ローカルAIは何が使えて、どこで詰まるか|得意・苦手と4つの壁を整理

「クラウドのAIは便利だが、機密データを外に出せないのでローカルAIを検討したい」「ローカルAIは実務に耐えるのか、どこで詰まるのかがわからない」という方も多いでしょう。
ローカルAIは無料で使える高性能モデルが増え、現実的な選択肢になってきました。ただし、クラウドAIをそのまま置き換えようとすると、機材や精度の面で思うように動かず、途中で止まってしまうことがあります。大切なのは、何が得意で何が苦手かをタスク単位で見極め、詰まりやすい場所を先に把握しておくことです。
そこで本記事では、
・クラウドAI(借りるAI)とローカルAI(持つAI)の違い
・ローカルAIの得意なタスク・苦手なタスクの見極め方
・機材・速度・精度・運用という「詰まりどころ4系統」と、ローカルRAG・試し方
についてわかりやすく解説します。ローカルAIの導入を検討しているDX担当者・情報システム担当者の方は、ぜひ最後までご覧ください。
「自社の環境に合ったローカルAIをどう設計すればよいか相談したい」という方はリベルクラフトへご相談ください。
⇨リベルクラフトへの無料相談はこちら
ローカルAIとは|クラウドAI(借りるAI)との違いを整理する
ローカルAIを理解する近道は、ふだん使っているクラウドAIとの違いを押さえることです。まずは両者の関係を整理します。
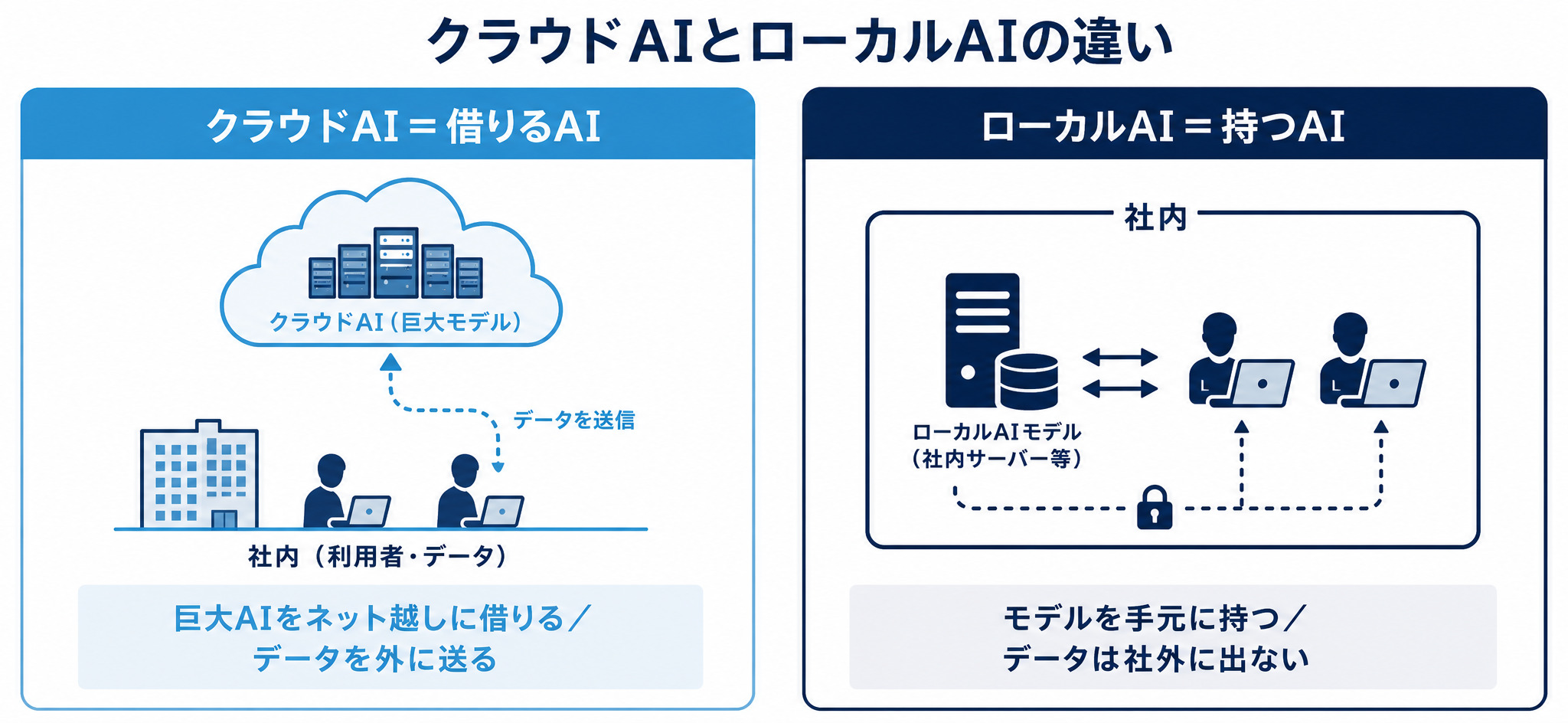
ローカルAIは「自社で持つAI」、クラウドAIは「借りるAI」
クラウドAIとは、提供事業者のデータセンターにあるAIを、インターネット越しに借りて使う形態です。 ChatGPT・Gemini・Copilot・Claude などが代表例で、こちらのデータを送り、返ってきた回答を受け取ります。巨大なAIを月数千円から1万円台で使えるのが強みです。
一方のローカルAIとは、モデルを自社の手元(自分のパソコンや社内サーバー)に持ち、データを社外に出さずに動かす形態です。 性能・速度・更新のすべてが自社の機材と運用に依存します。良くも悪くも自分たち次第という点が、借りるクラウドAIとの決定的な違いです。
この違いから、通信が制限される現場や、データを外部に出せない業務で、ローカルAIが代替手段として選ばれます。AIそのものでできることの全体像は、AIで何ができるかを解説した記事もあわせてご覧ください。
ローカルAIが現実的な選択肢になった3つの理由
数年前まで、ローカルAIは一部の技術者のものでした。それが2025年から2026年にかけて、業務で使える水準に近づいてきています。背景には次の3つがあります。
- 高性能なオープンソースモデルが無料で公開されている:誰でもダウンロードして試せるモデルが増えました。
- モデルを軽く小さくする技術が普及した:手ごろなGPUでも動かせるようになりました。
- 扱いやすいツール・ライブラリが増えた:専門家でなくても動かし始められます。
導入前に外したいローカルAIの3つの誤解
期待だけで進めると、後で「思っていたのと違う」となりがちです。先に3つの誤解をほどいておきます。
- 「ChatGPTと同じものが作れる」→ 基本は作れません:クラウドの大規模モデルよりコンパクトになるため、複雑なタスクでは性能差が出ます。ベンチマークで肉薄する発表もありますが、差が出る場面があると理解しておくのが安全です。
- 「動けばOK」→ 検証が必要です:ダウンロードして起動できても、速度や精度が実務に乗らないことがあります。動くことと使えることは別です。
- 「モデルが無料ならコストもタダ」→ タダではありません:モデル自体は無料でも、GPUサーバー・電力・運用の人手といったコストがかかります。
ローカルAIで使えるモデルと選び方|Qwen3・Gemma・Phi とパラメータ数
「持つAI」である以上、どのモデルを手元に置くかは自分で選びます。ここでは代表的なモデルと、選ぶときの基準を整理します。
高性能モデルを無料で使える(Qwen3・Gemma・Phi など)
ローカルAIが現実的になった最大の理由は、高性能なモデルを無料で使えるようになったことです。実務でよく使われるのは次のようなモデルです。
- Alibaba の Qwen3(クウェン3):精度が高く、サイズの選択肢も豊富です。
- Google の Gemma(ジェンマ):小型でも扱いやすく、用途を選びません。
- Microsoft の Phi(ファイ):非常に小さく、小型端末で動かしやすいモデルです。
- 日本語を強化したモデル:日本語の業務文書を扱う場面で選択肢になります。
多くが商用利用可能なライセンスで公開されているため、業務での利用も進めやすい状況です。ライセンス条件は Qwen(qwenlm.github.io)・Gemma(ai.google.dev/gemma)・Phi(Microsoft Phi)の公式情報で確認できます。
モデルサイズ(パラメータ数)で賢さと必要な機材が変わる
同じ Gemma や Qwen3 でも、モデルには複数のサイズがあります。この差を決めるのがパラメータ数です。パラメータ数とは、モデル内部の数値の多さで、賢さのおおよその目安になります。
- パラメータ数が小さいモデル:軽くて速いですが、精度は控えめです。要約や仕分けなど基本的なタスク向きです。
- パラメータ数が大きいモデル:高度なタスクを解けますが、動かすのに重い機材が必要です。
賢さと必要な機材の重さは、おおむね比例します。ChatGPT や Claude で「軽い・標準・高性能」を選ぶ感覚に近く、やりたいタスクの難しさに合わせてサイズを選ぶのが基本です。おすすめのモデルを比較する前に、まず「どのタスクをどのサイズで解くか」を決めると迷いません。
ローカルAIの得意・苦手|任せられるタスクを見極める
モデルを選べても、任せる仕事を間違えると失敗します。次に、ローカルAIができること・苦手なことを、タスク単位で見ていきます。
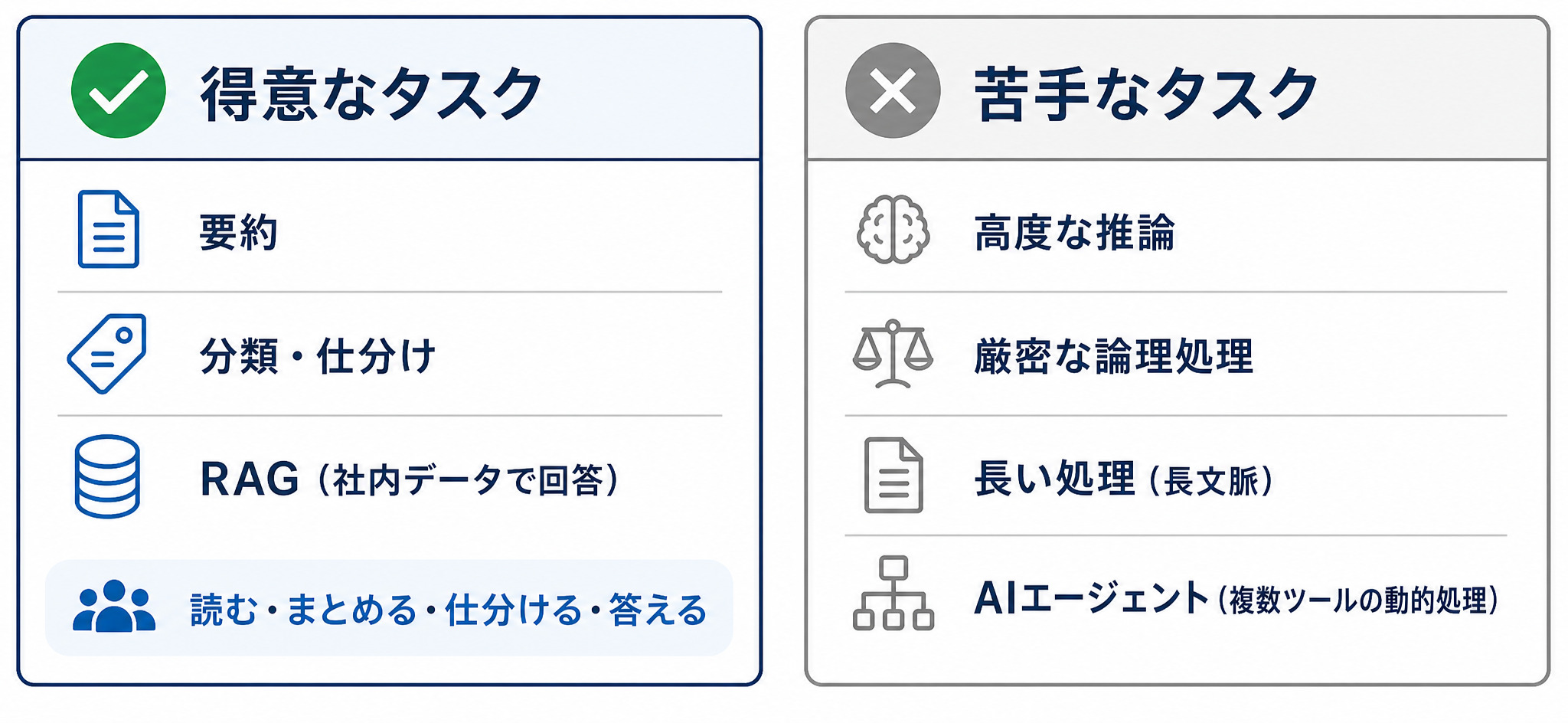
得意なのは「読む・まとめる・仕分ける・答える」
インストールして動かすだけなら気軽ですが、業務に乗せられるかは中身次第です。ローカルAIが実用水準に達しているのは、比較的シンプルなタスクです。
- 要約:長い文書を短くまとめます。
- 分類・仕分け:問い合わせや文書をカテゴリー分けします。
- RAG(検索拡張生成):社内の資料を参照し、根拠のある回答を作ります。
RAGとは、社内ナレッジを検索してAIに渡し、その情報をもとに回答を生成する仕組みです。 参照する社内データが整っていれば、ローカルAI自体が難しい推論をできなくても、根拠に基づいた回答を返せます。「読む・まとめる・仕分ける・答える」という業務は、製造業や官公庁など機密性の高い現場に多く、ローカルAIの実用水準に達してきた領域です。
苦手なのは高度な推論・厳密な論理・AIエージェント
一方で、はっきり差が出るタスクもあります。
- 高度な推論・厳密な論理処理:込み入った条件を厳密にたどる処理は苦手です。
- 長い処理(長文脈):一度に扱える情報量(コンテキストウィンドウ)はクラウドが有利です。
- AIエージェント(エージェンティックな処理):複数のツールを状況に応じて使い分ける動的な処理は、差が出やすい領域です。
エージェンティックな処理の詳しい考え方は、エージェンティックRAGを解説した記事で扱っています。大切なのは、性能そのものを比べるより「その用途で、その差を許容できるか」で考えることです。
「使えない」で終わらせず、業務を分解してローカルに寄せる
苦手なタスクを丸ごと任せて「使えない」と結論づけるのは早計です。業務フローを細かいタスクに分解すると、その一部はローカルAIで十分に解けることが多いからです。
例えば、ひとつの業務をタスクA・B・C・Dに分けると、AとBは要約や仕分けで、ローカルAIに寄せられます。クラウドをまるごとローカルに置き換えるのではなく、適合するタスクだけをローカルに寄せる。この発想が、ローカルAIを機能させる分かれ目です。
具体例として、通信が不安定で機密性も高い航空領域の現場や、患者情報を扱うある医療機関では、オフラインで完結する小型モデルの端末が使われます。タブレットや小型パソコンで動く小型モデル(Phi のような非常に小さいモデルなど)に用途を絞り、引き継ぎレポートの作成といった仕事に集中させます。用途を絞る → 機材の制約を確認する → 使えるモデルサイズが決まる、という順で考えると、限られた環境でも機能させられます。
ローカルAIはどこで詰まるか|機材・速度・精度・運用の4系統
任せる仕事を決めたら、次は実装です。ここで現実的に詰まりやすいのが、機材・速度・精度・運用の4つです。順に整理します。
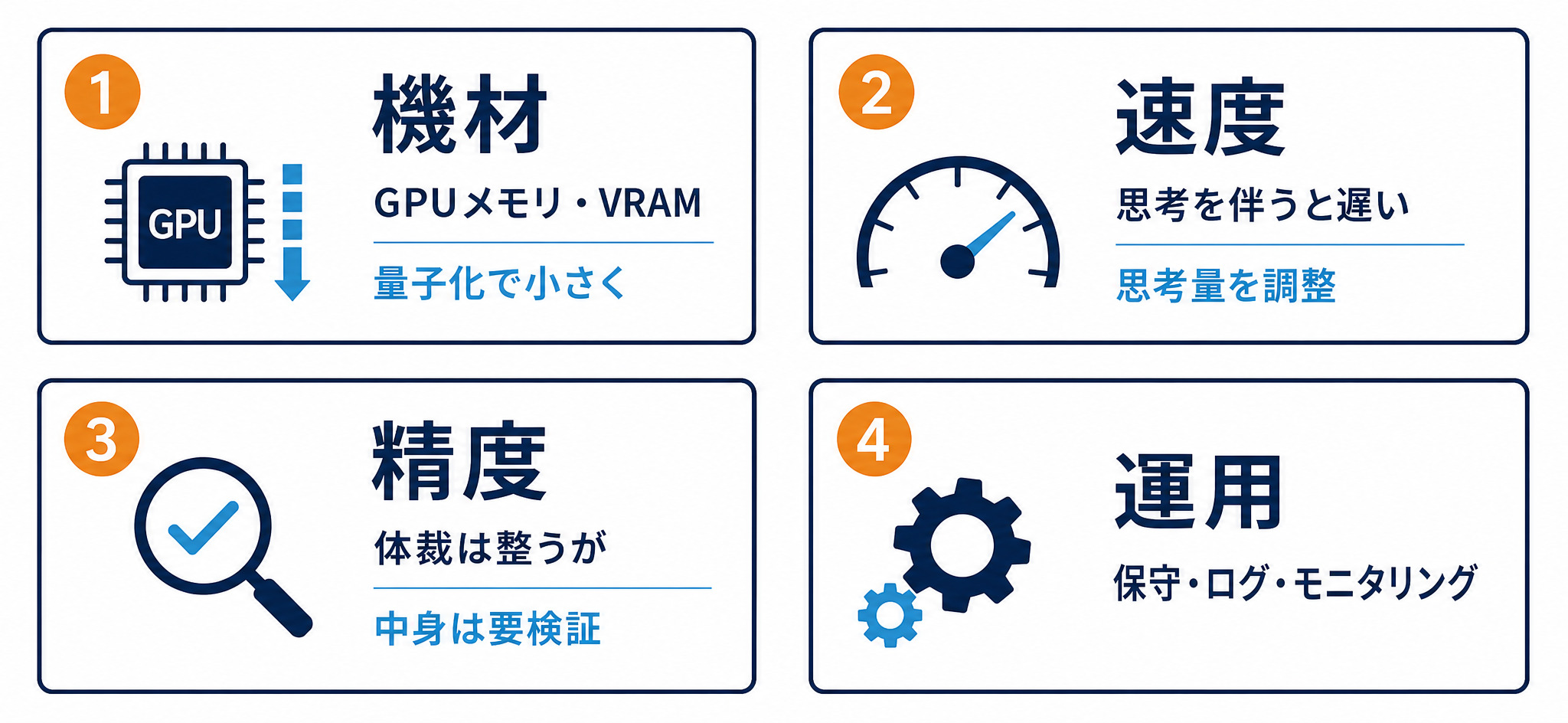
①機材(GPUメモリ・VRAM)と量子化
ローカルAIを動かすには、GPUのメモリ(VRAM)が要ります。VRAMとは、GPUが計算に使う専用メモリで、モデルサイズに応じて必要量が変わります。
- 小さいモデルは6〜10GB程度で動き、最近のパソコンでも手元で試せます。
- 70B級の大型モデルは40GB前後など、それなりの機材が必要です。
ここで役立つのが量子化(クオンタイゼーション)です。量子化とは、モデル内部のパラメータ(数値)をあえて荒くし、モデルを物理的に小さくする技術です。 サイズが小さくなる割に精度の低下はわずかで済むため、量子化した小型モデルを使うケースは多くあります。
②速度(思考を伴う処理で遅くなる)
ローカルAIは基本的に速いのですが、思考(シンキング)を伴う処理を挟むと一気に遅くなります。逆に、思考をオフにしてシンプルなタスクを解かせると速く動きます。思考量をチューニングすることで、実務に耐える速度に調整できるという点は押さえておきたいところです。
③精度(体裁は整うが中身は検証が要る)
ローカルAIの回答は、日本語としての自然さや形式は整いますが、中身の正しさにギャップが残ることがあります。回答がそれらしく見えても鵜呑みにはできません。人による検証を前提に運用する必要があります。これはクラウドAIでも同じで、ローカル固有の弱点というわけではありません。
④運用(入れて終わりではない・保守とモニタリング)
クラウドAIは提供事業者が保守してくれますが、ローカルAIは自社で運用します。入れて終わりではなく、次のような継続的な作業が発生します。
- 性能の再検証と再設定
- ログ管理・ストレージの運用
- 利用状況やメモリ使用率のモニタリング
ひとつ安心できるのは、モデルの更新頻度がそれほど激しくない点です。クラウドのように頻繁に世代交代しないため、追随に追われすぎることはありません。
ここまで、ローカルAIの得意・苦手と、実装で詰まりやすい4系統を解説しましたが、「機材・速度・精度・運用の4つを、自社の環境だけでさばききれるか自信がない」という方は、リベルクラフトへご相談ください。
リベルクラフトでは、GPUやVRAMの機材選定からモデル選定、速度と精度の検証設計まで、ローカルAIを実務に乗せる支援が可能です。ただ動かすだけでなく、社内データを生かすローカルRAGの作り込みまで踏み込めるため、自社業務に特化したAI活用が実現できます。
以下のリンクからまずは詳細をチェックしてみてください。
⇨リベルクラフトへの無料相談はこちら
ローカルRAGで精度を補う|社内データを生かす組み合わせ
精度の壁を越えるうえで、最も有力なのがローカルRAGです。モデル単体の賢さに頼らず、データで精度を引き上げる考え方を整理します。
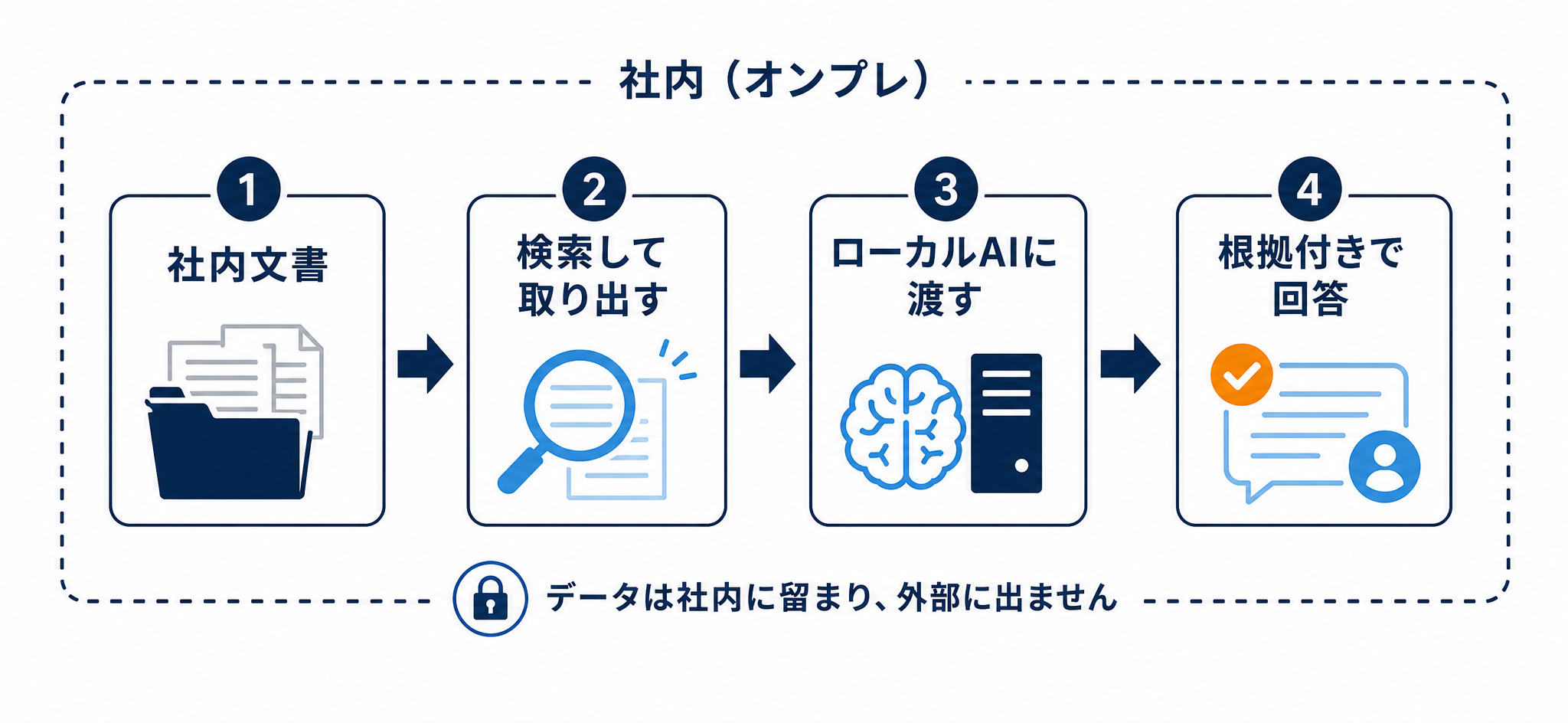
モデル単体が完全でなくても、整えたデータで精度が出る
ローカルRAGとは、社内文書を検索してローカルAIに渡し、その情報をもとに回答させる組み合わせです。モデル単体の性能が完璧でなくても、参照するデータさえ整っていれば、実用的な精度に届きます。 ローカルAIとRAGは相性がよく、機密性を保ちながら根拠のある回答を作れるため、有力なアプローチです。
RAGの本体は「データを集めて整えて入れる」作業
RAGはクラウドでもローカルでも、「データを集めて、整えて、AIに渡せる形にする」という準備作業が本体です。ここをやりきれば、ローカルAIの性能が最上位でなくても成果につながります。逆に、この準備を飛ばすと精度は出ません。
社内データを使ったRAGの具体的な進め方は、ChatGPT×RAGで社内データを活用する手順の記事や、RAGの活用事例をまとめた記事で詳しく解説しています。
ローカルAIの試し方|Ollama・LM Studioでスモールスタート
使いどころが見えてきたら、次は実際に試す段階です。うれしいことに、ローカルAIは無料で手元から始められます。
まず手元パソコンで数B〜10B級を無料で動かす
数B〜10B級の小型モデルなら、手元のパソコンで動かして体感できます。よく使われるツールは次の2つです。
- Ollama(オラマ):コマンドで手軽にモデルを動かせるツールです。
- LM Studio(エルエムスタジオ):画面操作でモデルを試せるツールです。
まずはこの2つで、対象タスクを実際に解かせてみるのが出発点です。ローカル環境の構築全般は、AI開発環境の構築方法を解説した記事も参考になります。
速度・精度の「ゲート」を決めてから進める
やみくもに試すのではなく、判断基準(ゲート)を先に決めておくと迷いません。速度と精度について「ここまでなら実務で使える」という許容ラインを設定し、満たせば進み、満たせなければ用途を絞る・クラウドを併用する・データを整えて出直す、という進め方が有効です。
GPUはモデルサイズに応じて段階的に投資する
最初から高価なGPUをそろえる必要はありません。モデルサイズに応じて、段階的に買い揃えられます。
- 数B〜10B級:手元のパソコンで試せます。
- 20B級:数十万円のGPUで試せます。
- 70B級:相応のGPUボードが必要です。
小さく始めて、手応えを見ながら投資を広げるのが現実的です。
クラウドと二択にしない|ハイブリッドで使い分ける判断軸
試したうえで、すべてをローカルにする必要はありません。セキュリティ上ローカル一択という場合を除けば、クラウドとローカルは適材適所で使い分けられます。
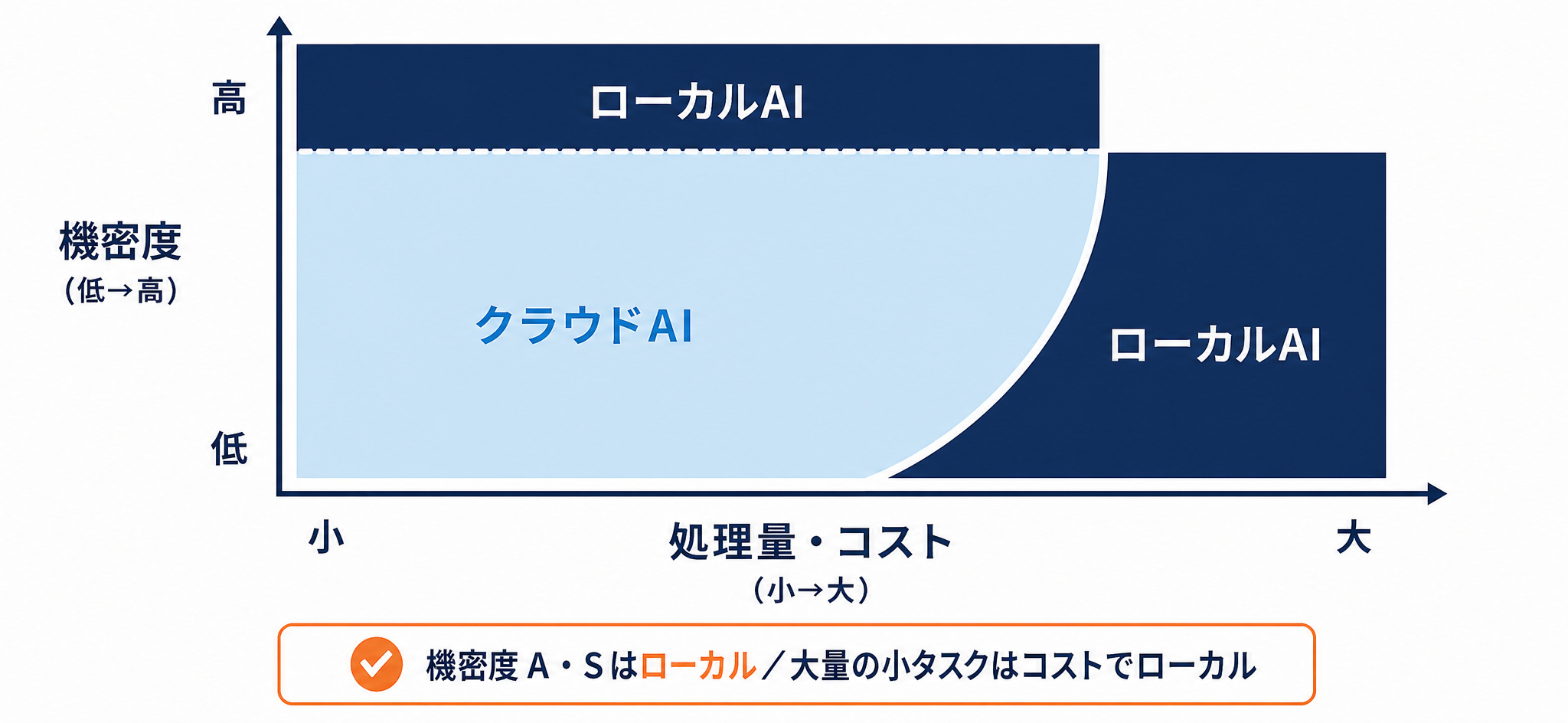
大量の小さいタスクはコストでローカルが効く
ひとつひとつは小さいタスクでも、件数が膨大になるとクラウドの利用料がふくらみます。例えば、顧客の声(VOC)・アンケート・電話ログを大量に処理すると、クラウドのAPI利用料が月200万円から300万円規模になることもあります。こうしたケースでは、ローカルAIで処理したほうがコストを抑えられます。
機密度で振り分ける(機密度A/Sはローカル)
もうひとつの軸が機密度です。社外に出せない機密度の高いデータ(機密度A・Sなど)はローカルで、それ以外はクラウドで、と振り分けると無理がありません。全部をローカルに寄せるのではなく、コストと機密度の2軸で置き場所を決めるのがハイブリッドの考え方です。用途ごとにローカルとクラウドを使い分ける発想は、AIデータ活用の方法を整理した記事の考え方とも共通します。
まとめ
ローカルAIについて、使いどころと詰まりどころを整理しました。
- ローカルAIは「自社で持つAI」、クラウドAIは「借りるAI」。データを外に出さない運用に向きます。
- 得意なのは要約・分類・RAGなどの「読む・まとめる・仕分ける・答える」。高度な推論やAIエージェントは苦手です。
- クラウド丸ごとの置き換えではなく、業務を分解して適合タスクをローカルに寄せると機能します。
- 実装では機材(VRAM・量子化)・速度(思考量)・精度(検証)・運用(保守)の4系統で詰まりやすくなります。
- ローカルRAGを使えば、モデル単体が完全でなくても、整えたデータで精度を補えます。
- まずは Ollama・LM Studio で小さく試し、コストと機密度でクラウドと使い分けるのが現実的です。
ウェビナー資料(ホワイトペーパー)のダウンロード
本記事の内容は、ウェビナー「ローカルAIって何が使えて、どこで詰まるか」をもとにまとめています。得意・苦手の見極め方や詰まりどころ4系統を、資料でも確認いただけます。
⇨ウェビナー資料のダウンロードはこちら
ローカルAI活用の相談は「リベルクラフト」
「ローカルAIを試してみたいが、どのモデルと機材を選べばよいかわからない」「RAGの作り込みまで含めて実務に耐えるか見極めたい」と感じた方も多いのではないでしょうか。
リベルクラフトでは、AI・データ活用の構想・戦略から開発、運用体制の構築や内製化支援までワンストップで伴走します。ローカルAIについても、用途の絞り込み・モデルと機材の選定・速度と精度の検証・ローカルRAGの設計まで、自社に合った形で支援します。次のようなお悩みをお持ちの方に適しています。
- 機密データを外に出せず、社内で完結するAIを検討している
- ローカルAIが自社の業務タスクで実務に耐えるか見極めたい
- クラウドとローカルの使い分けを含めて設計したい
⇨リベルクラフトへの無料相談はこちら
この記事を書いた人
慶應義塾大学で金融工学を専攻。 卒業後はスタートアップのデータサイエンティストとして、AI・データ活用コンサルティング事業などに従事。 その後、株式会社セブン&アイ・ホールディングスにて、小売・物流事業におけるAI・データ活用の推進に貢献。 株式会社リベルクラフトを設立し、AIやデータサイエンスなどデータ活用領域に関する受託開発・コンサルティングや法人向けトレーニング、教育事業を展開。



