エージェンティックRAG(Agentic RAG)とは|RAGの進化系譜と精度が出ないときの使い分け

「社内データでRAGをPoC(概念実証)してみたが、思ったほど精度が出ない」という方も多いでしょう。マニュアルや規定を読み込ませたのに、肝心の質問にはぼんやりした答えしか返ってこない、という経験は珍しくありません。
しかし、その原因はベクトルモデルを差し替えるといった細部のチューニングよりも、RAG(検索拡張生成)の仕組み全体が古いままになっていることにあるケースが多いです。RAGはこの数年で大きく進化しており、その流れの先端にあるのがエージェンティックRAG(Agentic RAG)です。
そこで本記事では、
- 従来(ネイティブ)RAGで精度が出ない3つの理由
- ネイティブ→アドバンスド→モジュラー→エージェンティックというRAGの進化系譜
- エージェンティックRAGとは何か、その仕組みと代償
- ユースケース別の使い分けと、段階的に導入する進め方
についてわかりやすく解説します。RAGを検討中、または導入済みで精度に悩んでいるAI・DX推進のご担当者の方は、ぜひ最後までご覧ください。
RAGの精度が出ず、どこを改善すべきか切り分けたいという方は、リベルクラフトへご相談ください。
⇨リベルクラフトへの無料相談はこちら
RAGで精度が出ない原因は、仕組み全体が古いこと
エージェンティックRAGの話に入る前に、まずなぜ多くの企業のRAGで精度が出ないのか、その原因を整理しておきます。ここを押さえると、後半の進化系譜が腑に落ちやすくなります。
RAGとは何かを最小限おさらいする
RAG(Retrieval-Augmented Generation・検索拡張生成)とは、LLM(大規模言語モデル)が持つ知識だけに頼らず、登録した社内ドキュメントなどを検索し、見つけた関連情報をもとにLLMに回答させる仕組みを指します。社内データを扱う生成AI活用では、ほぼ必須の構成です。
仕組みの基礎そのものは、別の記事で詳しく扱っています。本記事では「RAGはこの数年でどう進化したか、そして自社はどの段階を使うべきか」に絞って解説します。
参照記事:社内データをRAGで活用する方法|ナレッジ整備の手順
なお、Claude Codeのような新しいAIエージェント型のツールでも、「社内の情報を検索して参照させる」という処理は形を変えて登場します。RAGは一過性の流行ではなく、社内データをAIに使わせる限りついて回る土台だと考えてよいでしょう。
細部のチューニングより仕組みのアップデート
RAGの精度が出ないと、多くの方はまず細部を疑います。ベクトル検索のモデルを差し替える、チャンク(文書を分割した断片)の大きさを変える、といった調整です。これらも効くことはありますが、効果は限定的なことが多いです。
精度が頭打ちになる本当の原因は、RAGの仕組み全体が初期型のまま止まっていることにあります。次の章で見るように、初期型のRAGには構造的な限界があり、そこを越えない限りパラメータをいじっても伸び代は小さいです。つまり、改善の入口は「どのパラメータを変えるか」ではなく「どの世代のRAGを使っているか」を見直すことになります。
従来(ネイティブ)RAGの3つの限界
ここまで、精度の頭打ちは仕組みの古さに原因があると整理しました。次に、その「古い仕組み」にあたる従来型のRAGがどういうもので、どこに限界があるのかを具体的に見ていきます。
一発検索の固定パイプライン
従来型のRAGは、ネイティブRAG(またはバニラRAG)と呼ばれます。処理の流れは固定されており、おおむね次のとおりです。
- ユーザーの質問を検索クエリに変換する
- ベクトル検索やテキスト検索で関連しそうな文書を探す
- 上位の数チャンクをLLMに渡す
- 1回だけ回答を生成する
この一直線の流れを1回通すだけで終わるのが特徴です。シンプルで構築しやすい反面、検索が外れても途中で気づく仕組みがなく、そのまま回答が出てきます。
横断比較・自己修正・検証が抜けている
ネイティブRAGには、大きく3つの限界があります。
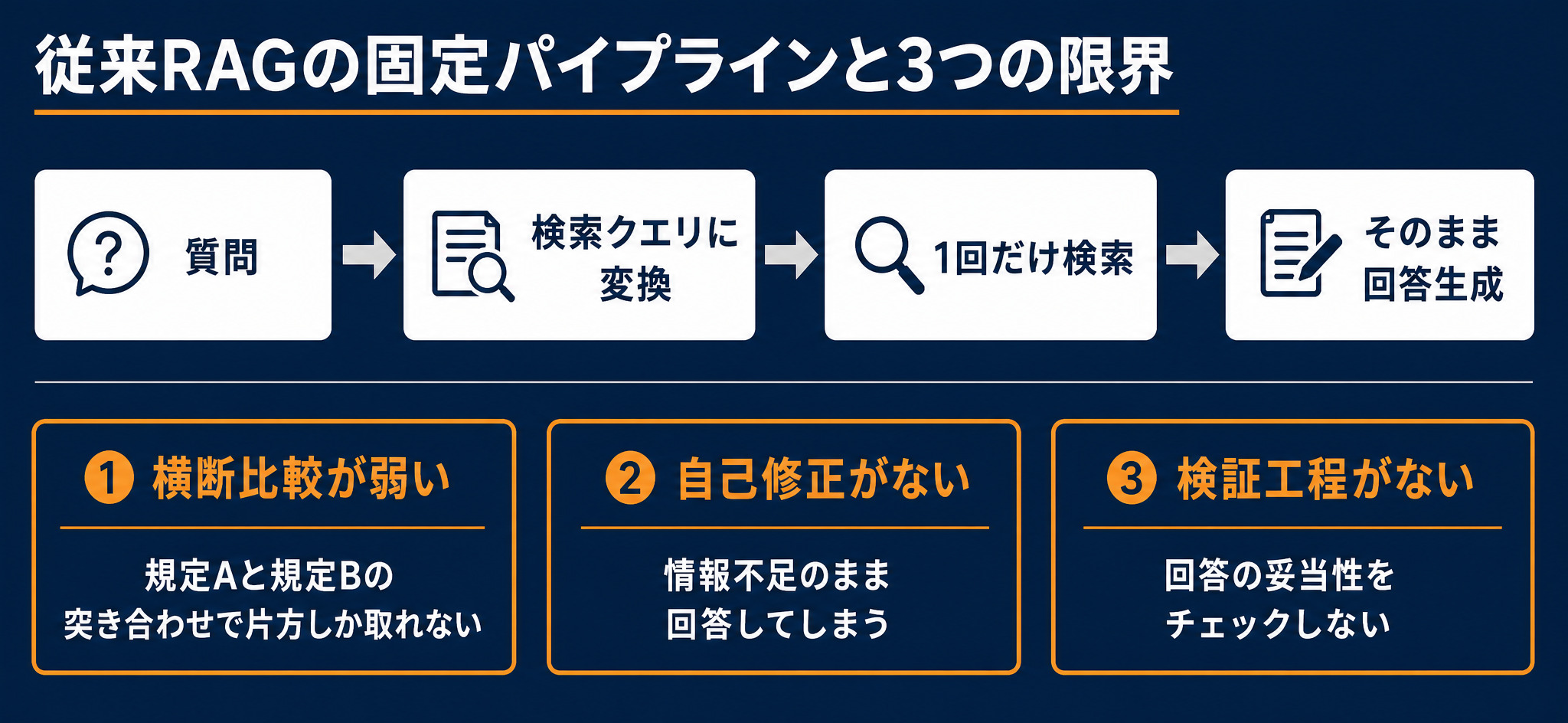
- 複数資料の横断比較が弱い:例えば「規定Aと規定Bを突き合わせて矛盾を指摘してほしい」という質問では、検索で片方の規定しか拾えず、片手落ちの回答になりがちです
- 自己修正ループがない:1回の検索で情報が足りなくても、追加で探し直すことをせず、不足したまま回答してしまいます
- 回答を検証する工程がない:出てきた答えが妥当かどうかをチェックせず、そのままユーザーに返します
この3つはいずれも「一発で検索して、一発で答える」という構造から来ています。人間であれば「この資料だけでは足りないな」と気づいて追加で調べ、答えを見直しますが、ネイティブRAGにはその当たり前の段取りが組み込まれていません。精度が出ないと感じる場面の多くは、この構造的な抜けが原因です。
RAGの進化系譜|ネイティブからエージェンティックまで
ネイティブRAGの限界が見えたところで、それをどう乗り越えてきたか、RAGの進化の流れを整理します。ここが本記事の骨格にあたります。
4つの世代をざっくり押さえる
RAGは2023年頃から急速に進化し、細かく分ければ無数の手法がありますが、大きな流れは次の4段階で捉えると分かりやすいです。

- ネイティブRAG:一発検索・一発生成の基本形
- アドバンスドRAG:検索の質そのものを高める工夫を加えた形
- モジュラーRAG:各機能を部品として独立させ、用途に応じて組み替える形
- エージェンティックRAG:AIが状況を見て、自律的に計画・検索・検証を選ぶ形
進化したからといって、後の世代がつねに正解というわけではありません。今は単一の手法に固執せず、状況に応じて最適なものを選ぶ時代になっています。だからこそ、それぞれが何を解決する世代なのかを知っておくことが、自社に合った構成を選ぶ前提になります。次の章から、アドバンスド以降を順に見ていきます。
アドバンスドRAG|検索の質を上げる、いまのデフォルト
進化系譜の2段目、アドバンスドRAGから具体的に説明します。ここは「もはや当たり前」になりつつある世代なので、自社のRAGがここに達しているかをまず確認したいところです。
ハイブリッド検索・リランキング・クエリリライト
アドバンスドRAGは、ネイティブRAGの「検索の質」を引き上げる工夫の集まりです。代表的なものは次の3つです。
- ハイブリッド検索:意味の近さを捉えるベクトル検索に、キーワードの表層一致を見るテキスト検索を組み合わせます。製品IDや型番のように「文字列が完全に一致するか」が重要な情報は、キーワード検索のほうが強いため、両方を併用すると取りこぼしが減ります
- リランキング:いったん検索で集めた候補を、質問との関連度であらためてスコアリングし直し、本当に関連の高いものを上位に並べ替えます
- クエリリライト:ユーザーの質問をそのまま検索に使わず、検索でヒットしやすい表現に書き換えてから検索します
例えば「先月の不具合報告で、型番XY-100に関するものを探したい」という質問では、型番部分はキーワード検索で確実に当て、文脈部分はベクトル検索で補う、という使い分けが効きます。
「アドバンスド」がアドバンスでなくなった
これらの工夫は、登場した当初は先進的でしたが、今ではRAGを作るうえでほぼデフォルトの構成になっています。いわば「アドバンスドがアドバンスではなくなった」状態です。
裏を返せば、自社のRAGがいまだに一発検索のネイティブのままなら、まずはこのアドバンスドRAGの水準に引き上げるだけで、精度が目に見えて改善することが多いです。エージェンティックのような高度な構成を検討する前に、足元の検索品質がこの水準に達しているかを確認するのが先決です。
モジュラーRAG|機能を部品にして組み替える
アドバンスドRAGで検索の質を上げたら、次は構成の柔軟さの話になります。それを担うのがモジュラーRAGです。
モジュラーRAGとは、検索・リランキング・検証といった各機能を、レゴブロックのように独立した部品(モジュール)として扱う考え方です。用途に応じて、部品を追加したり、外したり、差し替えたりします。
例えば、扱うデータ量が少なければリランキングのモジュールを省いて軽くする、回答の正確さが重要で時間に余裕があるなら検証用のモジュールを足す、といった調整ができます。処理の大枠(ワークフロー)自体は固定されたままですが、その中身の部品を柔軟に入れ替えられるのが特徴です。
このモジュール化は、次に説明するエージェンティックRAGへの橋渡しにもなります。機能が部品として独立していれば、「どの部品をいつ使うか」をAI自身に判断させる、という発想に進めるからです。
エージェンティックRAGとは|自律的に計画し、検証するRAG
ここまでの3世代は、流れの大枠を人があらかじめ決めていました。エージェンティックRAGは、その大枠の判断そのものをAIに委ねる点で一線を画します。本記事の中心テーマなので、丁寧に見ていきます。
「1発で動く」から「計画して動く」への転換
エージェンティックRAGとは、固定されたワークフローを通すのではなく、状況に応じてAIが自律的に「次に何をすべきか」を選びながら回答を組み立てるRAGを指します。設計者はモジュール(後述するツール)を用意しておき、そのどれをどう使うかはLLMの判断に任せます。
ネイティブRAGが「決めた手順を1回通せば動く」だったのに対し、エージェンティックRAGは「まず計画を立て、その計画に沿って動く」へと進め方が変わります。これは、従来のRAGに判断役の「エージェント層」を一枚重ねたもの、と捉えると分かりやすいです。
AIエージェントそのものの考え方は、別の記事で詳しく解説しています。
3つのレイヤーで構成される
エージェンティックRAGは、大きく3つの層で構成されます。
- 知識データ層:社内文書のデータベース、Web、CRM/SFAなど、情報の取り出し元になるデータソース
- ツール層:検索、リランキング、外部API呼び出し、Web検索、計算用スクリプトなど、エージェントが使える道具
- エージェント層:質問に対してどう動くかを判断・計画する頭脳の部分
ここで押さえておきたいのは、「エージェントがあればRAGは要らない」という見方は誤りだということです。エージェント層がどれだけ賢くても、知識データ層から必要な情報を取り出す検索(リトリーバル)は引き続き欠かせません。RAGはなくなるのではなく、エージェントの土台として組み込まれる方向に進んでいます。
自己修正ループの中身
エージェンティックRAGの肝は、自己修正のループです。実際の流れはおおむね次のようになります。
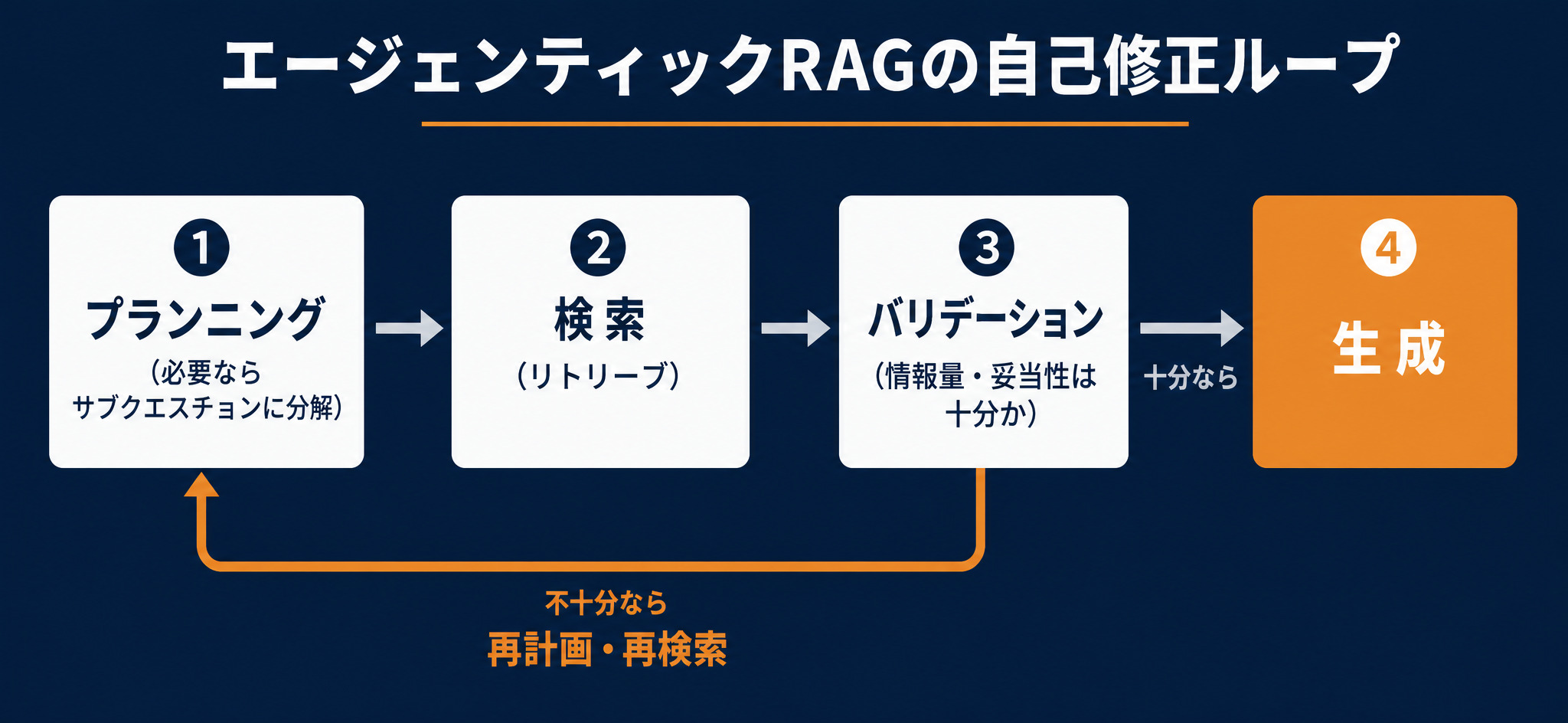
- 計画(プランニング):質問を受け、必要なら複数のサブクエスチョンに分解します。例えば1つの質問を5〜6個の小さな問いに分け、並列で検索する、Web検索も併用する、といった段取りを立てます
- 検索(リトリーブ):立てた計画に沿って、関連情報を取り出します
- 評価(バリデーション):集まった情報の量や妥当性が、回答に十分かを判定します。業務特化の用途なら、ベテランが品質を確かめるときの観点をプロンプトや仕様に書いておくと、判定の精度が上がります
- 再計画または生成:情報が不十分なら計画に戻って追加検索し、十分なら回答を生成します
このループは原理的には何度でも回せますが、実務ではコストを抑えるために上限回数を設けることもあります。途中の検索結果を見ながら次の検索を組み立てる進め方は、マルチホップ検索とも呼ばれます。人間が調べ物をするときの「足りないからもう少し探す」という動きを、そのままAIに肩代わりさせるイメージです。
ツールコーリングが回答の幅を広げる
エージェンティックRAGをもう一段強くするのが、ツールコーリング(ツール呼び出し)です。LLMは文章の生成は得意な一方、正確な計算や集計は苦手です。そこで、計算はPythonなどのスクリプトを用意して任せます。
データソースへのアクセスも同様です。Web検索はWeb検索API、社内データは社内DBの参照、顧客情報はCRM/SFA(SalesforceやHubSpotなど)のAPIやMCP(Model Context Protocol・外部ツールとAIをつなぐ規格)連携で取りに行きます。どのツールをどの場面で使うかはエージェントが判断しますが、使える道具そのものは設計者が前もって用意しておく必要があります。
このように、RAGに判断とツールが加わると、単なる文書検索を超えて、計算や業務システムの参照まで含めた回答が組み立てられるようになります。自社のどのデータや業務システムをツールとしてつなぐべきか整理したい場合は、構想段階からご相談いただけます。
⇨リベルクラフトへの無料相談はこちら
インデックス型とファイル探索型|検索のしかたを使い分ける
エージェント層が複数のツールを使い分けられるようになると、「そもそもどう検索するか」にも選択肢が出てきます。ここでは、対照的な2つの検索方式とその使い分けを説明します。
ファイル探索型RAGの台頭
従来のRAGは、あらかじめ文書をベクトル化して索引(インデックス)を作っておく方式が主流でした。図書館の蔵書目録を先に整えておくイメージです。
これに対し、近年は事前の索引を作らず、その場で直接ファイルを探しに行く方式が増えています。ファイル探索型RAGと呼ばれ、Claude Codeのようなツールが採用しています。ちょうど、目録を作らずにフォルダの中を直接grep(文字列検索)するような動きです。
ファイル探索型の利点は、準備が手軽なことです。索引を作り込まなくても、対象のファイルを置くだけで使い始められ、用途によっては9割近い精度が出ることもあります。一方で弱点もあります。図や画像、OCR(文字認識)が効かない手書き文書には弱く、データ量が増えると毎回の探索コストが膨らみます。
データ規模で選ぶ・ハイブリッドにする
インデックス型とファイル探索型は、どちらかが一方的に優れているわけではなく、一長一短です。目安は次のとおりです。
- 大規模なデータを安定して扱いたい:事前に索引を作るインデックス型が有利です
- 小〜中規模をサクッと立ち上げたい:準備の軽いファイル探索型が向きます
そして、エージェンティックRAGの強みは、この2つを状況に応じて使い分けられることです。エージェントに複数の検索ツールを持たせ、大量データの照会にはインデックス型、手早く済ませたい照会にはファイル探索型、というハイブリッド構成にできます。つまり、検索方式を1つに決め打ちせず、質問ごとに最適な道具を選ばせるのが、エージェンティックRAGならではの強みです。
エージェンティックRAGの代償と、向き不向き
ここまではエージェンティックRAGの強みを中心に説明してきました。ただし、強力なぶん代償もあります。導入を判断するうえで、コスト・速度・難易度のトレードオフを正しく押さえておく必要があります。
コスト・レイテンシ・設計難易度
エージェンティックRAGには、主に3つの代償があります。
- コスト増:計画と再検索を繰り返すぶん、消費するトークン(LLMが処理する文字量の単位)が増え、利用料が上がります。LLMの提供各社が単価を引き上げる動きもあり、特定ベンダーへの依存度(ベンダーロックイン)にも注意が要ります
- レイテンシ増:ループを回すぶん、回答までの待ち時間が長くなります
- 設計・制御の難易度上昇:自律的に動く範囲が広がるほど、想定外の動きを抑える設計や制御が難しくなります
要するに、エージェンティックRAGは「高精度だが、遅くて高くて作るのが難しい」という性格を持ちます。だからこそ、どの業務に使うかの見極めが重要になります。
定型はシンプルに、複雑はエージェンティックに
向き不向きは、扱う業務の性質で切り分けられます。
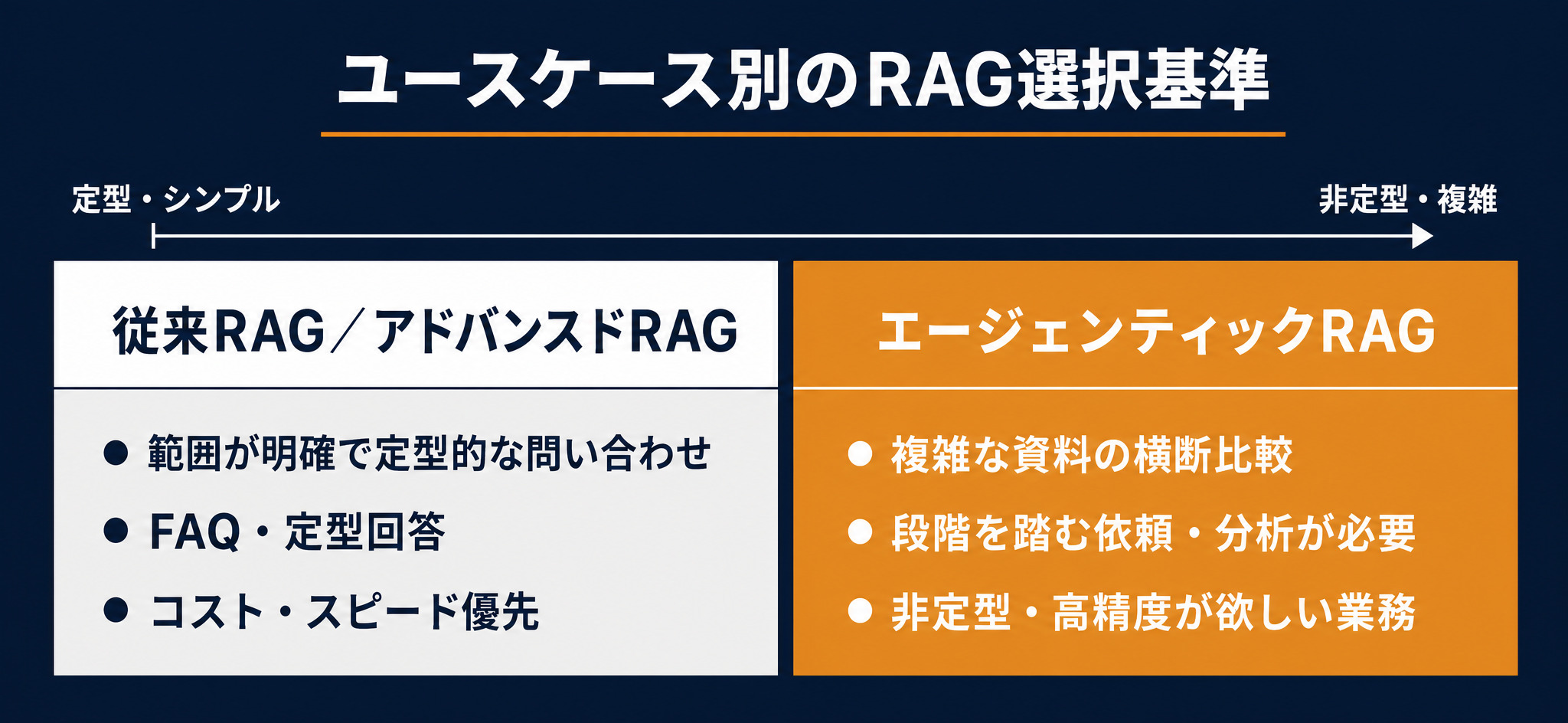
- 従来RAG・アドバンスドRAGで十分な業務:範囲が明確で定型的な問い合わせ(FAQ的なもの)。コストとスピードを優先したい場面では、シンプルな構成のほうが適しています
- エージェンティックRAGが向く業務:複雑な資料を横断比較する、段階を踏んで進める依頼、分析が必要なもの、少人数でも時間をかけて高い精度がほしい非定型業務
例えば「就業規則のこの条文はどう書いてあるか」という定型的な問い合わせに、毎回計画と再検索のループを回すのは過剰です。一方、「複数の契約書を突き合わせて、リスクのある条項を洗い出す」といった非定型で横断的な作業は、エージェンティックRAGの自己修正ループが効いてきます。つまり、定型・高頻度はシンプルに、非定型・高難度はエージェンティックに、と業務ごとに割り当てるのが基本方針になります。
段階的な導入戦略|現在地を見定めてから打ち手を選ぶ
向き不向きが整理できたら、最後に、自社でどう導入を進めるかという順番の話に移ります。いきなり最先端を目指すのではなく、段階を踏むのが現実的です。
土台から積み上げる3ステップ
導入は、次の順で積み上げるのが基本です。
- まず従来RAGで土台を作る:どのデータをナレッジの対象にするかを決め、検索して答える基本形を立ち上げます
- アドバンスドRAGで精度を上げる:ハイブリッド検索やリランキングを入れ、検索品質を引き上げます
- 一部の業務にエージェンティックRAGを適用する:横断比較や分析が必要な非定型業務に絞って、自己修正ループを導入します
いきなりエージェンティックRAGから始めると、土台になるデータ整備も検索品質も追いつかず、コストだけがかさんで成果が出にくくなります。まずは下段を固め、効果を確かめながら上段へ進むのが堅実です。
課題を特定してから打ち手を決める
段階を進めるうえで欠かせないのが、自社の現在地を見定め、何が精度を下げているのかを特定することです。
例えば「図や画像の含まれる資料に弱い」のが課題なら、打ち手はエージェント化ではなく、画像を扱えるようにするデータ整備かもしれません。「複数資料の横断検索が弱い」のが課題なら、エージェンティックRAGの自己修正ループが効きます。課題によって最適な打ち手は変わるため、「とりあえずエージェント化する」と決め打ちするのは禁物です。
この、問題を分解し、課題を特定し、打ち手を最適化するという流れは、RAGに限らずAI活用全般の肝です。実際の検証では、まず小さくPoCを回して、自社のデータでどこまで精度が出るかを確かめるのが定石です。
そして、ここで人に残る仕事は「設計」の部分です。どのデータを対象にし、どのツールを用意し、どんな評価観点で品質を測るか。この設計を決めることが、エージェンティックRAGを使いこなす鍵になります。RAGで扱うデータをどう整えるか、レポート生成までAIに任せる構成については、以下も参考になります。
参照記事:AIでレポート作成を自動化する方法|分析から報告まで自走させる
まとめ
RAGで精度が出ないとき、見直すべきは細部のチューニングよりも仕組みの世代です。本記事の要点を整理します。
- RAGの精度が頭打ちになる原因は、一発検索のネイティブRAGが持つ構造的な限界にあることが多い
- ネイティブRAGの限界は、横断比較の弱さ・自己修正の不在・検証工程の不在の3つ
- RAGはネイティブ→アドバンスド→モジュラー→エージェンティックと進化してきた
- アドバンスドRAG(ハイブリッド検索・リランキング・クエリリライト)は今やデフォルトで、まずここに達しているかを確認する
- エージェンティックRAGは、AIが計画→検索→検証→再計画の自己修正ループを回し、ツールコーリングで業務システムまで含めて回答する
- 高精度なぶん、コスト・レイテンシ・設計難易度という代償がある
- 定型・高頻度はシンプルな構成、非定型・高難度はエージェンティックと業務ごとに割り当てる
- 導入は従来RAGで土台→アドバンスドで精度向上→一部にエージェンティックの順で、課題を特定してから打ち手を選ぶ
エージェンティックRAGは万能の正解ではなく、自社の課題に応じて段階的に取り入れる選択肢の1つです。まずは自社のRAGがどの世代にあり、どこで精度を落としているかを見定めることから始めるとよいでしょう。
ウェビナー資料(ホワイトペーパー)のダウンロード
本記事のテーマは、ウェビナー「エージェンティックRAGとは」でも、RAGの進化系譜・自己修正ループ・ユースケース別の使い分けを、図解とともに詳しく解説しています。進化系譜と段階的導入の考え方をまとめたスライド資料を、無料でダウンロードいただけます。
⇨ウェビナー資料のダウンロードはこちら
RAG・エージェンティックRAGの相談は「リベルクラフト」
ここまで読んで、「進化の流れは分かったが、自社のRAGがどこで精度を落としているのか、どこから手をつければよいか、自分たちだけでは切り分けきれない」と感じた方も多いのではないでしょうか。
リベルクラフトでは、戦略・構想の立案から、AIシステムのものづくり、社内人材を育てる教育・スクールまでの3軸で、企業のAI・データ活用の内製化を支援しています。RAGの現在地の診断から、ナレッジ基盤の構築、エージェンティックRAGの設計・PoC・開発、RAG機能を内包したSaaS「ソクラグ」の提供まで、一貫してサポートします。
次のようなニーズをお持ちの方に適しています。
- 導入済みRAGの精度が出ず、どこを改善すべきか切り分けたい
- 社内文書のナレッジ基盤を、検索品質まで含めて作り込みたい
- 横断比較や分析が必要な業務に、エージェンティックRAGを適用したい
構想段階のご相談でも問題ありません。自社のRAGをどの世代へ、どう進めるか。まずはお気軽にご相談ください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



