LLMファインチューニングにおける実装5ステップ。成功の鍵は手法ではなく設計

「LLMをカスタマイズしたいが何から手をつければよいのかわからない」「ファインチューニングとRAGとの違いがイメージできない」と感じている方も多いのではないでしょうか。
ChatGPTのような汎用モデルをそのまま使うだけでは、自社特有の文体やルール、決まった出力フォーマットを思いどおりに再現するのは簡単ではありません。
そこで、ファインチューニングを取り入れることで、既存のLLMに自社のルールや出力形式、口調などを追加学習させ、目的に合った回答へと近づけられます。
本記事では、
- ファインチューニングとは何か、RAGと何が違うのか
- 代表的な5つの手法と、それぞれの向き不向き
- 実装を進める具体的な5ステップ
- 失敗を避けるために押さえておきたい考え方
をわかりやすく整理しました。これからLLMのファインチューニングに取り組みたい方は、ぜひ最後までご覧ください。
「自社の業務に合ったLLMを導入したいが、専門的なノウハウがなく不安」という方は、リベルクラフトへご相談ください。
リベルクラフトでは、ビジネス課題の整理から手法の選定、データ設計・LLMの学習・評価・運用まで一貫してサポートしています。お客様の業務フローに合わせた柔軟なカスタマイズにも対応可能です。
まずは以下のリンクからお気軽にお問い合わせください。
⇨リベルクラフトへの無料相談はこちら
LLMのファインチューニングとは
LLMのファインチューニングとは、すでに大量のデータで学習を済ませた大規模言語モデルに、特定の用途へ合わせた追加学習を行う手法を指します。
一からモデルを作り直すわけではなく、既存モデルを活かしつつ、自社の目的に沿った回答を後から覚えさせるイメージです。
たとえば、
- 毎回決まったフォーマットで回答させたい
- 自社ブランドに合った口調に統一したい
- 特定業務の分類や要約の精度を上げたい
といった調整は、汎用モデルをそのまま使うだけではうまくいかないことも多く、「モデルそのものの出力内容を変えたい」という場面でファインチューニングが役立ちます。
ただし、ファインチューニングはデータの準備やローカル環境で実装する場合、GPUなどの計算資源が必要になることが多いため、事前に必要なものを準備してから進めていきましょう。
RAGとのアプローチの違い
ファインチューニングとよく比較されるのがRAGです。
ファインチューニングは「モデルの振る舞いや出力傾向を調整する」方法、RAGは「外部の情報をその都度参照させる」方法という違いがあります。
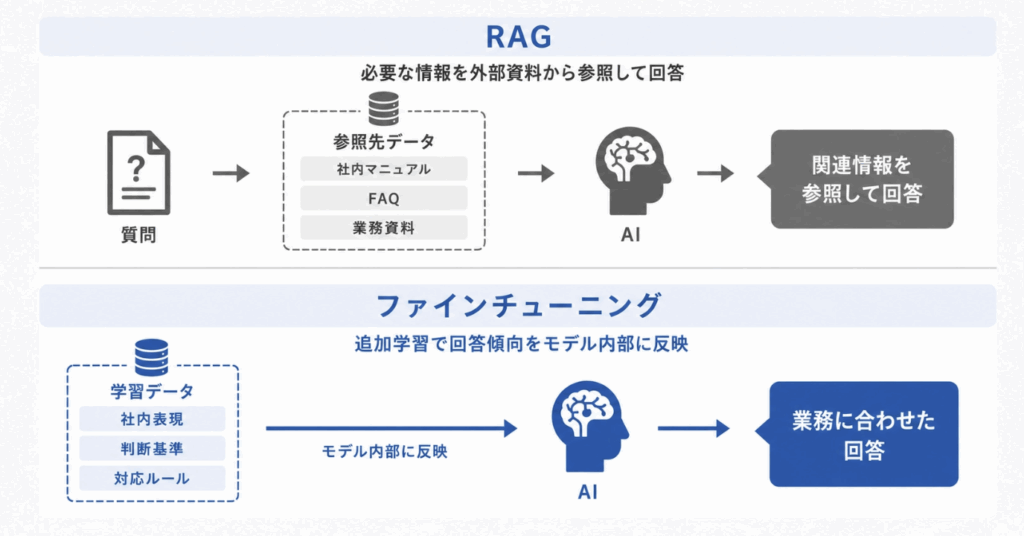
以下に両者の違いを表にしました。
| ファインチューニング | RAG | |
|---|---|---|
| アプローチ | モデルを追加学習し、振る舞いそのものを変える | 外部データを検索し、参照しながら回答する |
| 得意なこと | 出力形式・口調・タスク特化の調整 | 最新情報や社内文書など知識の参照 |
| 情報の更新 | 内容が変わるたびに再学習が必要 | データベースを更新するだけ |
| 向いている場面 | 「どう答えるか」を変えたいとき | 「何を答えるか」を増やしたいとき |
たとえば、最新情報や社内マニュアルを参照させたいだけなら、モデルを再学習させる必要はなく、多くの場合はRAGを使えば十分です。
一方で、出力フォーマットや口調など、回答のスタイルを安定させたい場合は、ファインチューニングが向いており、目的に応じて使い分けたり、組み合わせたりすることが必要です。
ファインチューニングとRAGの違いや使い分けの判断軸をもう少し詳しく知りたい方は、以下の記事もあわせてご覧ください。
参照記事:RAGとファインチューニングの違いを7つの視点で比較。使い分けの判断基準も解説
LLMファインチューニングの5つの手法
ファインチューニングと一口に言っても、何を重視するかによって選ぶべき手法は変わってきます。
代表的な手法は次の5つで、それぞれの特徴を一覧で整理しました。
| 手法 | 概要 | 難易度 | コスト |
|---|---|---|---|
| SFT | お手本となる入力と出力のペアを学習させる、最も基本的な手法 | 中 | 中 |
| DPO | よい回答とよくない回答を学ばせ、好ましい方向へ出力を寄せる | 高 | 中 |
| フルファインチューニング | モデルのすべての重みを更新する本格的な手法 | 高 | 高 |
| LoRA | 元のモデルは凍結し、小さな追加部品だけを学習する軽量な手法 | 中 | 低 |
| QLoRA | モデルを4bitに圧縮したうえでLoRAを適用する、さらに軽量な手法 | 中 | 低 |
SFT(教師ありファインチューニング)
SFT(Supervised Fine-Tuning)は、「入力」と「理想的な出力」のペアをモデルに学習させる、最も基本的で標準的な手法です。
「こう聞かれたら、こう答えてほしい」というお手本を大量に見せ、その振る舞いをモデルに覚えさせるというものです。
たとえば「商品の返品方法を教えてください」と聞かれたら「返品は商品到着後7日以内に、注文番号を添えてお問い合わせフォームからご連絡ください。」と答える、というように、正解例を学習させていきます。
SFTは
- 自社で用意した模範回答をそのまま反映させやすい
- 出力の形式や口調をコントロールしやすい
- 後述するほかの手法の土台にもなる
というメリットがあり、実務でも活用されることが多いです。SFTだけである程度の成果が出やすいため、いきなりほかの高度な手法を導入する必要はありません。
DPO(選好最適化)
DPO(Direct Preference Optimization)は、好ましい回答と好ましくない回答のペアを学習させ、人間にとって好ましい方向へ出力を寄せていく手法です。
SFTが「正解そのもの」を教えるのに対し、DPOは「どちらがより好ましいか」という相対的な好みを教える点に違いがあります。同じ質問に対する2つの回答を並べ、「こっちの方がよい」とモデルに教えていくイメージです。
そのため、DPOは単独で使うというより、SFTで基礎を固めたうえで、仕上げの調整として組み合わせることもあります。
たとえば、
- 回答の丁寧さ
- トーン
- 安全性
といった正解が一つに定まりにくい内容を整えたいときに役立ちます。
フルファインチューニング
フルファインチューニングは、モデルのすべての重みを更新する、最も本格的な手法です。モデル全体に手直しを行うため、目的やデータが適切であれば、品質向上が見込める場合があります。
より深く業界特有の用語や社内ルール、専門的な判断基準をモデルに反映させたい場合に役立ちます。
ただし、その分
- 大量のGPUメモリが必要になる
- 学習にかかるコストと時間がかさむ
- 破滅的忘却(もともとできていたことが劣化する現象)のリスクがある
のように導入する負担やリスクも大きくなります。特に破滅的忘却により、新しい振る舞いを学習させた結果、もともと得意だったタスクの精度まで落ちてしまうことも起こり得ます。
そのため、フルファインチューニングは、目的や運用体制、コストとのバランスを見極めながら慎重に検討する必要があります。
LoRA
LoRA(Low-Rank Adaptation)は、元のモデルは保ったまま、少数の追加パラメータだけを学習させる手法です。フルファインチューニングの「重さ」を解決するために生まれた、軽量なアプローチになります。
モデル本体には手を加えず、一部分のみ学習するイメージであり、
- 必要な計算資源を大きく抑えられる
- 学習にかかる時間を短縮しやすい
- 破滅的忘却のリスクを小さくできる
のようなメリットがあります。
特に、既存モデルの知識を活かしながら、新しいタスクへの適応だけを追加できる点が特徴です。用途ごとに小さな追加内容を管理できるため、複数のカスタマイズ版を運用しやすくなります。
QLoRA
QLoRA(Quantized LoRA)は、LoRAをさらに軽量化した手法であり、元のモデルを4bitに圧縮したうえでLoRAを適用する手法です。
量子化による品質低下に注意しつつ、必要なGPUメモリを抑えられるのが特徴です。
QLoRAには、
- 大規模モデルをより少ないGPUメモリで扱いやすくなる
- 個人や小規模チームでも検証しやすくなる
- 学習コストを抑えながら、LoRAによる追加学習を行える
のようなメリットがあり、本来なら複数のGPUが必要な規模のモデルでも、モデルサイズやGPUメモリの条件によっては、1枚のGPUで検証できる場合があります。手元の環境でも気軽に試しやすく、導入のハードルを下げてくれるでしょう。
手法は理解できても、「自社の目的にはどれが合うのか」「どこから手をつければよいのか」という判断をするのは簡単ではありません。
リベルクラフトでは、課題整理から最適な手法の選定、PoC、本格導入、運用改善まで一気通貫で支援しているため、手戻りや不要な開発コストをかけずにAI活用を進められます。
専門人材が社内にいない場合でも、本格導入を見据えた設計や実装方針の整理、プロジェクト推進もサポートできるため、AI導入をスムーズに進められる点もメリットです。
ファインチューニングを含め、自社に合ったAI活用を効果的に進めたい方は、ぜひ以下からリベルクラフトへご相談ください。
⇨リベルクラフトへの無料相談はこちら
LLMのファインチューニングでできること
ファインチューニングは、汎用モデルのままではできなかった「自社ならではの使い方」を実現するための手段です。
具体的に何ができるようになるのか、代表的な5つの効果を見ていきましょう。
- 出力フォーマットを安定させられる
- 独自の文体・口調を再現できる
- 特定タスクの精度を引き上げられる
- 自社独自の語彙・分類ルールを反映できる
- 推論コスト・レイテンシを下げられる
出力フォーマットを安定させられる
ファインチューニングの大きな利点の1つが、出力の形式を毎回そろえられる点です。
汎用モデルにプロンプトで細かく指示しても、余計な前置きが付いたり、項目が抜けたりと、出力が安定しないことがあります。
後続の処理にデータを渡すときは、このような表記ゆれが意外と面倒です。
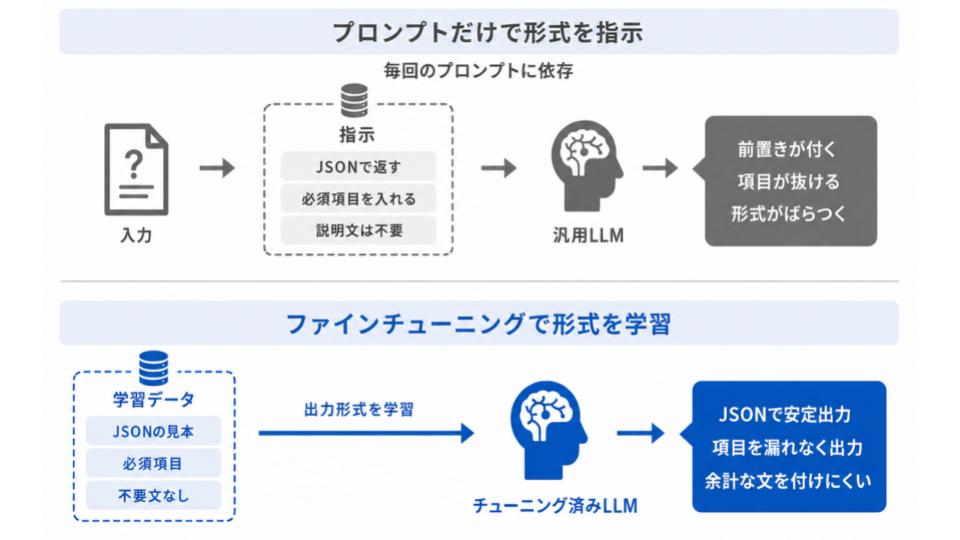
あらかじめ「この形で出力する」というお手本を学習させておけば、
- JSON形式で返しやすくする
- 決まった項目を漏れなく埋める
- 不要な説明文を付けない
といった内容を安定して再現できます。プロンプトを長々と書き込まなくても形式が崩れにくくなるため、システムへの組み込みも楽になるでしょう。
独自の文体・口調を再現できる
自社のブランドや用途に合わせた文体・口調を、一貫して再現できるのもファインチューニングの強みです。
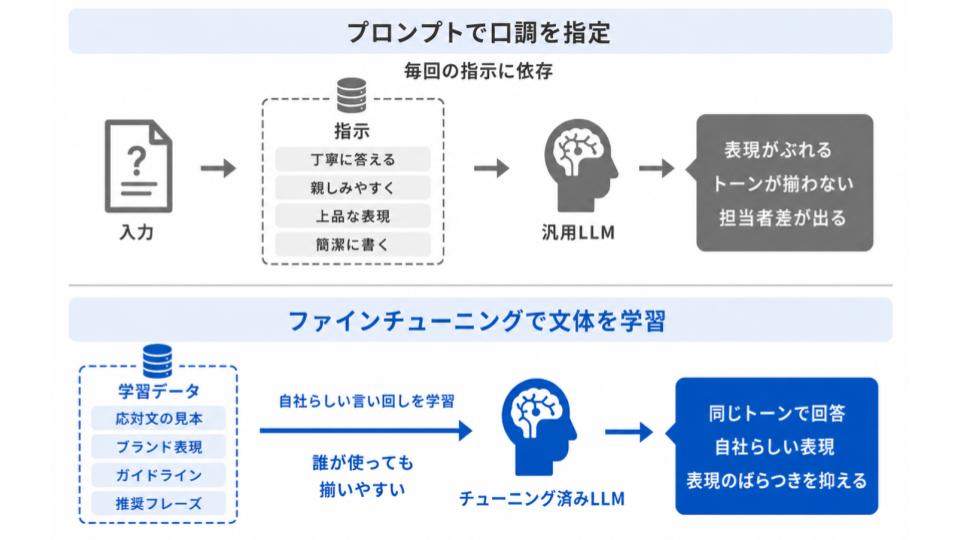
たとえば、
- カスタマーサポートでは、丁寧で落ち着いたトーンにしたい
- 若年層向けのサービスでは、親しみやすい口調にしたい
- 社内向けのツールでは、簡潔でわかりやすい文章にしたい
のように、どのような印象で伝えたいかを調整するには、プロンプトで「丁寧に答えて」と指示するだけでは、表現にばらつきが出てしまうことがあります。
実際のやり取りやガイドラインに沿った文章をお手本として学習させれば、モデルが自社らしい言い回しを覚え、誰が使っても同じトーンの回答を返しやすくなります。
特定タスクの精度を引き上げられる
特定の業務に絞って学習させることで、そのタスクに関する精度を引き上げられます。
汎用モデルは幅広い質問に答えられる反面、専門性の高い分野や、自社特有の判断が求められる作業では知識が不足している場面もあります。
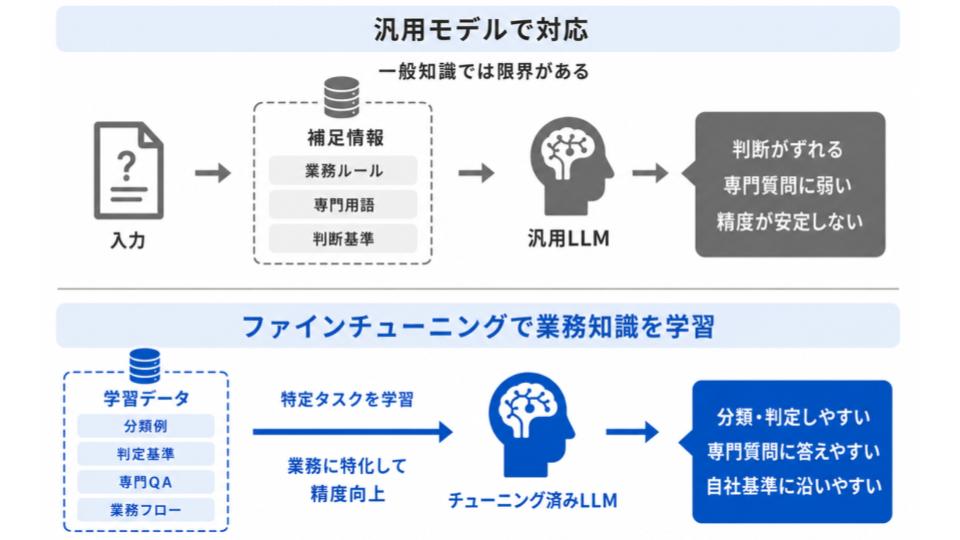
また、一般的には正しい回答でも、自社のルールや業務フローに照らすと適切ではないケースもあります。
そこで、業務の専門的なお手本データを学ばせれば、
- 自社の業務に特化した分類・判定ができる
- 専門領域の分類・要約・抽出などで、目的に合った出力を返しやすくなる
といった形で、汎用モデルでは実現が難しかった精度に近づけられるでしょう。
特に、専門性の高い問い合わせ対応やレビュー判定、文書分類のように判断基準が明確な業務では、よりファインチューニングが役立ちます。
自社独自の語彙・分類ルールを反映できる
社内でしか通じない略語や製品名、独自の分類ルールをモデルに覚えさせられるのも重要なポイントです。
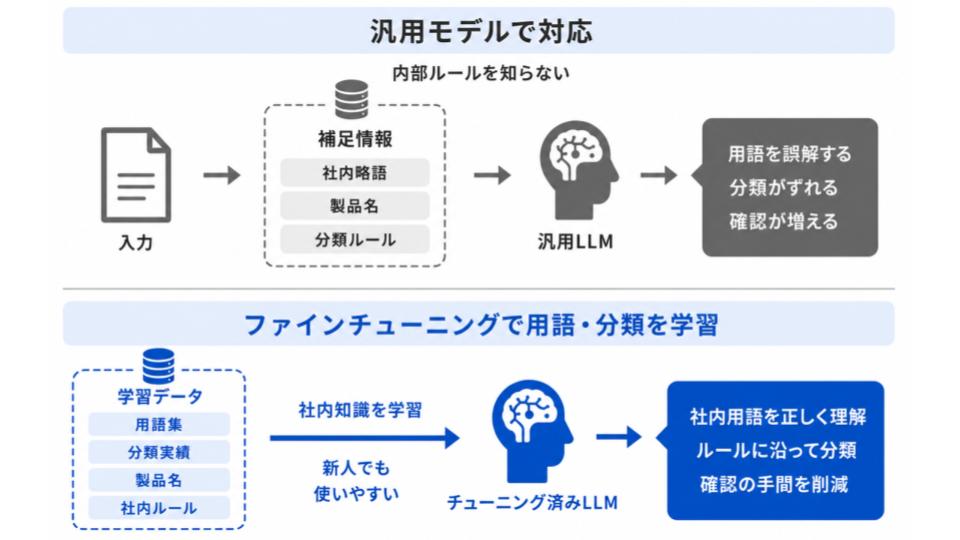
どの企業にも、外部の人には伝わりにくい言葉づかいや、自社なりの分け方があるでしょう。汎用モデルはこうした内部のルールを知らないため、そのままでは間違った解釈をしてしまうこともあります。
自社の用語集や過去の分類実績をお手本に学習させておけば、
- 社内用語を正しく理解して回答する
- 自社のルールに沿ってカテゴリ分けする
といった対応ができるようになります。
また、社内の決まりや言葉は、資料にまとめていても毎回確認されるとは限りません。モデルに学習させておくことで、新しく入った人でも使いやすくなり、説明や確認にかかる手間を減らせます。
推論コスト・レイテンシを下げられる
ファインチューニングは推論時のコストや応答速度(レイテンシ)の改善にもつながります。
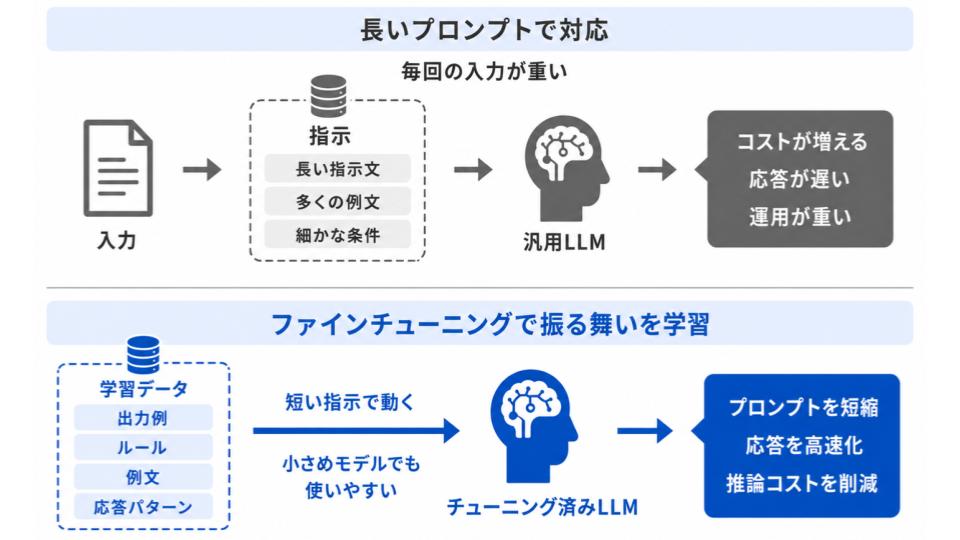
汎用モデルで思いどおりの出力を得ようとすると、長い指示文や大量の例をプロンプトに詰め込む必要が出てきます。プロンプトが長くなるほど処理するテキスト量が増え、費用も応答時間もかさんでしまいます。
あらかじめ振る舞いを学習させておけば、
- プロンプトを短くでき、処理コストを削減できる
- 余計な説明を省けるぶん、応答が速くなる
- 小さめのモデルでも十分な品質を出しやすくなる
などのメリットがあり、運用にかかる費用やAIの回答の待ち時間を抑えられるようになるでしょう。また、入力内容がシンプルになることで、アプリケーション側の実装や保守も行いやすくなります。
社内データの活用という観点では、ファインチューニングだけでなくRAGとの組み合わせも有効です。ChatGPTと社内データを掛け合わせる具体的な手順を知りたい方は、以下の記事もあわせてご覧ください。
参照記事:ChatGPT×RAGで社内データを活用する5つの手順。精度を向上させる施策も解説
LLMファインチューニング実装の5ステップ
ここからは、実際にファインチューニングを進める流れを5つのステップに分けて解説します。
目的を明確にし、環境とデータを整え、設定を決めて学習を進める、という一連の流れを押さえておくことが大切です。
- 1.目的とベースモデルを決める
- 2.環境を構築する
- 3.学習データを準備する
- 4.学習設定(ハイパーパラメータ)を決める
- 5.学習を実行し、評価する
1.目的とベースモデルを決める
最初にやるべきは、「何を達成したいのか」をはっきりさせることです。
出力形式を安定させたいのか、特定タスクの精度を上げたいのか、自社らしい口調を再現したいのかなどによって、選ぶべき手法が変わってきます。
ベースモデルを選ぶときは、性能だけでなく、費用や扱えるデータ量、運用のしやすさもあわせて確認しておくことが大切です。
反対に、目的が曖昧なまま進めてしまうと、
- どんなデータを集めればよいかが定まらない
- 何をもって成功とするかの評価軸がぶれる
- 学習の方向性が安定しない
のように使ってもらえないLLMになってしまうこともあります。
先に目的をそろえておくことで、関係者との認識違いを防ぎやすくなり、後から判断に迷ったときの基準にもなります。
2.環境を構築する
目的が決まったら、次に学習を行うための環境をそろえます。
ローカルで実装する場合は、最低限GPU・Python・主要なライブラリが必要です。なかでも代表的なライブラリを、以下の表に整理しました。
| ライブラリ | 役割 |
|---|---|
| PyTorch | 学習全体の土台となる基盤ライブラリ |
| Transformers(Hugging Face) | モデルの読み込みや学習を行う中心的な存在 |
| PEFT | LoRAやQLoRAといった軽量な手法を実現する |
| bitsandbytes | 4bit量子化(QLoRA)に使う |
| TRL | SFTやDPOの学習を簡潔なコードで書ける |
環境を用意するときは、いきなり本番用の大きなモデルで試すのではなく、まずは小さなモデルで学習まで一通り動かしてみるのがおすすめです。
モデルを読み込めるか、学習が途中で止まらないか、GPUのメモリが足りるかを先に確認しておくと、本番の学習に入ってから原因調査に時間を取られにくくなります。
また、自社のPCだけで対応が難しい場合は、クラウド環境を使う方法もあります。必要な計算資源を一時的に用意できるため、初期費用を抑えながら試しやすいのがメリットです。
3.学習データを準備する
実装するうえで一番大事であるポイントが、この学習データの準備です。
SFTであれば、「指示・入力・理想的な出力」のペアをJSON形式などで用意します。お手本となるデータの中身が、そのままモデルの振る舞いに反映されるため正解となるデータに絞りましょう。
特に意識したいのは、以下の3つの観点です。
- 一貫性:表記やルールがそろっていて、矛盾したお手本が混ざっていない
- 多様性:偏りがなく、想定される入力の幅をカバーできている
- 品質:誤りやノイズが少なく、お手本として信頼できる
実際にデータを作るときは、いきなり大量に用意するのではなく、まずは少量で形式や内容を確認するのがおすすめです。サンプルを見ながら、指示文の書き方や出力内容がそろっているかを確認してから増やしていくと、後から直す手間を減らせます。
また、学習に使うデータと、仕上がりを確認するためのデータは分けておきましょう。学習に使っていない例で試すことで、本番に近い場面でも期待どおりに答えられるかを見やすくなります。
学習データの整え方や生成AIを使った効率化について詳しく知りたい方は、以下の記事もあわせてご覧ください。
参照記事:生成AIを用いてデータ分析を効率化!やり方や注意点・活用事例も紹介
4.学習設定(ハイパーパラメータ)を決める
データがそろったら、学習の進め方を決める「ハイパーパラメータ」を設定します。
ハイパーパラメータとは、学習の振る舞いに影響する各種の設定値のことです。LoRAを使う場合は、LoRA特有の設定に加えて、学習全体に関わる値も決めていきます。
代表的なものは
- 学習率:1回の学習でどれくらいモデルを更新するか
- エポック数:同じデータを何回くり返し学習させるか
などがあり、これらの値次第で、学習の質が大きく変わります。
たとえば、学習率が高すぎると、一度に大きくモデルを変えすぎて回答が安定しにくくなり、低すぎると学習がなかなか進みません。
最初から完璧な値を狙うより、基本的な設定から始めて、結果を見ながら少しずつ調整するのがよいでしょう。
5.学習を実行し、評価する
設定まで終わったら、いよいよ学習を始めます。
学習中は、学習がうまく進んでいるかを示す数値を見ながら、問題がないかを確認します。
たとえば、間違いの大きさを表す「loss」という数値が少しずつ下がっていれば、順調に学習できている目安になります。反対に、急に大きく上がったり、ほとんど変わらなかったりする場合は、設定やデータを見直したほうがよいでしょう。
LoRAやQLoRAのような軽い学習方法を使えば、必要なPCの性能を抑えながら何度も試しやすくなります。
また、学習中にエラーが出た場合は、エラーの内容だけでなく、直前に変えた設定やデータもあわせて確認しましょう。
ここまでで「ファインチューニングの具体的な手順はわかったが、自社のリソースだけで進めきれるか不安」という方は、リベルクラフトへご相談ください。
進め方の相談から対応しているため、初めて取り組む場合でも安心して進められます。ぜひ、以下から無料相談のお申し込みをしてみてください。
⇨リベルクラフトへの無料相談はこちら
LLMファインチューニング成功の2つの考え方
手法と実装手順を見てきましたが、同じくらい重要なのがLLMファインチューニングを成功させる考え方です。
ここでは、ファインチューニングで失敗しないために、事前に押さえておきたい考え方を紹介します。
- ファインチューニングで解くべき課題であるか
- 評価方法を学習の前に決めておく
ファインチューニングで解くべき課題であるか
最初に確認したいのは、その課題が本当にファインチューニングで解くべきものなのかという点です。
よくあるのが、「最新情報を答えさせたい」「社内文書を見て回答させたい」といった目的で、ファインチューニングを選んでしまうケースです。
こうした「知識を増やしたい」という目的には、RAGのほうが向いています。モデルを何度も学習し直すより、参照するデータを更新するほうが、手間も費用も抑えやすいためです。
判断の目安は、課題が次のどちらに近いかです。
- 知識を増やしたい(最新情報・社内文書を見て答えたい) → RAGが向いている
- 答え方を変えたい(出力形式・口調・特定の作業に合わせたい) → ファインチューニングが向いている
出力の形式や口調、特定の作業に合わせた回答など、「答え方そのもの」を整えたい場合に、ファインチューニングが向いています。
RAGとの使い分けの判断軸や、社内情報を効率よく検索・共有する方法について詳しく知りたい方は、以下の記事もあわせてご覧ください。
参照記事:AIナレッジマネジメントとは?RAGとの違いや社内情報の検索・共有を効率化する方法を解説
評価方法を学習の前に決めておく
もう1つ大切なのが、学習を始める前に「どうなれば成功か」を決めておくことです。
ここを後回しにすると、学習が終わったあとに「なんとなく良くなった気がする」という感覚だけで判断することになり、本当に良くなったのかを見極められません。
具体的には、
- 学習に使っていないテストデータを分けておく
- 学習前後を比較して、本当に改善したかを見る
- 破滅的忘却が起きていないか確認する
- 定量化が難しいタスクは、人手評価やLLM-as-a-judgeを併用する
のような準備をしておき、学習後に同じ条件で確認できるようにしておくことが大切です。先に判断の基準を決めておけば、結果を見て次に何を直すべきかも考えやすくなります。
また、評価する人によって判断が分かれないように、よい回答とよくない回答の例もあらかじめ用意しておくと安心です。
LLMファインチューニングの実装・運用は「リベルクラフト」
ここまで、ファインチューニングの基本やRAGとの違い、代表的な手法、実装の流れ、成功させるための考え方を解説してきました。
ファインチューニングで大切なのは、まず「本当にファインチューニングが必要な課題なのか」を見極め、目的やデータ、評価方法まできちんと決めておくことです。
とはいえ、
- 自社の課題にどの手法が合うのかわからない
- データの準備や評価まで、自社だけで進められるか不安
と感じる方も多いのではないでしょうか。
そんな時はリベルクラフトへご相談ください。
リベルクラフトでは、いきなりツールや手法を決めるのではなく、まずは現在の課題や目的を整理するところからご支援します。
そのうえで、適した手法の選定、学習データの準備、学習、評価、実際の業務での活用までサポート。手探りで進めるより、最初に押さえるべきポイントを整理しておくほうが、結果的にスムーズに進めやすくなります。
また、作って終わりではなく、使いながら精度を確認し、必要に応じて改善していくところまで対応しています。ファインチューニングを自社の業務にどう活かせばよいかお悩みの方は、以下のリンクからお気軽にご相談ください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



