ローカルLLMの構築ガイド|クラウドに出せないデータをAIで使う判断軸と5ステップ

「うちのデータはクラウドに出せないから、生成AIは使えない」という方も多いでしょう。製造業の図面や技術情報、官公庁の機密、金融や医療の顧客データを扱う現場では、よく聞く言葉です。
しかし「クラウドに出せない」ことと「AIを使えない」ことは、同じではありません。出せないデータには、オンプレミスや閉域環境で動かすローカルLLMという選択肢があります。
そこで本記事では、 ・クラウドに出せない理由の分解とローカルLLMという選択肢 ・オンプレミス・閉域クラウドなど方式ごとの違いとコストの現実 ・いつローカルにすべきかを決める5つの判断軸と、失敗しない構築の5ステップ についてわかりやすく解説します。機密データを扱いながらAI活用を進めたいDX推進担当の方は、ぜひ最後までご覧ください。
「自社の機密データをAIでどう扱えばよいか整理したい」という方はリベルクラフトへご相談ください。 ⇨リベルクラフトへの無料相談はこちら
ローカルLLMとは・なぜ「クラウドに出せない」でAIを諦めなくてよいのか
まず、ローカルLLMとは何か、そして「クラウドに出せないからAIは無理」という思い込みがなぜ誤解を含むのかを整理します。ここを分解できると、自社が本当に守るべきデータはどれかが見えてきます。
ローカルLLMとは(オンプレミス・閉域で動かす生成AI)
ローカルLLMとは、クラウドの大規模AIにデータを送るのではなく、自社の管理下にある環境で動かす生成AI(大規模言語モデル)を指します。 オンプレミスのサーバーや、外部と切り離した閉域環境にモデルを置き、データを外に出さないままAIを利用する考え方です。「オンプレミスAI」「オンプレミス生成AI」と呼ばれることもあります。
ChatGPTやGeminiのようなクラウドAIは、入力したデータを提供者のサーバーへ送って処理します。一方でローカルLLMは、データを社内に留めたまま処理する点が根本的に違います。「クラウドか、AIを諦めるか」の二択ではなく、「出せるデータはクラウド、出せないデータはローカル」という第三の道があると考えると分かりやすいでしょう。
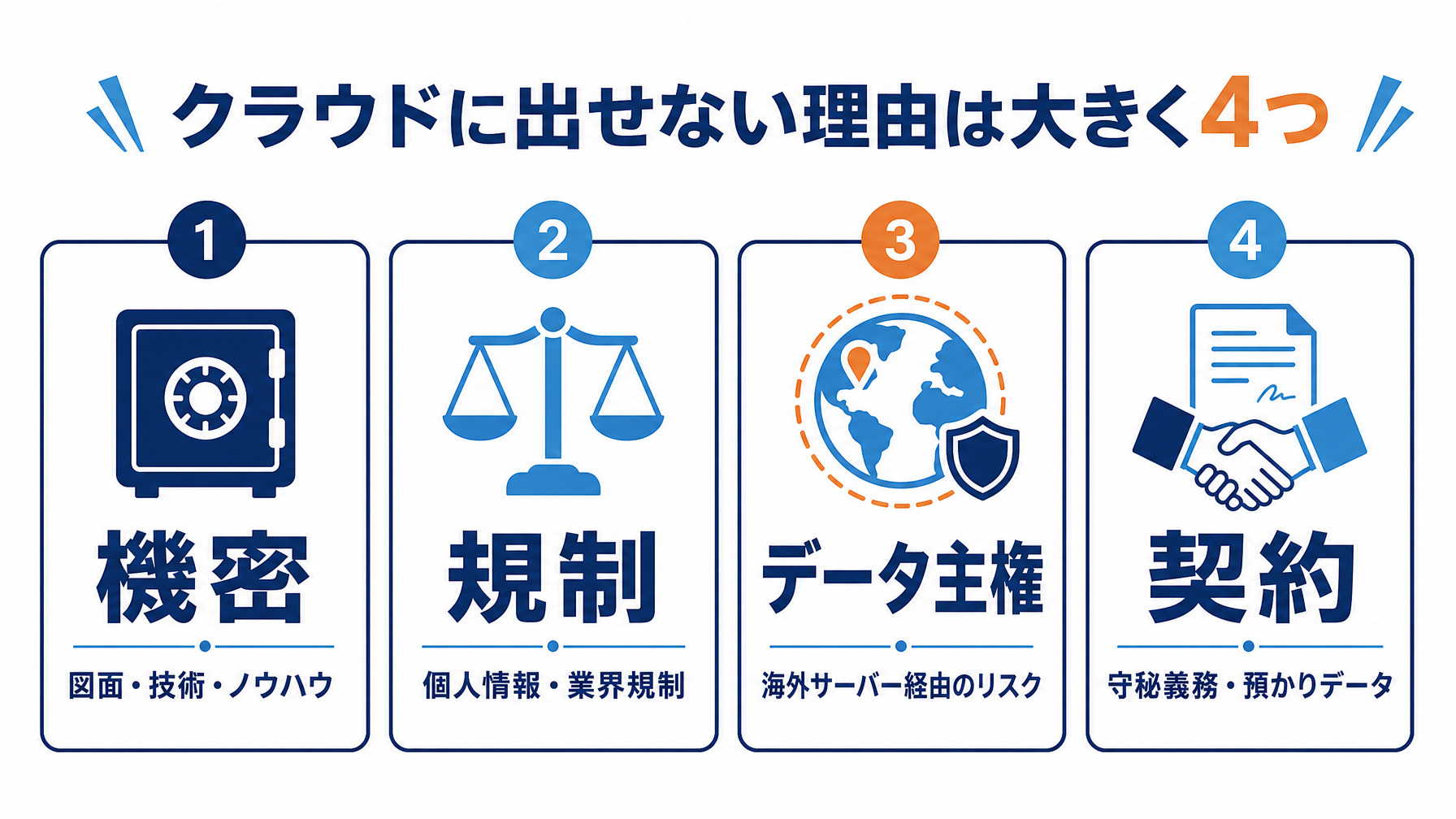
クラウドに出せない理由は大きく4つ(機密・規制・データ主権・契約)
「クラウドに出せない」と一言で言っても、その理由はひとつではありません。大きく次の4つに分けられます。
- 機密:製造業の図面・設計データ・製造ノウハウ、研究開発データなど、漏れたときに競争力を失うもの
- 規制:個人情報保護法や、金融・医療などの業界規制、外為法の輸出管理に関わるデータ
- データ主権:海外のサーバーを経由すると外国の法律の影響を受けうるという論点
- 契約:顧客との守秘契約や、取引先から預かったデータの取り扱い制限
理由をひとくくりにせず区別すると、「全部出せない」のではなく「この種類のデータが出せない」と特定できます。実際には、社外公開済みの資料や一般的な業務文書のように、クラウドに出しても問題ないデータのほうが多いことが少なくありません。本当に外に出せないのは、全データのうち一部であることが多いのです。
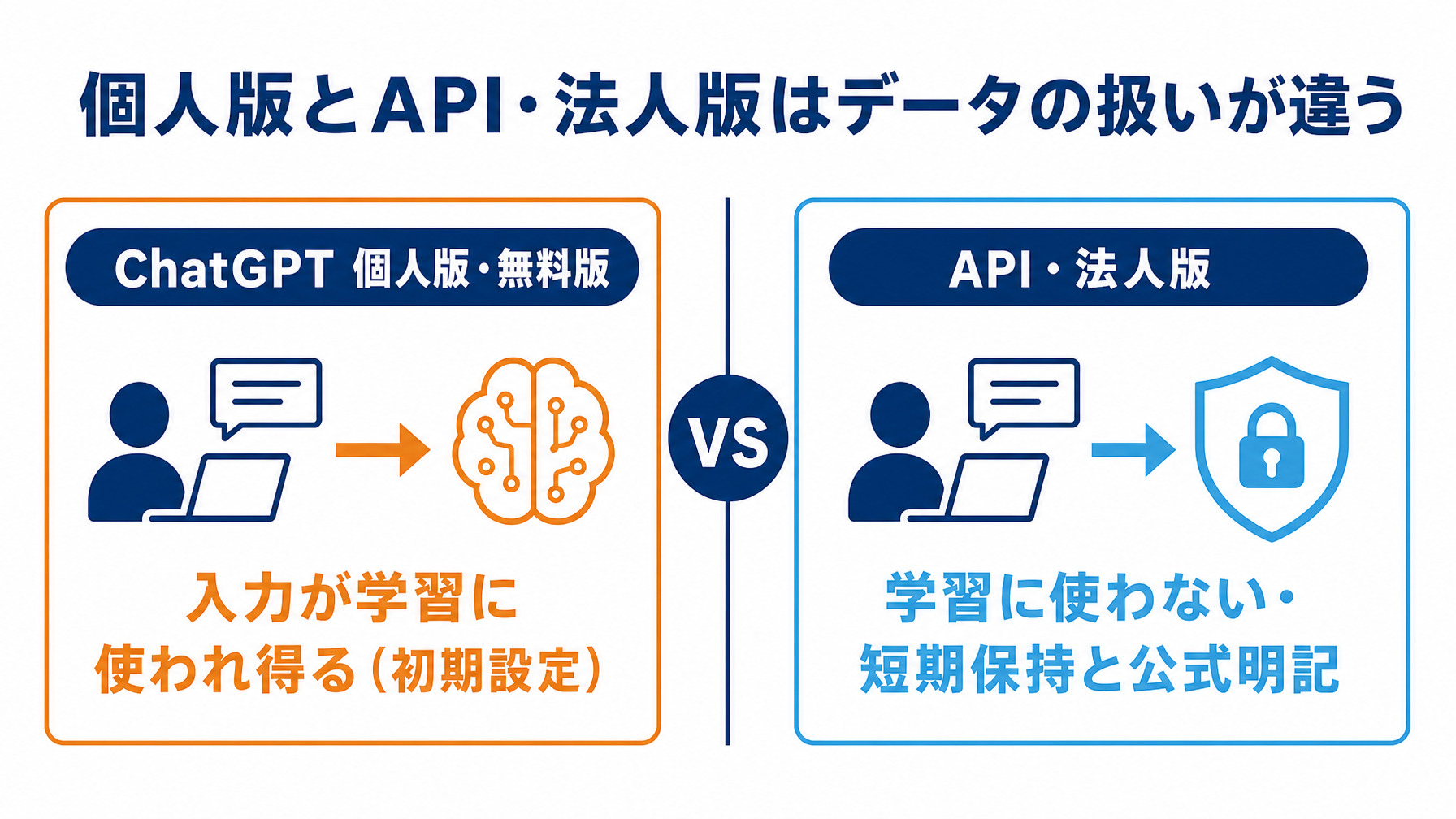
「入力は全部学習される」は誤解(個人版とAPI・法人版の違い)
出せない理由を考える前に、もうひとつ広く流通した誤解を解いておきます。「生成AIに入れたデータは全部学習に使われて漏れる」というものです。これは、使うサービスとプランによって扱いが大きく変わります。
ChatGPTの無料・個人版は、初期設定のままだと入力がモデルの改善に使われ得ます(オプトアウト設定が必要です)。一方で、OpenAIのAPIでは送信データはデフォルトでモデル学習に使われず、不正利用の監視のため最大30日保持されると公式に示されています(参考:OpenAIのデータ利用ポリシー解説)。MicrosoftのAzure OpenAI Serviceも、顧客データをモデルの再トレーニングに使わないと公式に明記しています。
つまり「どのサービスのどのプランか」でリスクは大きく変わります。企業のAI活用では、こうしたデータの扱いを明記した法人契約・API利用がほぼ前提になっています。ひとくくりに怖がる必要はありません。
「学習に使わない」と「外に出ない」は別の話
ただし、ここで話を終わらせると線引きを見誤ります。API版なら学習に使われなくても、データは依然として社外(多くは海外)のサーバーを経由して処理されます。 「学習に使うかどうか」と「データが外に出るかどうか」は別の問題です。
データ主権の観点では、海外のクラウドサービスは米国のCLOUD Actなどの下で運用され、外国政府が提供者にデータ開示を求められる可能性が残ります(参考:データ主権の解説)。守秘契約や規制でも「社外に出すこと自体」が問題になる場合があります。
だからこそ、学習利用の有無だけで判断せず、「本当に外に出せないデータ」が残ることを認めます。そのデータにこそ、社内・閉域で動かすローカルLLMという選択肢が効いてきます。
ローカルLLMの3つの方式(フルオンプレ・閉域クラウド・ハイブリッド)
ここまでで「出せないデータにはローカルLLMという解がある」ことを確認しました。次に、ローカルLLMが具体的にどんな形を取るのかを見ていきます。「ローカル=全部自社に設置」という極端なイメージを持たれがちですが、実際には守り方に段階があります。大きく3つの方式に分かれます。
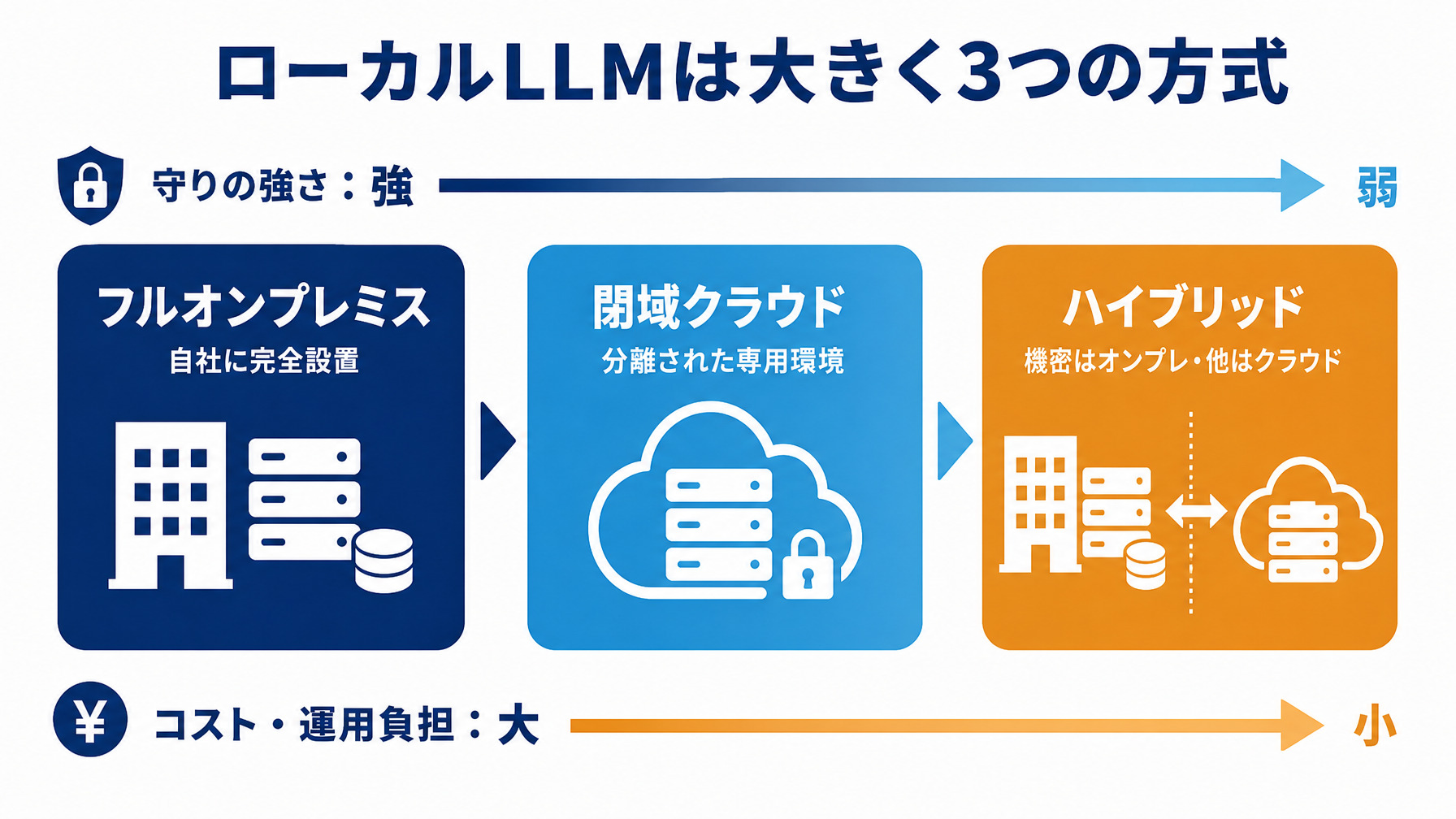
フルオンプレミス(データが一切外に出ない最も堅い方式)
フルオンプレミスは、自社のサーバーやデータセンターにAIを完全に設置し、データが社外へ一切出ない最も堅い方式です。 製造業の技術情報、官公庁の機密、外為法で輸出管理が関わる技術データなど、絶対に外に出せないデータに向いています。
その代わり、GPUサーバーの購入から電力・冷却・保守・運用人材まですべて自前になるため、初期投資も運用負担も最大になります。「絶対に外に出せないデータが本当にあるか」が、この方式を選ぶかどうかの分かれ目です。
閉域クラウド(拡張性を活かした現実的な中間解)
閉域クラウドは、クラウド上に専用・分離された環境を作り、そこでAIを動かす方式です。物理的な設備は他社のものですが、論理的に隔離された環境でデータを守ります。クラウドの拡張性を活かせるため、フルオンプレより初期投資を抑えやすいのが特徴です。
たとえばAmazon Bedrockを国内リージョン(東京・大阪)で使う構成も、この考え方に近い選択肢です。ただし物理設備は他社のものなので、海外法の影響が残らないかは契約条項まで確認する必要があります。
ハイブリッド(機密データだけオンプレ、それ以外はクラウド)
ハイブリッドは、機密データだけをオンプレミスで扱い、それ以外はクラウドを使う方式です。前述の「出せないデータは一部」という考え方を、そのまま構成に落とした形と言えます。データを機密度で分類できていることが前提になります。
多くの企業にとっての現実解は、「全部オンプレ」でも「全部クラウド」でもなく、この閉域クラウドやハイブリッドという中間にあります。守りの強さと運用負担のバランスを見て選ぶことになります。
ローカルLLMで動かせるモデルとコストの現実
方式が分かったところで、次に気になるのは「何を動かせて、いくらかかるのか」という現実です。ローカルLLMは、モデルの選択肢が広がったことと、ハードのコストに大きな幅があることの両方を押さえておく必要があります。
何を動かすか(オープンモデル・国産LLM・日本語強化モデル)
ローカルLLMで動かせるモデルは、確実に増えています。海外のオープンモデル(Google Gemma、Alibaba Qwen、OpenAI gpt-ossなど)に加え、日本語を強化したモデルや国産LLMが登場しています。
特に国産LLMは、機密データを扱う組織にとって現実味のある選択肢です。デジタル庁は「ガバメントAI」で試用する国内LLMを公募し、2025年8月にtsuzumi 2・ELYZA・Sarashina2 mini・PLaMo・Takaneなど7件を採択しました(参考:デジタル庁の発表)。NTTのtsuzumiは、顧客のオンプレミス環境での利用を公式にサポートしています。機密性を重視する官公庁ですら、国産LLMの実証に動いているのです。
ただしモデルごとに、商用利用やオンプレミス利用の可否といったライセンスが異なります。選定時にライセンス確認が前提になる点は注意してください。
用途に応じた規模(社内文書検索・RAGなら12B〜24Bで足りることも)
「クラウドの最大級モデルほどの賢さがないと使えないのでは」と心配される方もいるでしょう。しかし、必要なモデルの規模は用途によって変わります。
高度な推論や幅広い知識を要する用途はクラウドの大規模モデルが有利です。一方、社内文書検索やFAQ応答のように用途が絞られていれば、ローカルで動く中規模モデルでも十分なことが多くあります。たとえば社内文書を検索して回答を生成するRAG(検索した情報をもとにAIが回答する仕組み)なら、12Bから24B程度のモデルで対応できるケースが少なくありません。「最高の賢さが要るのか、決まった業務をこなせれば十分なのか」で、必要なモデル規模が決まります。
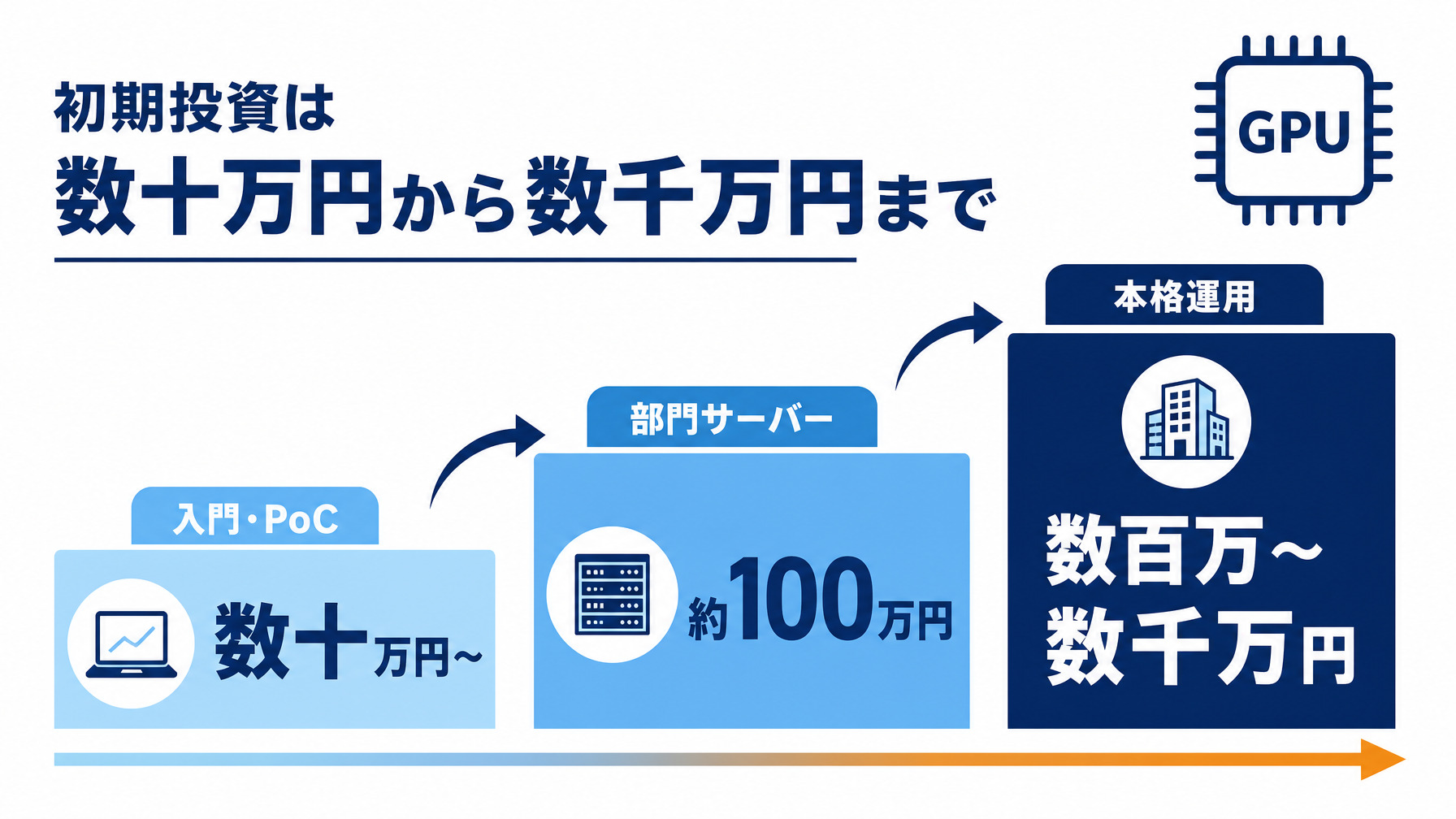
GPUと初期投資の現実(数十万円から数千万円まで)
ローカルLLMの土台になるのがGPUです。よく「GPUは数千万円する」と言われますが、価格帯には大きな幅があります。
入口は消費者向けGPUで、24GBクラスのGPUを積んだPC構成なら数十万円から始められます。これで量子化した中規模モデルが動きます。一方、本格的な大規模推論にはデータセンター向けのGPUが必要で、たとえばNVIDIA H100(80GB)は1枚あたり約519万円が国内の参考価格です(参考:GDEPソリューションズ)。これを複数枚積んだサーバーになると数千万円規模になります。
つまり「自社で動かす」のスペックと費用は、数十万円から数千万円まで幅があります。導入支援サービスの参考価格として、オンプレミスで最短1カ月の構築を500万円からとする例(インテック)もあります。まずは小さな構成から試せる、と考えてよいでしょう。
見落とされがちな運用体制のコスト
ハードを買えば終わり、ではありません。見落とされがちなのが運用体制のコストです。ローカルLLMは、モデルの選定・更新、セキュリティパッチの適用、性能監視、障害対応を続けられる人や体制があって初めて回り続けます。
専門人材の採用は簡単ではなく、社内に運用を担える人を持てるか、外部の支援を受けられるかが現実的な分かれ目になります。実務では「機材の調達」よりも「運用の継続」のほうがボトルネックになりやすい、と考えておくと安全です。
いつローカルにすべきか・クラウドで十分か(5つの判断軸)
選択肢とコストが見えたところで、肝心の「自社はどちらを、いつ選ぶべきか」を決めます。「機密が心配だから全部ローカルにする」という発想には落とし穴があります。フルオンプレは最も堅い一方で、対象を広げるほどコストも処理スピードの低下も大きくなるからです。
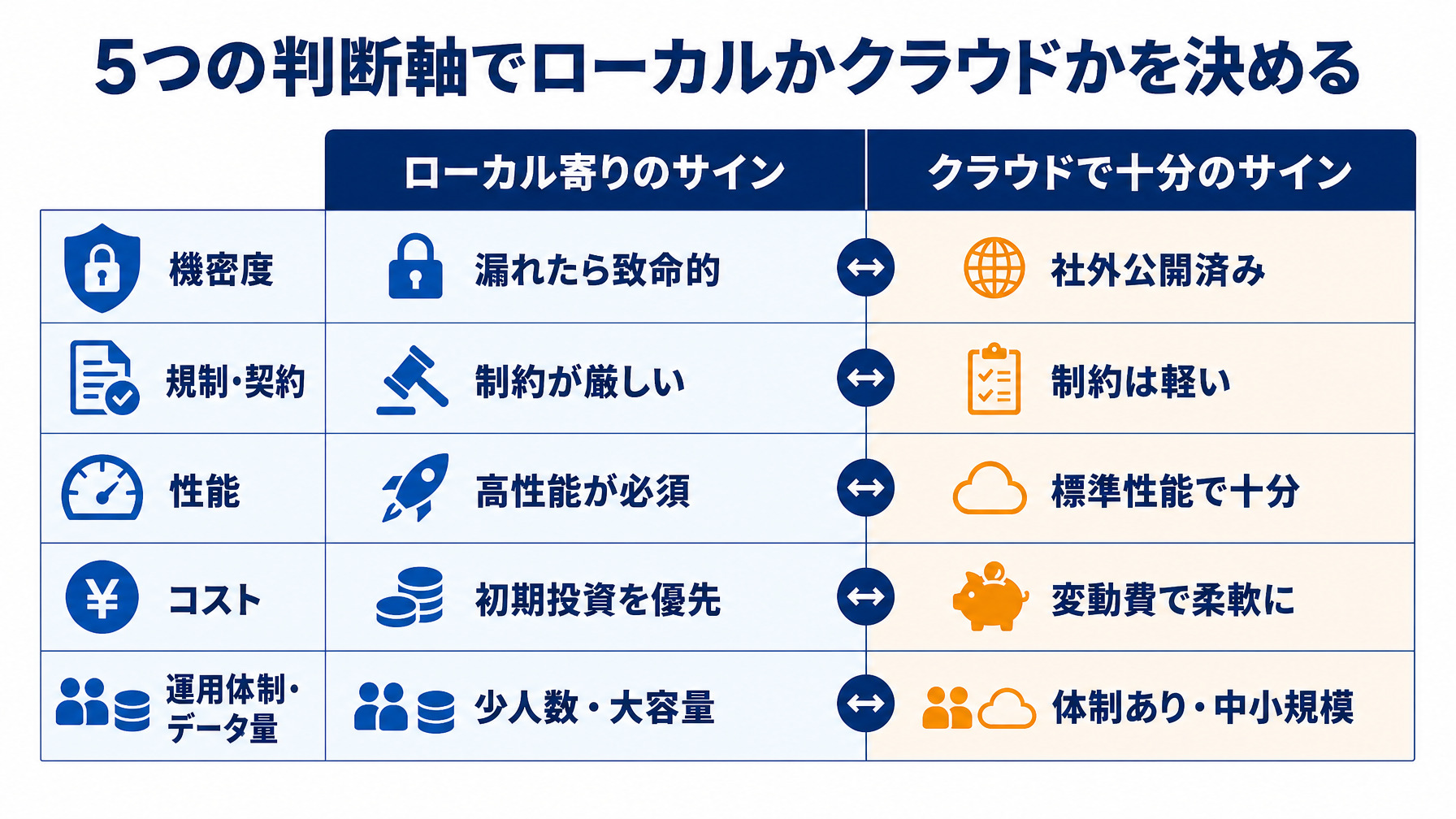
そこで、データや用途ごとに次の5つの判断軸で切り分けます。感覚ではなく根拠を持って決められるようになります。
判断軸① 機密度(外に出たら何が起きるか)
1つ目の軸は機密度です。そのデータが外に出たとき、競争力の喪失・法令違反・契約違反など、どれだけの損害が生じるかを見積もります。図面・技術情報・個人情報・国家機密のように損害が致命的なものはローカル寄り、社外公開済み資料や一般的な業務文書はクラウドで十分です。全データを一律に扱わず、データごとに機密度のレベルを付けることが出発点になります。
判断軸② 規制・契約(そもそも出してよいか)
2つ目の軸は規制・契約です。技術的に守れるかを考える前に、「そもそも社外に出してよいか」の確認が先に来ます。個人情報保護法、金融・医療などの業界規制、外為法の輸出管理、顧客との守秘契約や取引先から預かったデータの制約により、出すこと自体が許されないケースがあります。
金融庁もAIの活用方針を公的に議論しており、約半数の金融機関が汎用の生成AIを活用するなかで、扱うデータごとの線引きが論点になっています(参考:金融庁 AIディスカッションペーパー)。規制・契約のチェックを通らないデータは、ローカル確定と考えてよいでしょう。
判断軸③ 性能(その用途にどこまでの賢さが要るか)
3つ目の軸は性能です。前述のとおり、クラウドの最大級モデルは万能ですが、用途が定型ならローカルの中規模モデルで足りることも多くあります。社内文書検索・FAQ応答・定型文書の処理などはローカルでも対応しやすく、高度な推論や幅広い知識を要する用途はクラウドが有利です。用途の難しさに応じて必要なモデル規模が変わり、それがローカル可否にも効いてきます。
判断軸④ コスト(初期投資か、使った分か)
4つ目の軸はコスト構造の違いです。ローカルは初期投資が先に立ち、その後は運用コストが続きます。クラウドAPIは初期投資が小さく、使った分だけの従量課金です。
利用量が少ない段階や用途が不確実な段階ではクラウドが有利です。一方、大量・継続の利用が見えていれば、ローカルの自前投資が回収できる場合もあります。たとえば文字起こしや大量の文書を継続的に処理するような用途では、クラウドAPIの従量課金が積み上がり、ローカルのほうが総額を抑えられることもあります。「今の利用量と将来の見込み」で有利不利が逆転する、と捉えてください。
判断軸⑤ 運用体制とデータ量(回し続けられるか)
5つ目の軸は運用体制とデータ量です。ローカルLLMは運用を担う人・体制があって初めて回ります。社内に運用力がなく外部支援も薄いなら、無理にローカルを選ばず、クラウドや閉域クラウドのマネージド型に寄せるほうが現実的です。またデータ量が膨大で頻繁に更新されるなら、その処理を自前で支える設計が要ります。「守れるか」だけでなく「回し続けられるか」も判断に含めます。
5つの軸を1枚で(早見表)
5つの判断軸を一覧にすると、データや用途ごとに当てはめて判断しやすくなります。多くの場合、結論は「全部どちらか」ではなく「このデータはローカル、それ以外はクラウド」という切り分けになります。
ここまでローカルLLMの選択肢と判断軸について解説しましたが、「機密データを外に出さずに業務で使えるローカルLLMを構築したいが、どこまで自社でやり、どこを外注すべきか切り分けたい」という方は、リベルクラフトへご相談ください。
リベルクラフトでは、機密データを外に出さず、業務で安全に活用できるローカルLLMの構築が可能です。ただ、構築するだけでなく、RAGを活用して社内にある情報を反映できるため、自社業務に特化したLLMの構築を支援できます。方式(オンプレ・閉域・ハイブリッド)やモデル・ライセンスの選定、コスト見積もりまで一緒に整理します。
以下のリンクからまずは詳細をチェックしてみてください。
⇨リベルクラフトへの無料相談はこちら
失敗しないローカルLLM構築の進め方(スモールスタート5ステップ)
判断軸で「ここはローカルが要る」と決まったとして、ではどう構築を始めればよいのでしょうか。ここでは、いきなり大きく投資して失敗しないための現実的な進め方を整理します。
いきなりフルスペックを買わない(スモールスタートの原則)
最初から複数GPU構成の数千万円サーバーを買うのは、失敗したときの損失が大きすぎます。そこで基本になるのがスモールスタートです。機密度が高く効果も見えやすい一業務に絞り、小規模な構成や導入支援サービスで「自社の機密データで本当に役に立つか」を確かめます。手応えを確認してから、対象とハードの規模を広げます。最初の投資を小さくすることが、後戻りのコストを下げる最大の工夫です。
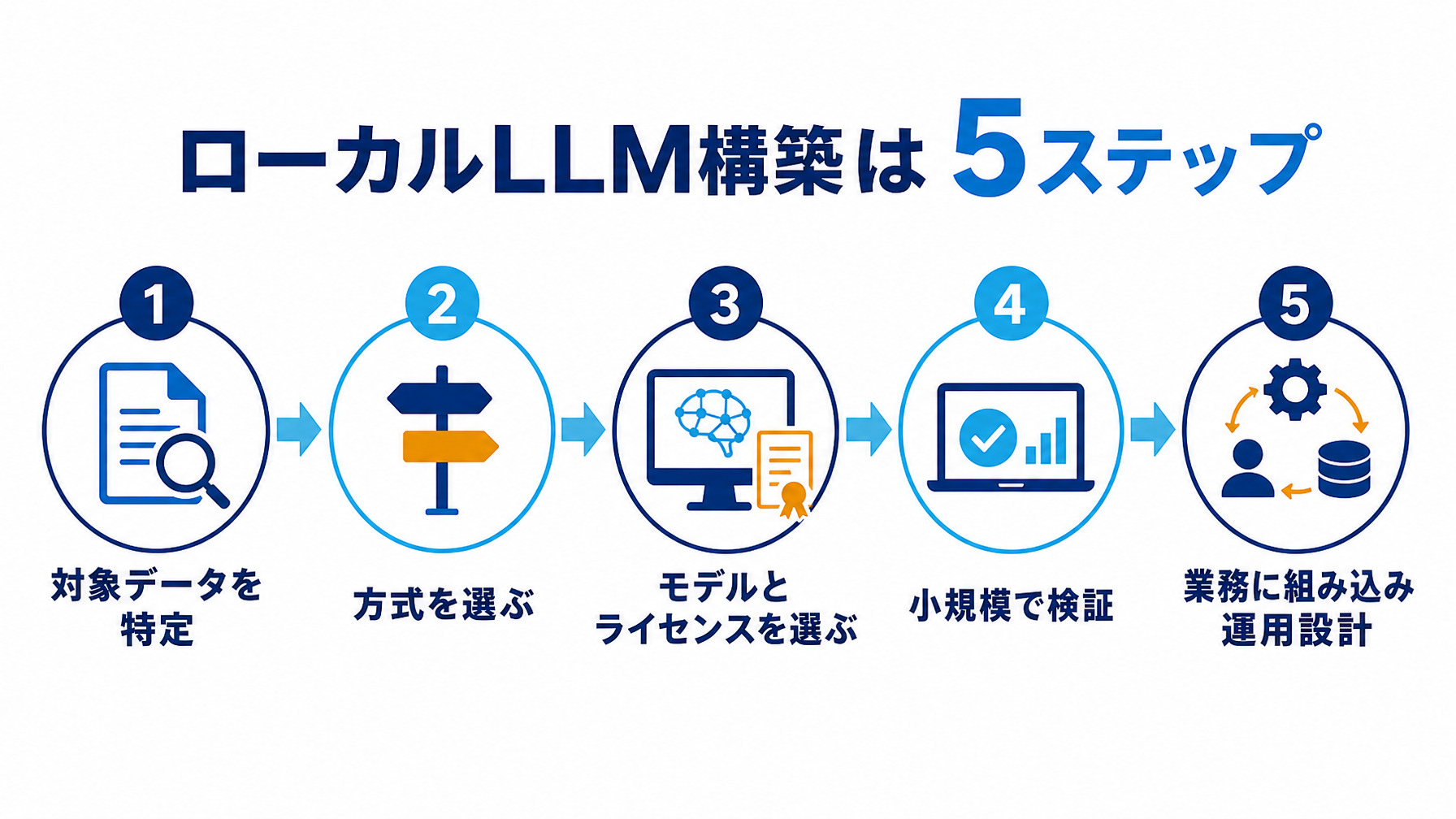
構築の5ステップ(対象特定→方式選定→モデル選定→小規模検証→業務組み込み)
スモールスタートを具体的な手順に落とすと、次の5ステップになります。
- 対象データを特定する:5つの判断軸で「ここはローカル」と決めたデータと用途を、まず1つに絞る
- 方式を選ぶ:フルオンプレ・閉域クラウド・ハイブリッドから、機密度と運用体制に合うものを選ぶ
- モデルとライセンスを選ぶ:国産LLMやオープンモデルから用途に合うものを、商用・オンプレ利用の可否を確認して選定する
- 小規模で検証する:実データで手応えと効果を確かめる(RAGで社内文書に答えられるか、など)
- 業務に組み込み運用設計をする:効果測定と運用体制をセットで整える
各ステップで立ち止まって判断できるので、いきなり大きく投資せずに済みます。
PoC止まりを避ける(ROIが出るのは3割未満)
高額なローカルLLM投資で気をつけたいのが、PoC(試験導入)で止まってしまうことです。Gartnerの調査では、AIプロジェクトでROIを達成できたのは28%にとどまり、52%がROI手前で停滞しているとされます(参考:GartnerのAI ROIに関する分析)。生成AIプロジェクトの半数以上がPoC段階で失敗するとの予測もあります。
ローカルLLMは初期投資が大きいぶん、PoCで止まると損失も大きくなります。「動いた」で満足せず、実際の業務フローに組み込み、効果を測り続ける運用までを設計に含めることが、投資を正当化する条件です。
内製と外注の役割分担
最後に、判断と構築を自社だけで抱えないことをおすすめします。何でも外注するのではなく、内製したほうがよい部分があります。
- 内製が向く部分:どのデータをクラウドに出せないかの棚卸し・分類、取り扱い方針の整理、優先度づけ。自社にしか分からない領域です
- 外部に任せやすい部分:方式の選定、モデルとライセンスの選定、コスト見積もり、初期構築、運用体制の設計
方式やモデルの選定は、一度誤ると大きなコストになる領域です。経験のある相手と一緒に「自社のどのデータをどの方式で扱うか」を整理すると、過剰投資や選び間違いを避けやすくなります。まず社内で線引きの当たりをつけ、その先を伴走者と詰めるのが現実的です。
まとめ
本記事では、クラウドに出せないデータをローカルLLMで扱うための判断と構築の進め方を解説しました。要点は次のとおりです。
- 「クラウドに出せない」は、機密・規制・データ主権・契約の4つに分解できる。本当に出せないのは全データのうち一部であることが多い
- クラウドAPIは個人版と違い学習に使われないと公式に明記されているが、「学習に使わない」と「外に出ない」は別。本当に出せないデータにはローカルLLMという選択肢がある
- ローカルLLMにはフルオンプレ・閉域クラウド・ハイブリッドの3方式があり、多くの企業の現実解は中間にある
- GPUと初期投資は数十万円から数千万円まで幅があり、運用体制のコストも見落とせない
- ローカルかクラウドかは、機密度・規制と契約・性能・コスト・運用体制という5つの軸で切り分ける
- 構築はいきなりフルスペックを買わず、機密度の高い一業務からスモールスタートし、業務に組み込んで効果を測る運用まで設計する
まずは「これは絶対にクラウドに出せない」と思うデータを1つ書き出すところから始めてみてください。完璧なデータ棚卸しは要りません。1つ特定できれば、社内で方式の議論を始められます。
ウェビナー資料(ホワイトペーパー)のダウンロード
本記事のテーマである「クラウドに出せないデータのAI活用」について、ローカルLLMの方式・コスト・判断軸をまとめたウェビナー資料を無料で配布しています。社内で検討を進める際の資料としてご活用ください。
⇨ウェビナー資料のダウンロードはこちら
ローカルLLMの構築・導入は「リベルクラフト」へ
「機密データがあるからAIを諦めていたが、本当はどこまでローカルが必要か切り分けたい」と感じた方も多いのではないでしょうか。
リベルクラフトでは、AI導入の戦略立案から、ローカルLLMの方式・モデル選定、構築、運用体制づくりまでワンストップで伴走支援しています。機密データを外に出さずに社内情報を活用するRAGの構築や、スモールスタートの設計にも対応しています。高いセキュリティが求められる公的機関や、技術情報を扱う製造業などでの支援実績があります。
- 機密データがあり、どこまでローカルが必要か切り分けたい
- オンプレ・閉域クラウド・ハイブリッドのどれが自社に合うか、モデルとライセンスも含めて選定したい
- 初期投資・運用コストの見積もりや、スモールスタートの設計を一緒に詰めたい
こうしたお悩みをお持ちの方は、まずお気軽にご相談ください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。