【2026年最新】主要なLLMモデル8選一覧比較表。各モデルごとの用途も解説

ChatGPT、Claude、GeminiなどさまざまなLLMが増え続けるなかで、「それぞれの違いや自社への活かし方がよくわからない」と感じる方も多いのではないでしょうか。
各モデルの性能差がわかりにくく、とりあえず有名なものを選んでしまったり、気づけば想定以上のコストがかかっていたりするケースも少なくありません。
そこで本記事では、
- LLMモデルとは何かの基礎知識
- 主要8モデルの比較表と各モデルの用途
- モデル選定の比較ポイント
- 一覧比較の際の注意点
をわかりやすく解説します。これからLLMモデルの活用を検討している方も、現在使っているモデルを見直したい方も、ぜひ最後までご覧ください。
「LLMモデルを業務に活用するための仕組みを構築したいが、何から始めればよいかわからない」という方は、リベルクラフトへご相談ください。
リベルクラフトでは、LLMモデルの選定から構築・運用まで一貫してサポートしています。業務フローに合わせた柔軟なカスタマイズにも対応していますので、まずは以下のリンクからお気軽にお問い合わせください。
⇨リベルクラフトへの無料相談はこちら
LLMモデル(大規模言語モデル)とは?
LLMモデルとは、大量のテキストデータをもとに学習し、文章の生成・要約・翻訳・質問応答・コード生成などができる大規模言語モデルのことです。
LLMは数百億から数千億規模のパラメータを持ち、人間が普段使う言葉を理解して自然な文章で回答できる点が特徴で、ChatGPTやClaudeなどのAIツールの多くがこのLLMモデルを中心に構成されています。
LLMは大きく以下の2種類に分けられます。
- クラウドLLM:外部のクラウド上でLLMを動かし、手軽に利用できる
- ローカルLLM:自社サーバーや端末上でLLMを動かし、データを外部に出さずに使える
それぞれコスト・セキュリティ・カスタマイズ性の面で特徴が異なります。詳しくは次の見出しで解説します。
クラウドLLMとローカルLLMの違い
クラウドLLMは「インターネット経由で使うLLM」、ローカルLLMは「自社の環境内で使うLLM」であり、それぞれ特徴があります。
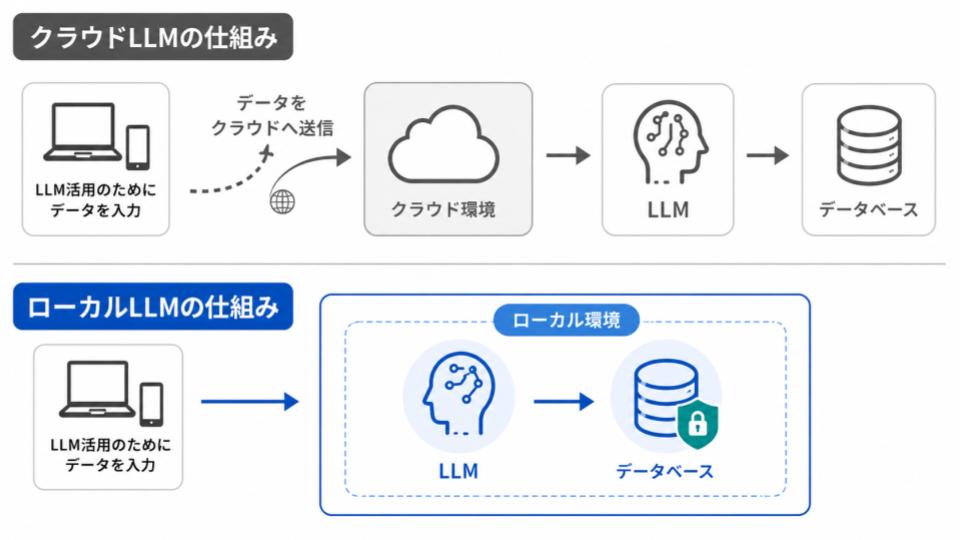
以下に2つの違いを整理しました。
| 項目 | クラウドLLM | ローカルLLM |
|---|---|---|
| 導入スピード | すぐに利用可能(SaaS / API提供) | 初期構築・設定が必要 |
| コスト | 利用量課金(API従量課金) | 固定費型 |
| 品質・性能 | 高品質・最新モデルが利用可能 | モデルにより差が出やすい (低精度から高精度まで) |
| セキュリティ | 外部API経由、機密情報送信リスクあり | データが社内完結 (持ち出し禁止文書に対応可) |
| カスタマイズ性 | ベンダー依存・制限あり | 自社要件に合わせた調整・統合が自由 |
| 運用・保守 | 運用不要 | 継続運用・アップデートが必要 |
| 代表モデル例 | GPT-5.5 / Claude Opus 4.8 / Gemini 3.1 Pro | Llama3 / Qwen3.6 /gpt-oss |
| ユースケース | ・初期PoCでのクイックな精度検証 ・汎用知識を扱うFAQ/文章要約 | ・オンプレ要件や閉域システム連携が必要な場合 ・持ち出し禁止データ(防衛・医療・公共)を扱う場合 |
クラウドLLMは、APIを利用することで、自社でモデルやサーバーを構築せずに高性能なモデルを導入しやすい点が特徴です。
一方ローカルLLMは、GPUサーバーなどの初期投資が必要ですが、クラウドLLMの従量課金のように使えば使うほどコストがかさんでいってしまうものではありません。
機密性の高い処理はローカル、最新モデルを使いたい処理はクラウド、など自社業務に合わせて使い分けると良いでしょう。
自社のデータ特性や利用頻度を踏まえたLLMの基盤設計の考え方については、以下の記事で詳しく解説しているので参考にしてみてください。
参照記事:LLMは、クラウドか?ローカルか? 〜RAG×AI Ready Dataで探る最適なAI基盤設計〜
生成AIとの違い
LLMは、生成AIという大きなくくりの中に含まれる一種です。主な違いは以下の表を参照してください。
| 項目 | LLMモデル | 生成AI |
|---|---|---|
| 概要 | 生成AIに含まれる一種 | LLMを含む、より広い概念 |
| 特徴 | テキストを中心に学習した大規模言語モデル | テキスト・画像・音声・動画などを生成するAI技術の総称 |
生成AIとは、新しいコンテンツを自動で生成できるAI技術の総称で、文章だけでなく画像・音声・動画まで幅広いデータを扱えるのが特徴です。
画像生成のMidjourneyや音楽生成のSunoも、その一種にあたります。
これに対してLLMモデルは、テキストやコードの処理を中心としたモデルであり、生成AIという大きなくくりの中で言語領域を強みとしています。
ここまでLLMについての概要を解説しましたが、「自社の環境だけで利用できるLLMを構築したい」という方は、リベルクラフトへご相談ください。
リベルクラフトでは、機密データを外に出さず、業務で安全に活用できるローカルLLMの構築が可能です。ただ、構築するだけでなく、RAGを活用して社内にある情報を反映できるため、自社業務に特化したLLMの構築支援が可能。
以下のリンクからまずは詳細をチェックしてみてください。
⇨リベルクラフトお問い合わせはこちら
【比較表】主要LLMモデル一覧
現在、多くのLLMモデルがありますが、以下に主要なLLMモデルを整理しました。
それぞれ強みや用途が異なるため、一覧表で全体像を把握した上で、各モデルの詳細を確認してみてください。
| 項目 | 開発元 | 区分 | 最新モデル | 用途 | 特徴 |
|---|---|---|---|---|---|
| GPT | OpenAI | クラウド専用 | GPT-5.5 | ・コーディング ・文章生成 ・業務自動化 など幅広い用途 | 汎用性が高くコーディング・推論に強い |
| Claude | Anthropic | クラウド専用 | Opus 4.8、Sonnet 4.6、Haiku 4.5 | ・文書作成・要約・分析 ・RAG ・コーディング支援 | 長文読解と自然な文章生成に強い |
| Gemini | Google DeepMind | クラウド専用 | Gemini 3.1 Pro Preview、3 Flash、3.1 Flash-Lite | ・マルチモーダルAIアプリ ・Google Workspace連携 | マルチモーダル対応、Googleサービスとの親和性が高い |
| Llama | Meta | ローカル可 | Llama 4 Scout、Llama 4 Maverick | ・ローカルLLM構築 ・自社環境でのカスタマイズ活用 | オープンウェイトで商用利用可 |
| Mistral | Mistral AI | ローカル可 | Medium 3.5、Small 4、Large 3 | ・コスト重視の業務自動化 ・ローカルLLM ・コーディング | 軽量ながら高性能なオープンウェイトモデルが多い |
| Command | Cohere | ローカル可 | Command A+ | ・RAG構築 ・企業データ検索 ・多言語処理 | RAGとの親和性が高く多言語対応が充実 |
| DeepSeek | DeepSeek | ローカル可 | DeepSeek V4 Preview | ・コーディング支援 ・コスト効率重視の業務自動化 | 低コストで高性能、コーディング・推論領域に注目が集まる |
| Qwen | Alibaba Cloud | ローカル可 | Qwen3系、Qwen3-Coder系 | ・多言語アプリ開発 ・コーディング支援 ・アジア市場向け活用 | コード生成と多言語処理が得意 |
GPT|幅広い用途に最適
出典:OpenAI
GPTは、OpenAIが開発・提供しているLLMです。ひとつのモデルで多様な業務をカバーしやすいため、初めてLLMを導入する企業でも活用イメージを持ちやすいモデルといえます。
2026年現在、OpenAIの最新モデルはGPT-5.5。コーディングや専門的な業務、複雑な情報分析に強いモデルで、分析にも活用しやすくなっています。
GPTが向いている主な用途は、以下のとおりです。
- コーディング支援、コードレビュー、デバッグ
- 大量の資料やドキュメントの要約・分析
- チャットボットや問い合わせ対応の自動化
- 画像を含むデータの読み取り・整理
- 企画書、メール、記事などの文章作成支援
また、ChatGPTの各プランやAPIを通じて利用しやすい点もGPTの強みです。LLMを試してみたい場合や業務システムに組み込みたい場合まで、幅広い導入フェーズで候補にしやすいモデルといえるでしょう。
Claude|長文読解・自然な文章作成に強い

出典:Anthropic
ClaudeはAnthropicが開発・提供しているLLMです。長い文章を正確に読み取る力と、自然で読みやすい文章を書く力が特にすぐれています。
GPTと並んでビジネスでの利用が多く、読みやすい文章を求める場面で高く評価されているモデルです。
2026年現在、Claudeの主なモデルには、Opus 4.8。Opus 4.8は複雑な推論やエージェント型コーディングに強い高性能モデルです。
Claudeが向いているケースは以下であり、
- 長い文章の要約・翻訳・文章づくりのサポート
- 社内文書を検索して回答に活かすRAGの仕組みづくり
- コーディング支援
- 自然な会話が求められるチャットボット
開発者向けには、コードを読み取り、ファイル編集やコマンド実行、開発タスクの自動化を支援するClaude Codeも提供されています。
Gemini|マルチモーダル・Google連携が可能
出典:Google
Geminiは、Google DeepMindが開発し、Googleが提供しているLLMです。
テキスト・画像・音声・動画をまとめて扱えることと、Google WorkspaceやGoogle Cloudと連携できる点が特徴です。
2026年現在、主なモデルには、Gemini 3.1 Pro。Gemini 3.1 Proは、複雑な推論やマルチモーダルな情報理解に強いモデルです。
Geminiは以下のケースに向いています。
- Google Workspace(Gmail・Docs・Meet)との連携
- 画像・動画を含む資料の自動解析
- 大量データの高速処理が必要なシステム
- Google Cloud上でのAIアプリ開発
また、APIを利用することでGoogle WorkspaceなどのGoogleのプラットフォーム上だけでなく、自社システムにも柔軟に組み込むことができます。
Llama|ローカルLLM・自社環境での活用に向いている
出典:Meta
LlamaはMetaが開発・提供するLLMです。モデルの中身が公開され、商用にも使える「オープンウェイト」である点が最大の特徴です。
データを外に送らず自社の環境で動かせるので、機密情報を扱う仕事や、セキュリティのルールが厳しい現場に向いています。
2026年最新のLlama 4にはScoutとMaverickの2つのモデルがあります。Scoutは一度に読み込める文章量も最大1000万トークンととても多く、長い資料もまとめて処理できます。
Llamaが向いているケースは以下であり、
- 機密情報を扱う仕事での社内向けLLM(ローカルLLM)の構築
- 自社データを使って独自に学習を追加したいケース(ファインチューニング)
- API費用をおさえたい大量処理
- 社内専用のAIシステムづくり
APIの利用料をかけずに使えます。
一方で、モデルを動かして管理するにはサーバー運用などの専門知識が必要なため、対応できるエンジニアがいるかを確かめてから選ぶことが欠かせません。
Mistral|軽量・高性能なopen-weightモデルが多い
出典:Mistral AI
MistralはフランスのMistral AIが開発・提供するLLMで、中身が公開された「オープンウェイト」のモデルと商用モデルの両方を展開しており、用途に合わせて選びやすい点が特徴です。
最新モデルには、指示どおりに動く正確さ・考える力・コード生成に強い最上位のMistral Medium 3.5があります。
Mistralが向いているケースは以下の通りです。
- コーディング支援・コードの見直し
- 社内向けLLMとして自社サーバーへ展開
- 費用対効果を重視した業務の自動化
- EUの規制に対応したシステムづくり
データを自国や自社で管理できる「データ主権」を大切にするAIとして開発されており、EUの規制やGDPRへの対応を重視する企業が選びやすいモデルです。
Command|RAG・多言語対応に強い
出典:cohere
CommandはCohereが開発・提供するLLMで、社内文書などを検索して回答に活かすRAGとの相性がよく、多言語対応にも強みがあります。
2026年最新モデルのCommand A+は、AIが自分で順番に作業を進める機能、画像なども扱える対応力、48言語に対応。
Commandが向いているケースは以下であり、
- 社内の情報をまとめた知識ベースを活用したRAGの仕組み
- 多言語対応が必要な問い合わせ対応
- 文書の仕分け・タグ付け・要約の自動化
- 大企業向けの自社専用環境への導入
RAGを構築したい企業には相性がよく、自社専用の環境への導入にも対応しているため、データを社外に出したくない企業も選びやすいです。
DeepSeek|低コスト・コーディング領域で注目

出典:DeepSeek
DeepSeekは中国のDeepSeek社が開発・提供するLLMで、推論・コーディング領域での性能が注目されています。
2026年最新のDeepSeek V4 Previewは、考える力と、自分で順番に作業を進める機能を大きく強化したモデルです。高性能なV4-Proと、軽量・低コストなV4-Flashの2階層で構成されています。
DeepSeekが向いているケースは以下の通りです。
- コードの作成・不具合の修正・整理
- 数学や論理的な考えが必要なシステム
- API費用をおさえたい大量処理
- 順を追って考える必要がある複雑な処理
中身が公開されたオープンウェイト版は自社サーバーでも動かせるので、API費用をおさえながらコーディング生成できます。
一方で、自社環境で使う場合は、GPUやサーバー運用の知識が必要です。
Qwen|多言語対応・コード生成で使いやすい
QwenはAlibaba Cloudが開発・提供するLLMで、多言語処理と、実用的なコードを生成する能力、さらに画像・動画を読み取るマルチモーダル対応が特徴です。
2026年最新のQwen3.7-Plusは、文章・コード生成に加えて画像や動画の読み取りもまとめて扱えるマルチモーダルモデルです。
なお、Qwen3.7-Plusや上位のQwen3.7-Maxは非公開モデルで、API経由での利用が基本です。一方で、ひと世代前のQwen3.6など、自社サーバーで動かせるオープンウェイト版も別途公開されており、費用をおさえて社内向けLLMを構築したい場合はこちらが選択肢になります。
Qwenが向いているユースケースは以下の通りです。
- 多言語対応が必要なソフトウェアの開発
- コーディング支援・コードの自動補完
- 画像・動画の内容を読み取るマルチモーダルなアプリ
- オープンウェイト版を活用した社内向けLLM(ローカルLLM)の構築
日本語・中国語・韓国語などの言語を扱う精度が高く、海外向けサービスの開発にも向いています。
LLMモデルを選んだあとの開発環境の整え方については、以下の記事で2つのパターンに分けて詳しく解説しています。モデル選定と合わせて参考にしてみてください。
参照記事:AI開発環境の構築方法を2つのパターンで解説。自社に最適な開発環境の選び方も
LLMモデルを選ぶ際の比較ポイント
LLMモデルを選ぶ際には公式や第三者サイトの性能ランキングなどで上位だからという理由だけで決めてしまうと、実際の業務では成果が出ないケースがあります。
ここでは、比較時に見ておくべき4つのポイントを解説します。
- 自社タスクで安定して使えるか
- 長文・根拠情報を正しく扱えるか
- コストと処理速度が業務に合うか
- 運用・連携しやすいか
自社タスクで安定して使えるか
LLMモデルを選ぶ上でまず確認すべきなのが、自社の業務で安定した回答が得られるかどうかです。
一般的な性能テストで高い点数を出しているモデルでも、自社ならではの業務文書や専門用語を扱わせると、回答の質が安定しないケースは少なくありません。
例えば、金融機関の契約書類・医療機関の記録文書など、業界特有の言い回しや略語が多い文書では、ハルシネーションが起きやすいです。
実際の業務で使う文書を使って試験的に運用し、
- 回答が社内ルールや専門知識と照らして正しいか
- 同じ質問に毎回一貫した回答が出力されるか
などを確認することが大切です。自社の現場で信頼して使えるモデルかどうかを見極めていきましょう。
長文・根拠情報を正しく扱えるか
RAGでは、長い文書の中から必要な情報を見落とさず、根拠に沿って答えられるかも大切です。
特に、長い仕様書・規約・マニュアルなど、重要な情報が文書全体に散らばっている資料を扱う用途では、長文を正しく読み取れるかどうかの確認が欠かせません。
また、RAGで検索結果を回答する場合は、
- 取り出した根拠を正しく参照できているか
- 関係ない情報が混ざっていないか
なども確かめる必要があります。
根拠をもとに説明できていれば、回答の妥当性を人が確認しやすく、社内利用にもつなげやすくなります。
RAGのナレッジベース設計は構築前から考えておくべき点が多くあります。以下の記事に詳しくまとめているので参考にしてください。
参照記事:RAGにおけるナレッジベースの構築方法。3つの重要な理由と注意点も解説
コストと処理速度が業務に合うか
LLMのコスト比較は、APIの単価ではなく、業務1回あたりの費用対効果で見ることが大切です。
1トークンあたりの価格が安くても精度が低ければ、人が直す手間が増えて、結局は高くついてしまうこともあります。
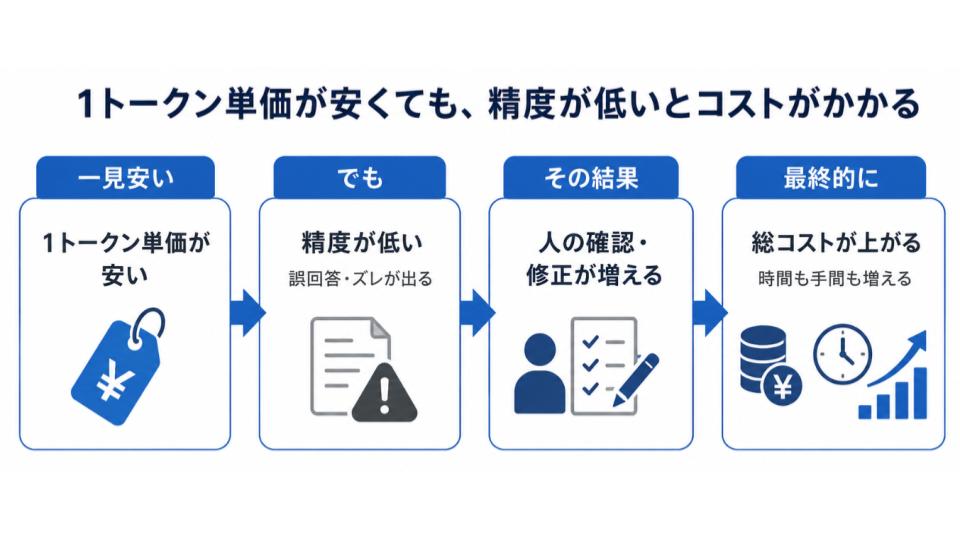
比較するときは、以下のように実際の業務に近い単位で試算してみてください。
| 業務の種類 | 試算の単位 |
|---|---|
| 問い合わせ対応 | 1件あたりのコスト |
| 議事録要約 | 1本(n文字)あたりのコスト |
| 記事・文書生成 | 1本あたりのコスト |
| 社内検索(RAG) | 1回の検索あたりのコスト |
処理の速さにも、チャットボットなどのその場ですぐ応答が必要な用途や、コードのテストなど時間をかけてまとめて処理してよい用途では、求められる性能が変わってきます。
必要以上に高性能なモデルをすべての業務に使うとコストがかさむ原因になりやすいため、用途ごとにモデルを使い分けることも検討しましょう。
運用・連携しやすいか
企業でLLMモデルを使う場合、モデルの性能と同じくらい大切なのが運用のしやすさです。
どんなに優れたモデルでも、今あるシステムとつなぎにくかったり、利用履歴を管理する仕組みが整っていなかったりすると、現場で使い続けるのが難しくなります。
確認しておきたい主なポイントは以下のとおりです。
- セキュリティ面は十分か
- 精度や異常を管理できるか
- サポート体制は整っているか
- 既存ツールと連携できるか
特にセキュリティ面では、クラウドLLMを使う際にデータがどこにあるのかを確認しておくことも欠かせません。
業種によっては法令やルールへの対応が必要になるため、導入前に情報セキュリティの担当者と確認しておくと安心です。
ただし、LLMモデルの比較や選定を自社だけで進めると、精度・コスト・セキュリティ・運用体制のどこを優先すべきか判断しきれない場合があります。
リベルクラフトでは、ローカルLLM・ローカルRAGの導入に向けて、業務要件の整理からモデル選定、PoC開発、本番運用まで一気通貫で支援。
自社環境で安全に生成AIを活用したい方は、まずはローカルAI・ローカルLLM導入支援の相談を検討してみてください。
⇨リベルクラフトへのお問い合わせはこちら
LLMモデルの一覧を比較する際の注意点
LLMモデルを比べるときは、性能や機能だけでなく、実際に使い始めた後のことも考えておくと、導入後の失敗を防ぎやすくなります。
- 最新モデルが必ず最適とは限らない
- ローカルLLMは運用コストも考える
- 日本語対応と日本語特化は分けて考える
最新モデルが必ず最適とは限らない
LLMモデルを選ぶ際によくあるのが、最新のものが最適であるという思い込みです。
最新モデルは基本的に性能が高くなる一方で、コストも高く、用途によっては性能が必要以上に高すぎることもあります。
例えば、
- 決まった文章の生成や、書式の整形
- 問い合わせ内容を種類ごとに仕分けする作業
- 決まった形式でのFAQ回答の作成
のような業務であれば、軽いモデルでも十分な品質を出せます。
一方、契約書の内容を細かくチェックし、問題になりそうな点を見つける業務や、何段階も考える必要がある業務では、高性能モデルを活用するのが良いでしょう。
「用途の複雑さに合わせてモデルを選ぶ」という視点で、軽いモデルと高性能モデルを使い分けることが、コストと品質を両立させることにつながります。
ローカルLLMは運用コストも考える
ローカルLLMはAPIの利用料がかからない点で魅力的に見えますが、実際に導入・運用するにはさまざまな関連費用がかかります。
ローカルLLMの運用でかかる主な費用は以下のとおりです。
| 費用の項目 | 内容 |
|---|---|
| 設備費用 | GPU・サーバー・保存装置(ストレージ)などの機器代 |
| 構築・設定費用 | 環境づくり、モデルの調整、セキュリティ設定にかかるエンジニアの作業時間 |
| 保守・運用費用 | トラブル対応、モデルの更新、見守り体制の維持 |
| 電力・冷却費用 | 大型サーバーを動かすための電気代と、冷やすための空調設備 |
ローカルLLMを動かすには、GPUやサーバーなどの機器を用意する費用がかかり、環境構築やセキュリティ設定、モデルの更新などを行うための人手も必要です。
リベルクラフトでは、機密データを外部に出さずに生成AIを業務へ実装したい企業に向けて、ローカルAI・ローカルLLM・ローカルRAGの導入を支援しています。
セキュリティを重視しながら生成AIの業務活用を進めたい方は、以下からお気軽にご相談ください。
⇨リベルクラフトへの無料相談はこちら
日本語対応と日本語特化は分けて考える
日本語に対応していることと日本語に強いことは別です。
多くの海外LLMは日本語の読み書きに対応していますが、日本語の専門分野や国内ならではの業務文書での精度は、英語に比べて低い場合があります。
日本語対応モデルで特に注意が必要なのは
- 医療・法律・金融など専門用語が多い業界の文書処理
- 行政文書や国内ならではの書式(稟議書・作業指示書など)
- 日本語の細かい言い回しや敬語が問われるお客様対応
のような場面であり、このような用途では、日本語に特化したモデルを使ったり、専門用語を含むデータで追加学習をしたりすることが効果的です。
また、RAGを使って自社の日本語文書を検索の対象に取り込み、海外LLMの精度を補う方法もあります。
単に日本語で回答できるかではなく、業務で求められる日本語の理解の深さまで見ておくことが大切です。
まとめ
ここまで、LLMモデルの基礎知識や選定ポイントなどさまざまな観点で解説しました。
モデルの選択肢が増えた分だけ可能性は広がっていますが、「自社の業務で安定して使えるか」「コストや運用体制に合っているか」という視点なしに選ぶと、導入後に思ったような成果が得られないケースは少なくありません。
また、適切なモデルを選んで終わりではなくRAGの構築・セキュリティ設計・精度検証・継続的な改善と、実際に業務で成果を出すまでには専門的なノウハウが求められます。
そこでリベルクラフトへご相談ください。
リベルクラフトでは、LLMモデルの選定から構築・運用まで一貫してサポートしています。
業務要件の整理・最適なモデルの選定・RAGや社内システムとの連携設計・精度検証と継続改善まで、現場で成果が出る仕組みを提供。
「どのLLMを選べばよいかわからない」「構築したが社内で使われていない」という状況から抜け出したい企業は、まずは以下のリンクからお気軽にご相談ください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



