予測してチャーンを早期に検出する
- テキスト×生成:蓄積したメールや議事録から、商談サマリーや次のアクション案を自動生成する
数字と文章の両方を活用できるのが営業データの特徴です。受注確度の予測で優先順位をつけ、サマリー生成で記録の手間を減らす、というように組み合わせると効果が出やすくなります。
カスタマーサポート部門
カスタマーサポートには、通話の音声やチャットのテキストという、マルチメディアとテキストのデータが集まります。
- リスク検知:通話記録の音声やテキストから感情の変化やクレームの予兆を捉え、優先度の高い取り漏れを抽出する
- 強みの発見:ポジティブな顧客の声、いわば「宝の声」を抽出し、商品改善や自社の強みの言語化、現場のモチベーションに活かす
クレーム対策だけでなく、良い反応を拾い上げる使い方ができるのもこの領域の特徴です。守りと攻めの両面でデータを活かせます。
バックオフィス部門
バックオフィスは、請求書・契約書・レシートといった、定型の文書・画像が多い領域です。
- 入力作業の削減:請求書・契約書・レシートをAI-OCRや情報抽出で読み取り、転記の手間を減らす
- リスク・自動判定:契約書のリスク事項を検出する、勘定科目を自動で算定する
定型書類が多いため、AIの効果が比較的見えやすい領域です。リベルクラフトでも自社のバックオフィスはAIを軸に回しており、小規模な組織でも効果が出ています。社内のさまざまなデータをAIで活用する事例は、業界別のAI活用事例の記事でも整理しています。
候補を絞り込み、優先順位をつけて進める
部門別の例で「作れるAI」のイメージがついたら、最後に、複数の候補から何に着手するかを決める手順を整理します。候補が複数あるのは普通のことなので、絞り込みの基準を持っておくと判断が速くなります。
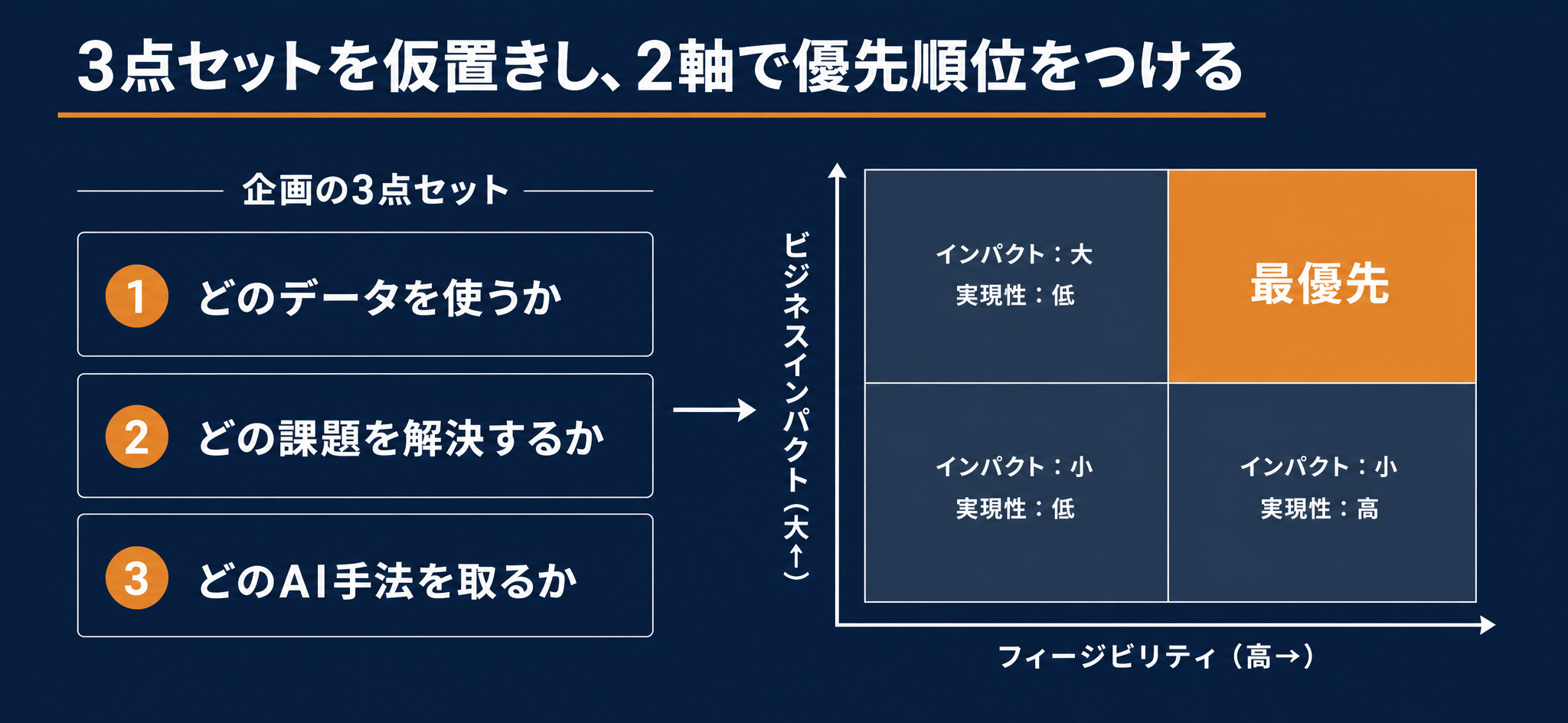
企画の3点セットを仮置きする
候補を1つ選んだら、次の3つをセットで仮に定義します。
- どのデータを使うか:手元のどのデータを入力にするか
- どの課題を解決するか:そのデータで何を良くしたいか
- どのAI手法を取るか:予測・最適化、検索・生成、分類・認識のどれを使うか
この3点セットがそろうと、「では誰が作るか」「どのベンダーに相談するか」という次の会話に進めます。逆に、ここが曖昧なまま見積もりを取ろうとすると、話がかみ合わずに止まります。仕様の前段にあたるこの整理が、要件定義のたたき台にもなります。要件定義の進め方そのものは、別の記事で詳しく扱います。
インパクト×フィージビリティで順番を決める
3点セットの候補が複数できたら、2つの軸で並べて優先順位を決めます。
- ビジネスインパクト:売上や利益にどれだけ直結するか
- フィージビリティ(実現性):システム連携の重さ、業務の中でテストしやすいか、データの量・質・鮮度は足りるか
インパクトが大きく、かつ実現性も高いものが最優先の候補です。一般には、データが整っていて業務内で小さく試せるものから着手すると、早く手応えを確かめられます。すべてを同時に進めようとせず、1つに絞ってPoC(概念実証)で検証してから広げるのが定石です。PoCの進め方の詳細は別記事で扱いますが、まずは「最初に試す1つ」を選ぶことが出発点になります。
内製とベンダー、どちらで進めるか
着手する候補が決まったら、内製で進めるか専門家と組むかを判断します。目安は次のとおりです。
- 内製で小さく試す:ChatGPTやCopilotのAPIなど、汎用ツールで試せる範囲なら、自社で小さくPoCを回すほうがコストもスピードも有利です
- 専門家と連携する:自社固有の業務プロセスやデータが深く絡み、テーラーメイドのカスタマイズが必要なら、専門家と組むほうが確実です
- どちらとも言えない:判断がつかない場合は、課題とデータの切り分けが足りていないことが多いので、もう一度3点セットに立ち返って整理します
ここで効いてくるのが、技術力そのものよりも企画力です。使えるデータを定義し、解くべき課題を決め、それを仕様に翻訳する。このAIとプロジェクトマネジメントをつなぐ企画力が、成果を大きく左右します。「データがどこにあるか分からない」状態のままでは前に進めないので、まずはデータの所在を押さえることから始めると良いでしょう。
まとめ
AIで何ができるかは、世の中の事例ではなく自社のデータから逆算すると見えてきます。本記事の要点を整理します。
- AIの機能は「認識・理解」「予測・分析」「生成」「自動化・制御」の4カテゴリに大別できる
- 一方でAIは独創・倫理的判断・因果の理解・個別の機微・事実の正確さ(ハルシネーション)が苦手で、判断や責任は人が担う
- 成果が出る企業との差は技術や予算ではなく「何を作るか」という目的の有無にある
- 検討が止まる3つの壁の共通原因は、自社データとAI手法が結びついていないこと
- 企業データの約9割は文章・音声・画像などの非構造化データで、ここを扱えると活用の幅が広がる
- データ種別(数値・テキスト・マルチメディア)×AI手法(予測最適化・検索生成・分類認識)の早見表で、作れるAIの候補を具体化できる
- 業務データはAIレディ化の前処理が要り、着手はレポートやRAGなどやりやすい段から始める
- 3点セット(データ×課題×手法)を仮置きし、インパクト×フィージビリティで優先順位をつける
AIで何ができるかという問いは、「自社のどのデータで、どの課題を、どの手法で解くか」に置き換えると前に進みます。まずは自社にあるデータを早見表の縦軸に書き出し、横軸の手法を一つずつ当ててみることをおすすめします。
ウェビナー資料(ホワイトペーパー)のダウンロード
本記事のテーマ「業務データ×AIで何が作れるか」は、ウェビナー「業務データ×AIで何が作れるか」でも、データ種別×AI手法の早見表や部門別の作れるAIの例を、図解とともに詳しく解説しています。早見表と優先順位づけの考え方をまとめたスライド資料を、無料でダウンロードいただけます。
⇨ウェビナー資料のダウンロードはこちら
自社データの活用・AI企画の相談は「リベルクラフト」
ここまで読んで、「考え方は分かったが、自社のどのデータからどのAIを作ればよいか、自分たちだけで決めきれない」と感じた方も多いのではないでしょうか。
リベルクラフトでは、戦略・構想の立案から、AIシステムのものづくり、社内人材を育てる教育・スクールまでの3軸で、企業のAI・データ活用の内製化を支援しています。AIで何ができるかという入口の整理から、使えるデータの定義・課題の切り分け・手法の選定、PoCや本開発までを一貫してサポートします。
次のようなニーズをお持ちの方に適しています。
- 自社のデータを棚卸しして、作れるAIの候補を洗い出したい
- データ種別×AI手法の早見表を自社に当てはめて整理したい
- 複数の候補から、どれを最初のPoCにすべきか優先順位をつけたい
構想段階のご相談でも問題ありません。自社のどのデータから、どんなAIを作れるか。まずはお気軽にご相談ください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



