生成AI活用事例30選|社内ナレッジを生かす使い方をデータ種別で整理

「生成AIの活用事例は集めているが、自社の業務にどう当てはまるのか像が結ばない」という方も多いでしょう。社名つきの華やかな事例ほど、「だから自社では何ができるのか」が見えにくくなります。
事例集を眺めるだけでは、自社の導入にはなかなかつながりません。業界や規模が違えば、課題も使えるデータも変わるからです。大切なのは、それぞれの事例を「どんなデータ(ナレッジ)を、どう設計して、どんな効果につなげたのか」という骨組みで読むことです。
そこで本記事では、社内ナレッジを生かした生成AIの活用事例を30件、
- 文書・音声・画像・数値という「データ種別」ごとに整理
- 各事例を「データ→アプローチ→効果」で構造化
- あえて生成AIを使わない選択や、失敗からの学びまで
という形で解説します。「自社のどのデータから着手できるか」を持ち帰りたいAI・DX推進担当の方は、ぜひ最後までご覧ください。
自社のナレッジでAIをどう活用するか相談したいという方は、リベルクラフトへご相談ください。
⇨リベルクラフトへの無料相談はこちら
生成AI活用事例を読む前に|「汎用AI×自社ナレッジ」で差がつく理由
生成AIの活用事例を読む前に、なぜ「ナレッジ(社内の知識資産)」が鍵になるのかを押さえておくと、以降の事例が自社ごとに読めるようになります。
生成AIの導入そのものは、もう珍しいことではありません。総務省「令和7年版 情報通信白書」によると、国内企業の生成AI利用率は55.2%に達しています。一方で、活用方針を定めている企業は42.7%にとどまり、導入時の懸念として最も多く挙げられたのは「効果的な活用方法がわからない」でした。つまり、「入れたが活かしきれていない」状態の企業が相当数あるということです。
参照:令和7年版 情報通信白書 企業におけるAI利用の現状|総務省
この傾向は海外調査でも共通しています。McKinseyの「The state of AI 2025」では、72%の組織が1つ以上の業務で生成AIを導入済みと回答していますが、全社規模でスケールできていると答えた組織は3分の1程度にとどまります。導入と、成果が出る活用との間には、まだ大きな開きがあります。
参照:The state of AI 2025|McKinsey
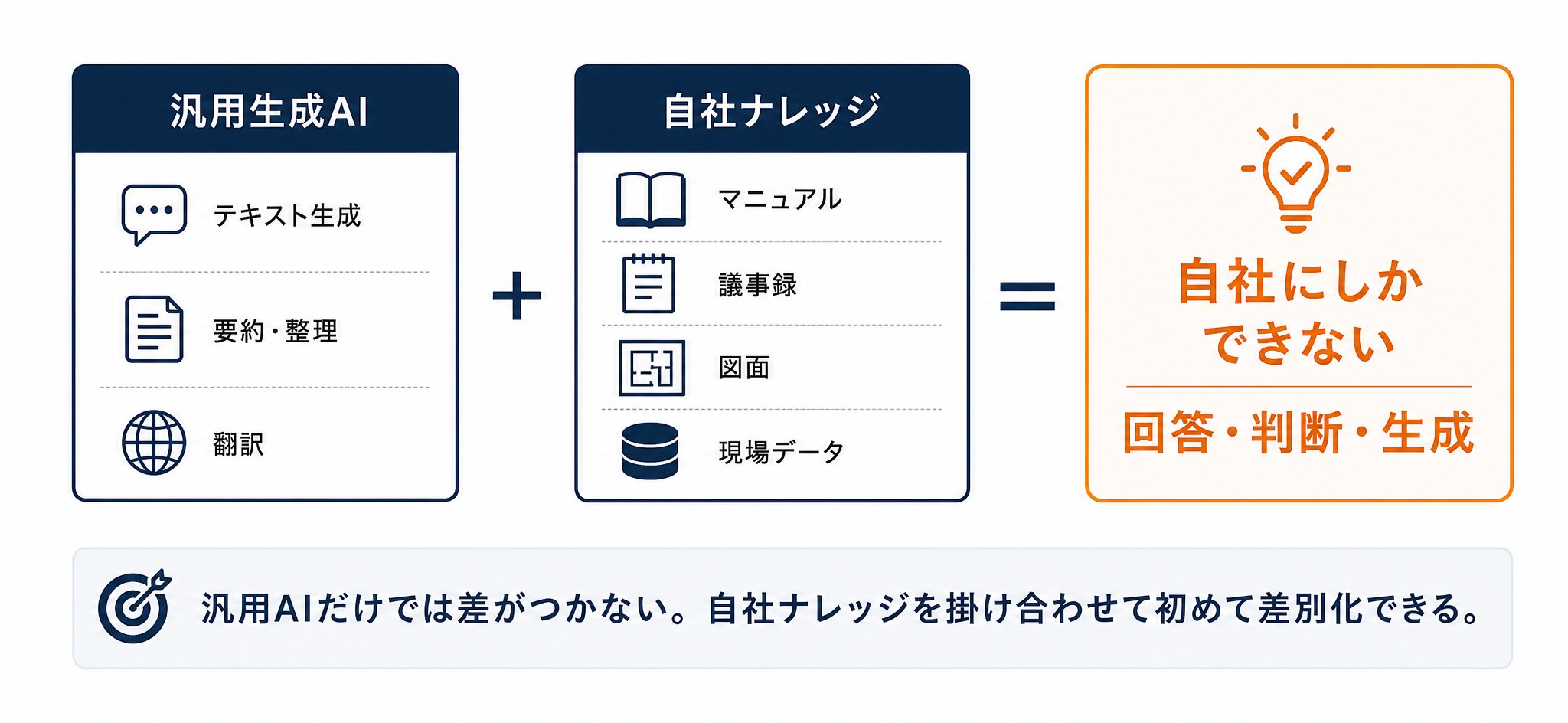
なぜこの差が生まれるのでしょうか。汎用の生成AIは文章生成・要約・翻訳が得意ですが、それだけでは他社と差はつきません。誰が使っても同じ答えしか返せないからです。差がつくのは、汎用AIに自社固有のナレッジ(マニュアル・Q&A・議事録・図面・現場データなど)を掛け合わせたときです。そこで初めて、「その会社にしかできない回答・判断・生成」が成り立ちます。
ここでいうナレッジは、特別なデータベースに限りません。次のように、すでに社内にあるデータがすべて対象です。
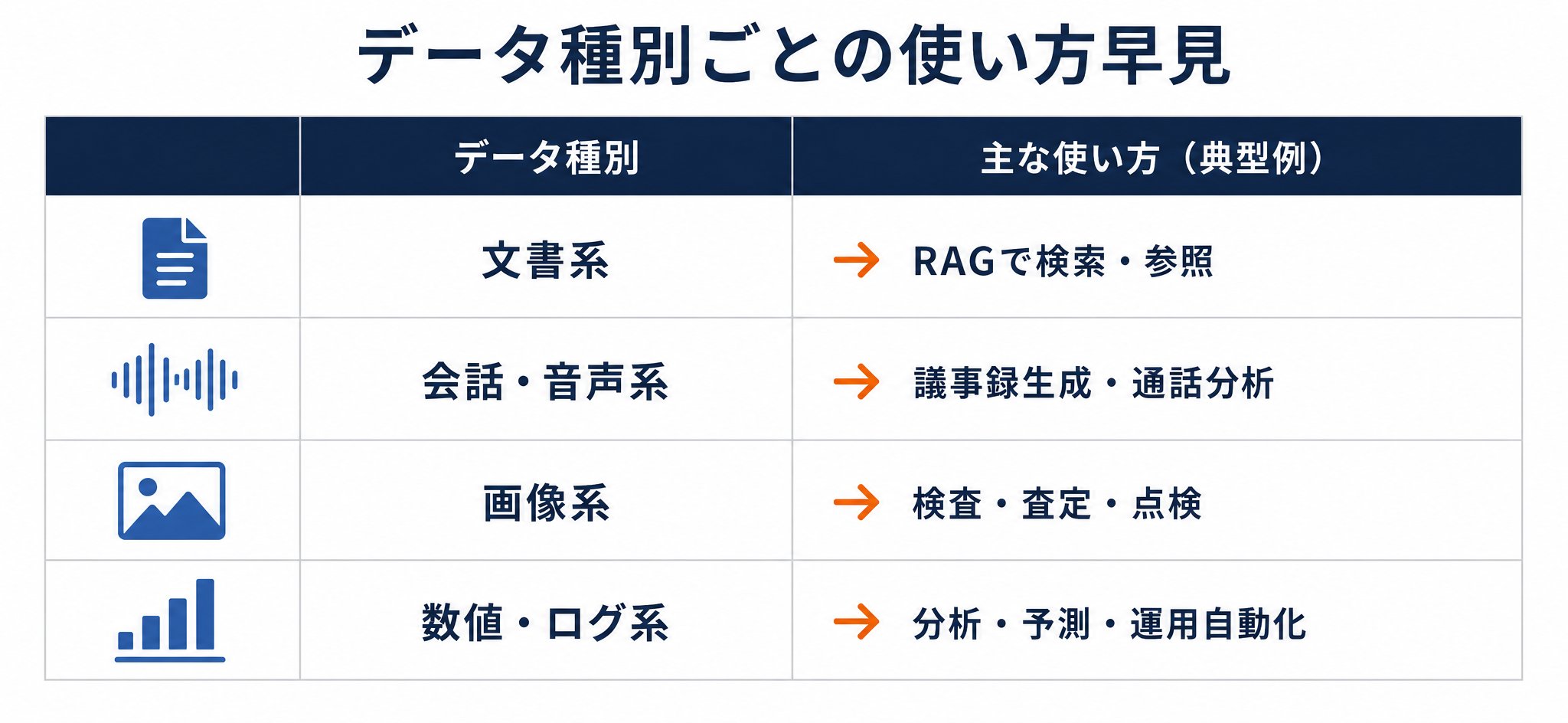
| データ種別 | 具体例 | 代表的な使い方 |
|---|---|---|
| 文書系 | マニュアル・規程・報告書・設計仕様書・FAQ・PDF・紙のスキャン | RAGで検索・参照 |
| 会話・音声系 | 商談の録音・会議の議事録・コールセンターの通話ログ | 議事録生成・通話分析 |
| 画像系 | 製品の検査画像・現場の写真・図面 | 検査・査定・点検 |
| 数値・ログ系 | 販売実績・取引履歴・設備ログ・行動履歴 | 分析・予測・運用自動化 |
この表のどこかに、自社で眠っているデータが当てはまるのではないでしょうか。多くの企業は「うちのデータはPDFや紙ばかりで使えない」「形式がバラバラで整っていない」と考えています。しかし近年の生成AIは、PDFや手書きのスキャン、画像、音声といった非構造のデータも扱えるようになりました。事例を読むときに大事なのは、「自社のデータは特殊だから使えない」という思い込みをいったん外すことです。
以降では、この4つのデータ種別を軸に30事例を整理します。業界別の網羅的な一覧は別途まとめています。本記事は「自社のどのデータが、どう生きるか」という角度で読み解いていきます。
参照記事:業界別のAI活用事例10選
文書・マニュアルを生かす生成AI活用事例|検索・RAG系
前提を押さえたところで、最も着手しやすく効果も出やすい、文書系の活用から見ていきます。社内に大量にある文書を生成AIで検索・参照する使い方で、一般に「RAG(検索拡張生成)」と呼ばれます。ここでは代表的な9つの事例を取り上げます。
PDFのまま検索して調査時間を90%削減(航空・規程文書)
課題:航空法規や業務マニュアルが大量にあり、必要な記述を探すだけで時間がかかる。
データ:PDFのままの規程・手順書。整形せずに取り込みます。
アプローチ:RAGで自然言語の質問から該当箇所を検索し、出典つきで回答させます。
効果:必要な情報にたどり着くまでの調査時間を大幅に削減(事例では約90%)。文書を整形し直さなくても着手できる点が、最初の一歩として現実的です。
部門横断のRAGで調査工数を34%削減(自動車)
部門ごとに散らばった文書を横断して検索できるRAGを構築した事例です。ここで肝になるのは、誰がどの文書を見てよいかという権限管理の設計です。横断検索は便利な反面、見えてはいけない情報まで返してしまうと事故になります。権限を正しく設計したうえで、調査工数を約34%削減しています。
業界特化型のRAGで専門業務を高速化(建設)
汎用のマネージドRAG(既製のクラウドサービス)では、専門用語や独特の文書構造をうまく扱えないことがあります。建設業務のように専門性が高い領域では、その業界の文書構造に合わせてデータ設計をやり直すことで、検索精度を引き上げています。
ナレッジグラフを使って関係性を構造化(製造)
部品の依存関係のように「要素どうしのつながり」が重要な情報は、単純な文書検索だけでは精度が出にくい領域です。そこで、関係性をグラフ構造(ナレッジグラフ)で表現し、RAGと組み合わせて回答精度を上げる設計が使われます。「どのデータを、どんな形で持つか」が精度を左右する典型例です。
Q&Aの蓄積で電話照会を45%削減(コールセンター)
過去のQ&A記録を生成AIに参照させ、問い合わせ対応を高速化した事例です。Q&Aは「質問と答え」がセットになっているため、生成AIが参照しやすい構造です。すでにQ&Aが溜まっている企業ほど、低コストで成果につながりやすい領域といえます。コールセンター領域の詳しい進め方は別記事で解説しています。
参照記事:コールセンターにおける生成AIの活用
商談・議事録から提案書を自動ドラフト(営業)
商談の音声から議事録を作り、さらに提案書のドラフトまで一気通貫で生成するワークフローです。営業領域での生成AIの活用は多くの企業で進んでおり、詳細は別記事で扱っています。
参照記事:営業における生成AIの活用法
設計仕様書の検証を97%短縮(製造)
過去のレポートや設計図を相互にクロスチェックし、矛盾を自動で抽出する使い方です。「Aの仕様書とBの図面で数値が食い違っている」といった検出を自動化します。検証にかかる時間を約97%短縮した事例で、ここでは論理的なRAGロジックの組み方が成果を分けます。
市場調査レポートを自動生成(リサーチ)
生成AIのディープリサーチ機能を使い、市場調査レポートの作成を半自動化する取り組みです。情報収集と一次ドラフトをAIが担い、人は方向づけと最終判断に集中します。
FAQと生成AIの統合で年6,500時間の削減を目標(カスタマーサポート)
既存のFAQと生成AIを統合し、問い合わせ対応の総工数を大きく削減する取り組みです。事例では年間6,500時間規模の削減を目標に掲げています。FAQシステムの構築手順は別記事で詳しく解説しています。
参照記事:生成AIを用いたFAQシステムの構築方法
この文書・RAG系は、RAGに絞った事例集としても掘り下げています。文書系は着手しやすい一方で、成果を分けるのは権限管理とデータ設計です。自社にどんな文書資産があるかを洗い出すところから始めると、最初の一歩が見つかります。
参照記事:RAGの活用事例17選
商談・議事録の音声を生かす生成AI活用事例|記録・生成系
文書の次に着手余地が大きいのが、会議や商談の音声です。これまで「録っても活用しきれていない」典型的なナレッジでしたが、生成AIの登場で一気に使えるデータに変わっています。
議事録RAGで作成時間を83%削減(社内会議)
会議の音声をテキスト化し、要点とネクストアクションを構造化してナレッジ基盤に登録する使い方です。最近はマネージドツール(既製の文字起こし・要約サービス)の活用が効率的になっており、議事録作成の時間を約83%削減した事例があります。
アフターコールワーク(ACW)を30%削減(コールセンター)
コールセンターでは、通話後の記録作業(ACW)が大きな負担です。通話内容を生成AIが自動で要約・入力し、さらにオペレーターへのリアルタイム支援も行うことで、後処理の時間を約30%削減しています。
マーケ業務の9時間を30分に短縮(マーケティング)
データの取得・集計・レポート化といった定型のマーケ業務を、生成AIを組み込んだワークフローで自動化した事例です。9時間かかっていた作業が30分に短縮されました。マーケティング領域での進め方は別記事で扱っています。
参照記事:マーケティングにおける生成AIの活用
音声・会話系のナレッジは、「録音はあるが活用していない」状態の企業が多く、着手の余地が大きい領域です。文字起こしの精度と、要点抽出のプロンプト設計が成果を左右します。すでに録音が溜まっているなら、まず議事録の自動化から試すと効果を実感しやすいでしょう。
画像・現場データを生かす生成AI活用事例|認識・評価系
文書・音声に続いて、現場で撮影される画像も重要なナレッジです。ここでは画像・現場データを生かした5つの事例を見ていきます。

写真撮影だけで出品情報を自動生成(フリマ)
商品写真と過去の大量の出品データから、タイトル・説明文・カテゴリーを自動生成する使い方です。出品のたびに文章を考える手間がなくなり、ユーザーの出品負荷が大幅に下がります。蓄積した過去データが、そのまま生成の精度を支えています。
画像AIで保険金支払いを半分に短縮(保険)
事故車の写真や過去の修理見積もりデータを学習させ、修理コストや損害区分を推定する自動査定の事例です。定量的な見積りを素早く出すことで、保険金支払いまでの期間を短縮しています。ここではAIが査定案を出し、担当者が最終確認する「ヒューマンインザループ」(人が間に入って確認する設計)で誤りを抑えています。
製造業の画像AIで品質検査を自動化(製造)
製造ラインの製品画像から不良パターンを検知し、品質管理を自動化する使い方です。目視検査につきものの見逃しや判定のばらつきを抑えられます。日本の製造現場は良品が多く不良品サンプルが少ないため、「不良データをどう集めるか」が精度を左右します。製造業全体の進め方は別記事で解説しています。
参照記事:製造業における生成AIの活用法
接客AIの評価で笑顔率を1.6倍に(小売・サービス)
現場の端末で、声のトーンや表情をリアルタイムに解析し、接客マニュアルに沿ったレベルをスコアリングする試みです。数値化することで改善ポイントが明確になり、笑顔率が約1.6倍に向上した事例があります。
ドローン×AIでインフラ点検を高速化(インフラ)
ドローンで撮影した画像と過去のデータを比較し、設備の保守優先度を判定する使い方です。広範囲の点検を効率化し、危険な箇所を優先的に把握できます。
画像・現場データは「整っていないから使えない」と思われがちですが、近年のマルチモーダルAI(文章・画像・音声を同時に扱えるAI)の進化で、現場の写真がそのまま判断材料になりつつあります。
自社にある写真や図面でAIが使えるか相談したい方は、リベルクラフトの無料相談をご利用ください。データ整備の要件定義からPoCまで一貫して支援しています。
⇨リベルクラフトへの無料相談はこちら
営業・行動データを生かす生成AI活用事例|分析・レコメンド系
画像の次は、顧客の行動履歴や営業の会話データです。うまく使えば「勝ちパターンの再現」につながる強力なナレッジになります。ここでは6つの事例を見ていきます。
営業通話のAI分析で成約率130%(営業)
商談の音声をAIで分析し、話す速度・トーン・沈黙時間などを定量化する使い方です。ベテランの「勝ちパターン」を抽出し、組織全体の成約率を引き上げています。
営業AI訓練で教育期間を3分の1に(営業)
分析で見えた勝ちパターンを、新人教育のロールプレイに組み込んだ事例です。AIが相手役と評価役を兼ねることで、教育期間を3分の1に短縮しています。
仮想データ分析組織で経営分析を数時間に(エネルギー)
データの取得・分析・可視化を担うAIエージェントを構築し、アナリストのボトルネックを解消した事例です。これまで数日かかっていた経営分析が、数時間で回るようになりました。
LLMとkNNで30億商品を再分類(EC)
過去の商品名やカテゴリー情報を機械学習でクラスタリングし、膨大な商品ラベルの付け直しを自動化する使い方です。30億規模の商品分類を生成AIと近傍探索(kNN=似たデータを探す手法)で処理しています。
LLMレコメンドの根拠を自然言語で提示(金融)
行動履歴や属性に基づくレコメンドに、「なぜこれを薦めるのか」という根拠を自然言語で添える使い方です。推薦の納得感が高まり、金融サービスのような説明責任が求められる領域で効果を発揮します。
AIで顧客分類とコピー生成を統合(広告)
顧客の属性・行動データをもとに、ターゲティングと広告クリエイティブの生成を一気通貫で行う事例です。「誰に」と「何を見せるか」をAIがまとめて設計します。
これらは、行動ログという「すでにあるデータ」を生かす事例です。データサイエンス全般の活用例も別記事で紹介しています。自社にCRMや購買履歴が溜まっているなら、まず分析の自動化から着手すると成果が見えやすいでしょう。
参照記事:データサイエンスの活用事例25選
数値・ログを生かす生成AI活用事例|データ分析・運用自動化系
行動ログの次は、現場担当者が自分でデータを動かせるようにする使い方と、システム運用を自律化する使い方です。
現場が自分でデータを動かせる組織に(製造・テキストto SQL)
現場担当者が自然言語で問い合わせると、生成AIがデータベースに対するSQL(データを抽出する命令文)を生成し、抽出・分析・可視化まで行う「テキストto SQL」の事例です。これまでデータ抽出のたびに専門部署に依頼していた状態から、現場が自分で必要なデータを引き出せる状態へ変わります。
異常検知+LLMでネットワーク運用を自律化(通信)
大量のログやトポロジー情報から異常を検知し、生成AI(LLM)が原因の特定と対処方法の提案までを行う高度な事例です。検知だけでなく「次に何をすべきか」まで踏み込むことで、運用の自律化に近づけています。
数値・ログ系は構造化されたデータが多く、生成AIと相性が良い領域です。社内データをAIに使わせる際の整理の仕方や、社内データを使ったRAGの手順は、別記事で詳しく解説しています。
参照記事:社内データ棚卸しの進め方
参照記事:RAGで社内データを活用する5つの手順
あえて生成AIを使わない選択・失敗から学ぶ生成AI活用事例
ここまで成功事例を見てきましたが、「常に生成AIを使えばよい」わけではありません。あえて使わない判断や、失敗からの立て直しも、自社の設計判断に役立ちます。生成AIの導入事例としては地味ですが、ここを押さえておくと無駄な投資を避けられます。
生成AIを使わずに問い合わせを92%削減(自治体)
大量の内部文書に対して、あえて生成AIではなく構造化したデータベースと非AIの検索エンジンを使った事例です。情報の正確性が最優先される自治体では、生成AIのハルシネーション(誤った情報の生成)リスクを避け、確実に正しい情報を返す設計を選びました。結果として問い合わせを約92%削減しています。「生成AIを使わない」という選択も、立派な設計判断です。
FAQ管理を65%削減・30言語対応(グローバル企業)
膨大なFAQを生成AIで整理・統合し、管理工数を約65%削減しつつ30言語対応を実現した事例です。多言語展開は、生成AIが効果を発揮しやすい領域です。
失敗からのV字回復で全社RAG展開(大企業)
最初から全社規模でRAGを導入しようとして失敗し、そこから特定部門に絞って立て直した事例です。一気に広げると、データ整備も権限設計も中途半端になり、現場に使われないまま頓挫しがちです。小さく成功させてから広げる順番が、結果的に全社展開への近道になりました。
データ整備不要で24名が即日活用(中堅企業)
既存のGoogleドライブ上の文書をそのまま活用し、特別なデータ整備をせずに24名が即日使い始めた事例です。「整えてから始める」のではなく「あるものから始める」ことで、立ち上がりを速くしています。
PoC・月額契約で段階的に拡大(共通パターン)
最初に小さくPoC(試験的な導入)を行い、効果を確認してから月額契約で段階的にスコープを広げるパターンです。初期投資を抑えながら、成果が出た領域だけ拡張できます。
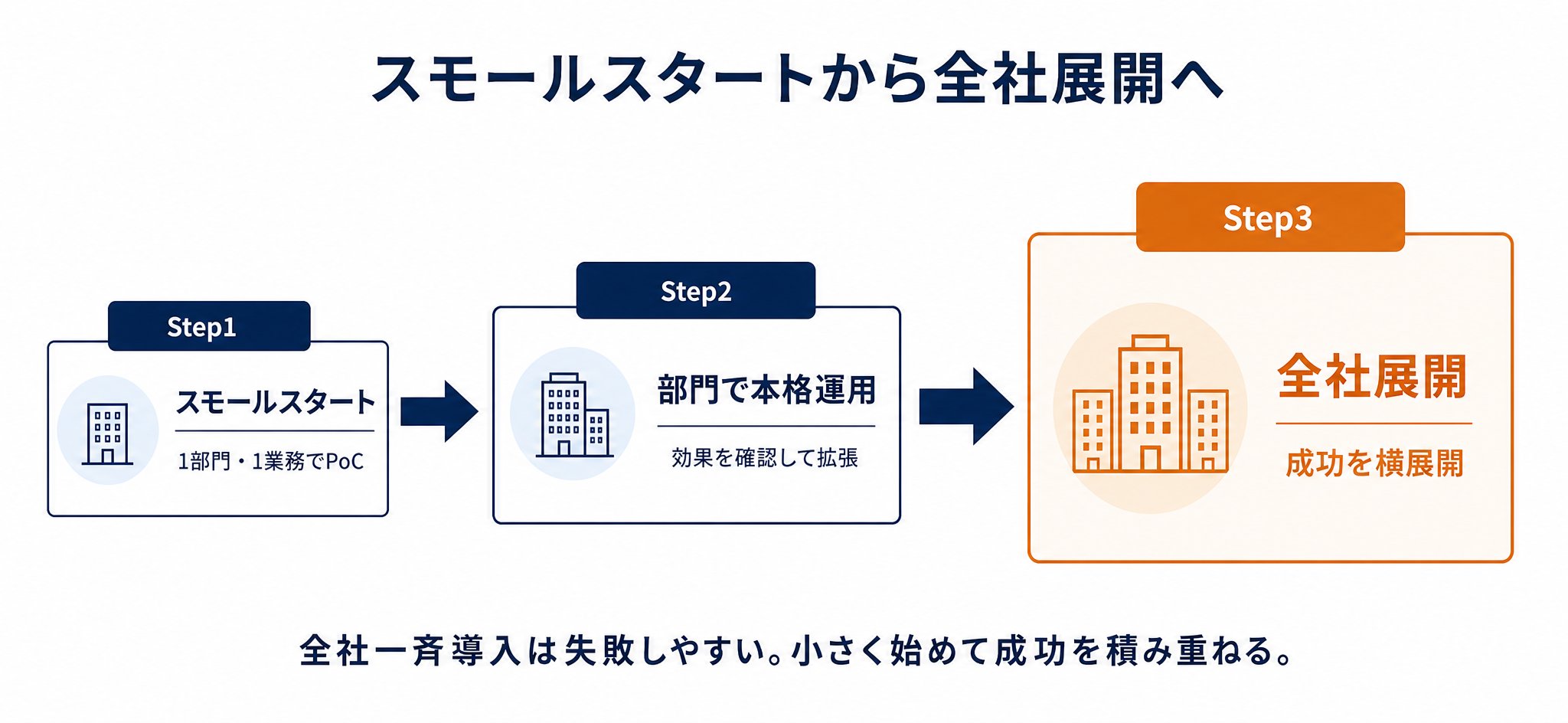
これらの事例に共通するのは、「身の丈に合った範囲から始める」という発想です。先に触れたGartnerの予測では、生成AIプロジェクトの30%超がPoCの後に断念されるとされ、その要因にデータ品質の低さや事業価値の不明確さが挙げられています。大規模導入の失敗を避けるには、特定部門のPoCから始め、成功を積み重ねてから全社へ広げる進め方が現実的です。
参照:Gartner Predicts 30% of Generative AI Projects Will Be Abandoned After Proof of Concept|Gartner
30事例に共通する3つの気づき|思い込みを外す・設計する・小さく始める
30の事例を横断すると、業界もデータ種別もばらばらでも、うまくいく取り組みには共通点が見えてきます。最後に3つに整理します。
| 気づき | 中身 | 自社での問い |
|---|---|---|
| 思い込みを外す | PDF・紙・画像・音声の非構造データも近年の生成AIは扱える | 「整っていないから無理」と諦めているデータはないか |
| 設計が成果を分ける | 権限管理・データ整備・人の介在(HITL)で精度と安全性が決まる | どこまでAIに任せ、どこから人が確認するか |
| 小さく始める | 全社一斉導入は失敗しやすく、特定部門のPoCが定石 | まずどの1部門・1業務から試すか |
1. 「自社データは特殊だから使えない」という思い込みを外す
PDF・紙・画像・音声といった非構造のデータも、近年の生成AIは扱えます。「整っていないから無理」ではなく、「あるものから何ができるか」で考えると着手点が見つかります。
2. 成果を分けるのは設計(権限・データ整備・人の介在)
同じRAGでも、権限管理の設計、データを整える工程、そして「どこまでAIに任せ、どこから人が確認するか」の境界線(ヒューマンインザループ)で精度と安全性が変わります。AIを動かす前のデータ整備にこそ手間がかかる、という点は多くの事例に共通します。
3. 大きく始めず、小さく成功させてから広げる
全社一斉導入は失敗しやすく、特定部門のPoCから始めるのが定石です。効果を確認してから段階的に広げることで、投資のムダと現場の混乱を避けられます。
「なんとなく生成AIを使う」から「自社のナレッジで具体的に成果を出す」へ。この判断の枠組みを持っておくと、自社の検討を一歩前に進められます。
まとめ
本記事では、社内ナレッジを生かした生成AIの活用事例を、データ種別ごとに30件整理しました。要点は次のとおりです。
- 差がつくのは「汎用AI×自社ナレッジ」の掛け合わせ。文書・音声・画像・数値という手元のデータがすべて対象になる
- 文書(RAG)、音声(議事録・通話)、画像(検査・査定)、行動ログ(分析・レコメンド)と、データ種別ごとに使い方の型がある
- 成功の鍵は、「自社データは特殊」という思い込みを外すこと・設計(権限/データ整備/人の介在)・スモールスタートの3点
事例を眺めるだけでなく、自社にすでにあるデータを1つ選び、「このデータで何ができるか」を考えるところから始めてみてください。
ウェビナー資料(ホワイトペーパー)のダウンロード
本記事でご紹介した30事例は、ウェビナーで使用したスライド資料にも図解とあわせてまとめています。各事例を「データ→アプローチ→効果」の骨組みで読み解ける構成で、社内での検討・共有資料としてもお使いいただけます。下記より無料でダウンロードいただけます。
⇨ウェビナー資料のダウンロードはこちら
生成AI・ナレッジ活用の相談は「リベルクラフト」
ここまで30の事例を見てきて、「自社のどのデータから始めればよいか分からない」と感じた方も多いのではないでしょうか。事例の型は分かっても、自社のデータに当てはめて優先順位をつける段階こそ、外部の視点が役に立ちます。
リベルクラフトでは、生成AIの活用方針の策定やデータ整備の要件定義といったコンサルティングから、PoC(試験的な導入)、本格導入までを一気通貫で支援しています。RAGチャットボット・AIエージェントのSaaS「ソクラグ」や、法人向け研修・個人向けスクールも展開しています。
次のようなニーズをお持ちの方に適しています。
- 自社のどのナレッジ(文書・音声・画像・数値)から着手すべきか整理したい
- データ整備の要件定義からPoC、本格導入まで一貫して任せられる相手を探している
- 「入れたけど使われない」状態を避け、現場で使われる運用設計まで支援してほしい
「自社のどのナレッジから始めるべきか」を含め、まずはお気軽にご相談ください。
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



