生成AIで情報漏洩は起こるのか|「学習・クラウド・公開設定」3つのリスクで判断する

「社内のデータを生成AIに入れたら、情報が漏れてしまうのではないか」と不安に感じている方も多いでしょう。現場では使いたい一方で、経営層や情報システム部門から待ったがかかり、結局活用が進まないという声もよく聞きます。
ただ、漏洩のリスクをひとまとめに「危ないから禁止」としてしまうと、かえって管理できない別のリスクを呼び込みます。本当に必要なのは、どのリスクが・どんな仕組みで起こるのかを切り分け、自社のデータと契約に合わせて判断する視点です。
そこで本記事では、
- 生成AIで情報漏洩が起こる仕組み(「学習」と「参照」の違い)
- 漏洩リスクを「学習・クラウド・公開設定」の3つに分けて整理する考え方
- ツールの可否を分ける判断軸(DPA)と、機密レベル別の使い分け
についてわかりやすく解説します。生成AIの利用方針を社内で整理したいDX推進・情報システム担当の方は、ぜひ最後までご覧ください。
「生成AIに社内データを入れてよいか判断できず止まっている」という方は、リベルクラフトへご相談ください。
⇨リベルクラフトへの無料相談はこちら
生成AIに社内データを入れると情報漏洩は起こるのか
最初に結論からお伝えすると、生成AIに社内データを入れて情報漏洩が起こるかどうかは、「どう使うか」と「どんな契約で使うか」によって決まります。同じデータを入力しても、無料の個人アカウントで使う場合と、契約を結んだ法人プランで使う場合とでは、残るリスクの大きさがまったく違います。
つまり、「生成AIだから漏れる・漏れない」と一律に語ることはできません。サービスの種別や設定、契約の有無によって、残るリスクが変わってくるためです。本記事では、その違いを順を追って整理していきます。
結論:漏れるかは「使い方と契約」で決まる
生成AIを使ったときに情報が外部へ流出するのは、多くの場合「入力した情報がモデルの学習に使われる」「データがクラウドに保存される」「設定が公開状態になっている」のいずれかが原因です。これらはそれぞれ性質が異なり、対策も別物です。
逆にいえば、原因ごとに正しく手当てをすれば、社内データを業務で活用しながらリスクを抑えることは十分に可能です。多くの企業がSalesforceやSlackといったクラウドサービスに業務データを預けながら運用できているのと、考え方は同じです。
一律禁止が招く「シャドウAI」という別のリスク
自社の情報を守ることは重要ですが、その手段として「生成AIは全面禁止」という極端な判断をすると、別のリスクが生まれます。それが「シャドウAI」です。
シャドウAIとは、会社が許可していないにもかかわらず、従業員が個人の端末やアカウントで勝手に生成AIを使ってしまう状態を指します。業務効率の差が大きいほど、現場は隠れてでも使おうとします。禁止しているつもりでも、実態としては会社の管理がまったく届かない利用が広がってしまうのです。
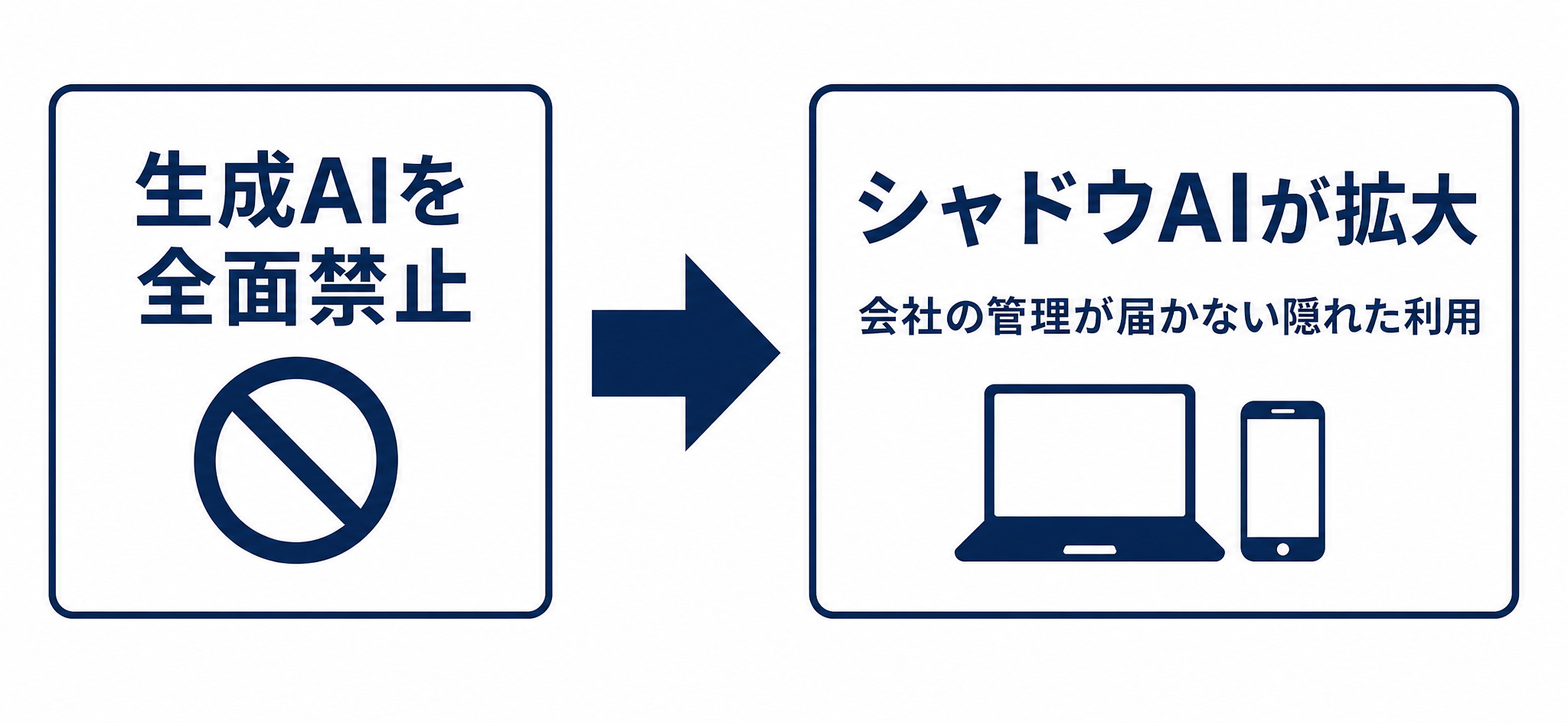
ガートナーの予測では、2030年までに40%以上の企業がシャドウAIに起因するインシデントを経験するとされています(参考:Gartner)。社内のソースコードを生成AIに入力して機密が流出したとされる事例も報じられていますが、本質的な問題は「AIを使ったこと」ではなく「管理できない環境で使わせたこと」にありました。
問われるべきは「使うか禁止か」という二元論ではなく、「どのリスクを、どう管理するか」です。ITの利用可否を今さら議論しないのと同じで、生成AIも基本的には使う前提に立ち、残るリスクを管理する方向で考えるのが現実的です。
情報漏洩を判断する前提|「学習」と「参照」は別物
漏れるかどうかは使い方次第とお伝えしましたが、その判断をするには、生成AIにデータを渡したとき実際に何が起きているかを正しく理解しておく必要があります。ここでつまずきやすいのが、「学習」と「参照」の混同です。
この2つはまったく別の概念で、混同したまま判断すると的外れな対策を打ち続けることになります。社内の議論でも、本来は「参照」にすぎないものを「学習されてしまう」と誤解して、必要のないところまで禁止しているケースは少なくありません。
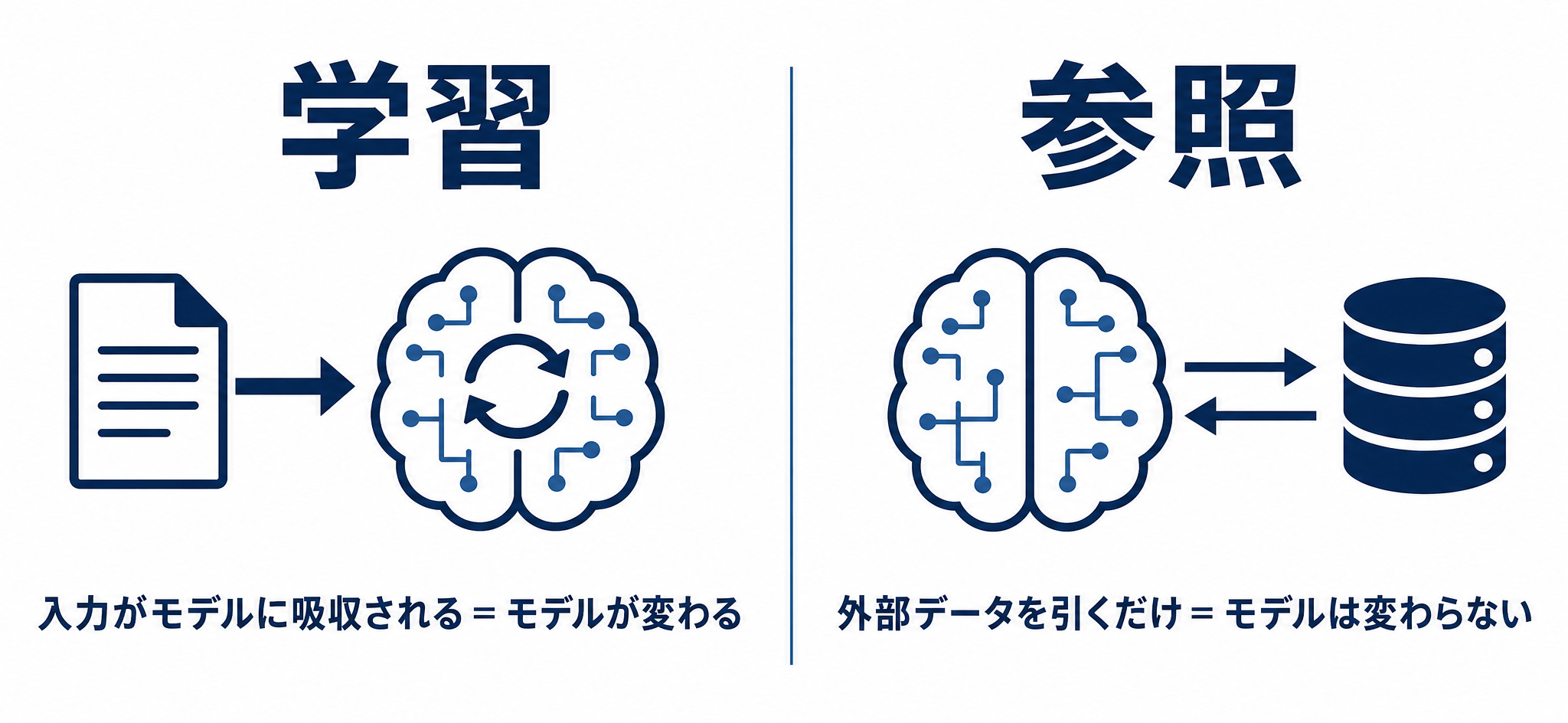
学習とは|入力がモデルそのものに吸収される
「学習」とは、入力したデータによって生成AIモデル(LLM)の内部のパラメータ、いわばAIの頭脳そのものが書き換わることを指します。一度学習されると、その情報はAIの知識として蓄積され、別のユーザーへの回答に影響する可能性があります。
これが、情報漏洩の文脈で最も警戒すべきリスクです。自社の機密情報がモデルに吸収され、回答を通じて第三者の目に触れる可能性が出てくるためです。
ただし、入力データが常に学習に使われるわけではありません。たとえばChatGPTの無料プランは、初期設定では入力が学習に使われる場合があるとされていますが、設定でオプトアウト(学習利用の停止)をしたり、後述する法人向けプランを使ったりすれば、学習に使われない状態にできます。これが「生成AIに情報漏洩しない使い方はあるのか」という問いへの一つの答えになります。
参照とは|RAG・AIエージェント・MCPはモデルを変えない
一方で、「参照」はモデルの中身を変えません。ユーザーの質問に対して、社内文書やナレッジベースなどの外部データを一時的に引いてきて、それをもとに回答を生成する仕組みです。引いてくるだけなので、モデルのパラメータはそのままです。
社内データを活用する代表的な手法であるRAG(検索拡張生成)や、AIエージェント、MCP連携は、いずれもこの「参照」にあたります。社内のデータベースにアクセスする、外部のAPIを呼ぶ、といった動作はすべて参照の範囲であり、モデルがデータを吸収することはありません。
つまり、RAGのように「社内文書を参照して回答させる」使い方では、モデルが社内情報を覚えてしまう心配は基本的に不要です。社内文書そのものや、それを格納したナレッジベースは、ただのデータベースであり学習ではありません。「参照させると学習されるのではないか」という不安の多くは、この切り分けで解消できます。
RAGで社内データを参照させる具体的な手順は、ChatGPT×RAGで社内データを活用する5つの手順で詳しく解説しています。
生成AIの情報漏洩リスクは3種類に分けて考える
学習と参照を切り分けたうえで、生成AIにまつわる情報漏洩リスクの全体像を整理します。社内の議論では複数のリスクが一緒くたになり、「とにかく危ない」で話が止まってしまいがちです。リスクは大きく次の3つに分けると論点がはっきりします。
| リスクの種類 | 何が起こるか | AI固有か | 主な対策 |
|---|---|---|---|
| 学習のリスク | 入力がモデルの学習に使われ、回答を通じて流出する | AI固有 | オプトアウト設定・法人プラン(DPA) |
| クラウド保存のリスク | データがベンダーのクラウドに送信・保存される | SaaS全般と同じ | DPA・既存SaaSと同じ基準で判断 |
| 公開設定のリスク | 設定の誤りで入力が第三者から見える状態になる | ユーザー側の設定ミス | 初期設定の確認・オプトアウト |
この表の3つを切り分けられると、対策はかなりシンプルに考えられます。それぞれを順に見ていきます。
学習のリスク
1つ目の学習のリスクは、前章で説明したとおり、入力情報がモデルの訓練に使われてしまう可能性です。3つの中で唯一、生成AIに固有のリスクといえます。
対策は、設定でのオプトアウト、もしくは法人向け・エンタープライズプランの契約です。法人プランでは、入力データを学習に使わないことが契約として保証されるため、個別の設定に頼らずに学習リスクを抑えられます。
クラウド保存のリスク
2つ目は、入力したデータがベンダーのクラウドサーバーに送信・保存されることに対するリスクです。これは生成AIに限った話ではありません。
SalesforceやSlack、Google Workspace、SharePointなど、すでに多くの企業が業務データをクラウドサービスに預けています。生成AIのクラウド利用も、本質的にはこれらと同じ構造です。「AIだから特有の危険がある」と考えるのではなく、既存のクラウドサービスと同じ基準で判断するのが妥当です。多くの企業がこれらのSaaSを安心して使えているのは、後述するDPAで管理されているためです。
公開設定のリスク
3つ目は、ユーザーがサービスの設定を誤り、入力した内容が公開状態になってしまうリスクです。これはAIの技術的な問題ではなく、ユーザー側の設定ミスに起因します。
対策は、初期設定の確認とオプトアウトの徹底です。運用ルールとして「初回利用時に公開設定を確認する」と定めておけば防げる種類のリスクです。つまり、リスクを「どの種類の話か」で切り分けられると、現場で「この使い方は本当に危ないのか」を冷静に判断できるようになります。
「この使い方は社内で許可してよいのか」を切り分ける段階で迷うことが多い、という方は、リベルクラフトが生成AIの利用方針の整理からご支援しています。
⇨リベルクラフトへの無料相談はこちら
生成AIによる情報漏洩の事例から原因を切り分ける
リスクを3つに分けたところで、実際に起きた事例がどのリスクに当たるのかを見てみます。事例を「AIが原因なのか、使い方や設定が原因なのか」という視点で読むと、自社で同じことを起こさないための勘どころがつかめます。
サムスンのソースコード流出|管理されない環境での利用
広く知られている事例として、サムスンの技術者が社内のソースコードなどを生成AIに入力し、機密情報が外部に流出したとされるケースがあります。生成AIの情報漏洩を語るうえで、たびたび引き合いに出される事例です。
この事例のポイントは、問題の本質が「生成AIを使ったこと」そのものではなく、「会社として管理できない環境で使わせていたこと」にある点です。学習リスクを抑える契約や設定がないまま、機密性の高い情報を入力してしまったことが原因でした。逆にいえば、適切な契約と運用ルールのもとで使っていれば、防げた可能性が高いといえます。
公開設定による個人情報の露出|AI固有ではなく設定ミス
もう1つ、生成AIサービスに入力した個人情報が、公開設定がオンになっていたために第三者から閲覧できる状態になっていた、という種類のトラブルもあります。入力した本人が公開設定に気づいていなかったケースです。
このとき「やはり生成AIは危ない」と結論づけてしまいがちですが、原因は生成AI固有のリスクではなく、公開設定を確認しなかったという設定ミスです。前章の3分類でいえば「公開設定のリスク」に当たり、初期設定の確認で防げる種類の問題です。
このように事例を原因で切り分けると、「AIだから危ない」のではなく、「管理されない環境」や「設定の確認漏れ」が問題だったとわかります。打つべき対策も、AIを禁止することではなく、契約と運用を整えることに向かいます。
「このツールは可、あのツールは不可」を分ける基準
事例の多くは管理や設定の問題でした。では、組織として「このツールは使ってよい、あれはだめ」をどう線引きすればよいのでしょうか。ここで判断軸になるのが、ツールそのものの特性ではなく、ベンダーとの契約です。
現場では「Copilotは使えるのに、なぜ別のAIツールはだめなのか」といった疑問がよく出ます。同じような性能のツールなのに可否が分かれるのは、不公平に感じられるかもしれません。しかし、この線引きには明確な根拠があります。
判断軸はツールの特性ではなくDPAの有無
ツールの可否を分ける基準は、企業とベンダーの間でDPA(Data Processing Agreement・データ処理契約)が結ばれているかどうかです。
たとえばCopilotが使えるのは、自社がMicrosoftと契約を結び、その中でデータの取り扱いについて取り決めているからです。一方、個人で別のAIツールを使う場合は、こうした契約がなく、学習に使われる可能性や管理できないリスクが残ります。
ですから、「別のツールも使いたい」という場合の正しい進め方は、「個人で使ってよいか」ではなく「会社としてDPAを結び、法人プランとして使えるようにする」ことです。ツール名で判断するのではなく、契約の有無で判断するという考え方です。
プライバシーポリシーとDPAの違い
ここで混同されやすいのが、プライバシーポリシーとDPAの違いです。「プライバシーポリシーに同意したから大丈夫」と考えられることがありますが、両者は性質が異なります。
| 項目 | プライバシーポリシー | DPA(データ処理契約) |
|---|---|---|
| 性質 | ベンダー側の説明文 | 法的拘束力を持つ契約 |
| 同意の形 | ユーザーが一方的に同意する | 企業とベンダーが取り交わす |
| 保証される内容 | 取り扱いの方針が説明されている | 学習に使用しないこと等が契約として保証される |
プライバシーポリシーは、ベンダーが「自社はこう取り扱う」と説明し、ユーザーがそれに同意したという位置づけにとどまります。一方、DPAは法的拘束力を持つ契約であり、入力データをモデルの訓練に使用しないことや、侵害が発生した際の通知、データの保持期間の管理、暗号化といった内容が取り決められます。
社内で説明する際は、「主要ベンダーのAIは、SalesforceやMicrosoftと同じ基準でDPAを結んでいる。個人アカウントとは別物だ」と伝えると、経営層の承認も取りやすくなります。なお、各サービスのプラン内容や契約条件は変わりやすいため、導入時には各社の公式リファレンスをそのつど確認してください。
データの機密レベルで使い分ける(クラウド・閉域・オンプレ)
ツールの可否はDPAで判断できますが、もう1つ重要な軸があります。それが、扱うデータの機密レベルです。社内データはすべて同じ重要度ではないため、ツール単位の判断に加えて、データの中身に応じて使うAI環境を変える、という視点が必要になります。
社内データを機密レベルで分類し、それぞれにどのAIソリューションを適用するかを決めておくと、「一律で禁止」も「無条件に許可」も避けられます。ここでは大きく3つの段階に分けて考えます。
一般〜社外秘|DPA付きの法人クラウドプラン
一般的な情報から社外秘レベルの情報までは、DPAを結んだ法人向けのクラウドAIサービスで扱えるケースが多くなります。学習リスクが契約で抑えられ、クラウド保存のリスクも既存のSaaSと同じ基準で管理できるためです。
大手AIベンダーの法人プランは、データの取り扱いについて相応の水準が確保されているため、日常的な業務利用の多くはこの範囲でカバーできます。まずは扱うデータがこのレベルに収まるかを見極めることが出発点です。
高機密情報|ローカルLLM・オンプレミス環境
一方で、クラウドに出すこと自体が認められない高機密情報もあります。たとえば製造業の門外不出のノウハウ、医療における患者情報、行政・公共領域の機微な情報などです。こうしたデータは、クラウド型のAIサービスを使うこと自体がリスクになります。
この場合の選択肢が、ローカルLLMやオンプレミス環境の構築です。近年はGoogleのGemmaやAlibabaのQwen、OpenAIのGPT-OSSといったオープンソースのモデルが成長し、閉じた環境でも実用的なAIが動くようになりました。かつては数千万円規模の投資が必要なこともありましたが、小規模なPoC(試験的な導入)であれば、現実的な予算で始められるようになっています。
リベルクラフトでも、外部に出せない機密性の高いデータを扱う現場で、閉域のクラウド環境にLLMとデータベースを統合し、大量の技術文書を構造を保持したままナレッジベース化して参照させる仕組みを構築した実績があります。さらに機密性が高く、閉域クラウドすら使えない領域では、オンプレミス環境でLLMを動かすプロジェクトにも携わっています。セキュリティ要件はデータと環境によって変わるため、使い方は一択ではありません。
データを機密レベルでどう分類し、どこから棚卸しするかは、AI導入前に必須の「社内データ棚卸し」5ステップで具体的に解説しています。つまり、データを分類してから環境を選ぶ、という順序を踏むと判断がぶれません。
生成AIの情報漏洩対策を進める現実的なステップ
ここまでの判断軸を踏まえて、実際に何から着手すればよいかを整理します。すべてを一度にやろうとする必要はありません。順番に積み上げていくことが、結果的に近道になります。
- 野良AIの利用を禁止する:素性のわからないAIサービスや、個人アカウントでの業務利用を、まず止めます。一定規模の企業であれば、安全性が確認できないツールの利用は基本的に禁止するところから始めます。
- 主要ベンダーの法人プランを契約する:DPAを結べる主要ベンダーの法人・エンタープライズプランを、会社として契約します。これで日常業務の多くを、管理された環境でカバーできます。
- 必要に応じてローカル環境を検討し、データ分類基準を策定する:高機密情報を扱う場合はローカルLLMを検討しつつ、社内データの機密レベルの分類基準を整備します。
これらを、たとえば半年ほどかけて段階的に進めていくイメージです。判断基準が整わないうちに「とりあえず禁止」としてしまうと、最初に触れたシャドウAIのリスクが膨らみます。順番に整備しながら、安全に活用できる範囲を広げていくのが現実的です。
まとめ
本記事では、生成AIの情報漏洩リスクを仕組みから整理し、判断するための考え方を解説しました。要点は次のとおりです。
- 漏れるかどうかは「使い方と契約」で決まる。一律禁止はシャドウAIという別のリスクを招く
- 「学習」と「参照」は別物で、RAG・AIエージェント・MCP連携は参照であり学習ではない
- 漏洩リスクは「学習・クラウド保存・公開設定」の3種類に分けて考えると論点が整理できる
- ツールの可否はDPAの有無で判断する。プライバシーポリシーは説明文、DPAは法的拘束力を持つ契約
- データの機密レベルに応じて、法人クラウド・閉域・オンプレを使い分ける
生成AIを「危ないから禁止」で止めるのではなく、リスクを切り分けて判断する。この視点を持てれば、社内データを活用しながらリスクを抑える道筋が見えてきます。
ウェビナー資料(ホワイトペーパー)のダウンロード
本記事で解説した「学習と参照の違い」や「3つのリスクの切り分け」「機密レベル別の使い分け」は、ウェビナーでも詳しく取り上げています。社内での説明にそのまま使える図解つきのスライド資料を、無料でダウンロードいただけます。
⇨ウェビナー資料のダウンロードはこちら
生成AIのリスク判断・ローカルLLM構築の相談は「リベルクラフト」
ここまで、生成AIの情報漏洩リスクの仕組みと、使い方や契約で残るリスクが変わることを解説してきました。リスクを切り分ける考え方は整理できても、自社のデータと環境にどう当てはめるかは、判断に迷う場面が多いのではないでしょうか。
リベルクラフトでは、生成AIの利用方針の策定やリスクの切り分けといったコンサルティングから、RAGの構築、ローカルLLM・オンプレミス環境の構築、PoC、本格導入までを一気通貫で支援しています。RAGチャットボット・AIエージェントのSaaS「ソクラグ」や、法人向け研修・個人向けスクールも展開しています。
- 社内データを生成AIに入れてよいか判断できず止まっている
- 高機密情報を扱うのでローカル環境を検討したい
- 利用方針やルールの整備を相談できる相手がほしい
という方は、リベルクラフトへお気軽にご相談ください。機密性の高いデータを扱う現場での支援実績をもとに、「自社のどのデータを、どの環境で扱うべきか」からご相談いただけます。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



